
Memory: Cache 블록의 배치 방식
캐시 블록의 배치 방식 (Block Placement)
메인 메모리의 특정 블록이 캐시 내의 어느 위치에 저장될 수 있는지에 따라 캐시의 구조가 결정됩니다.
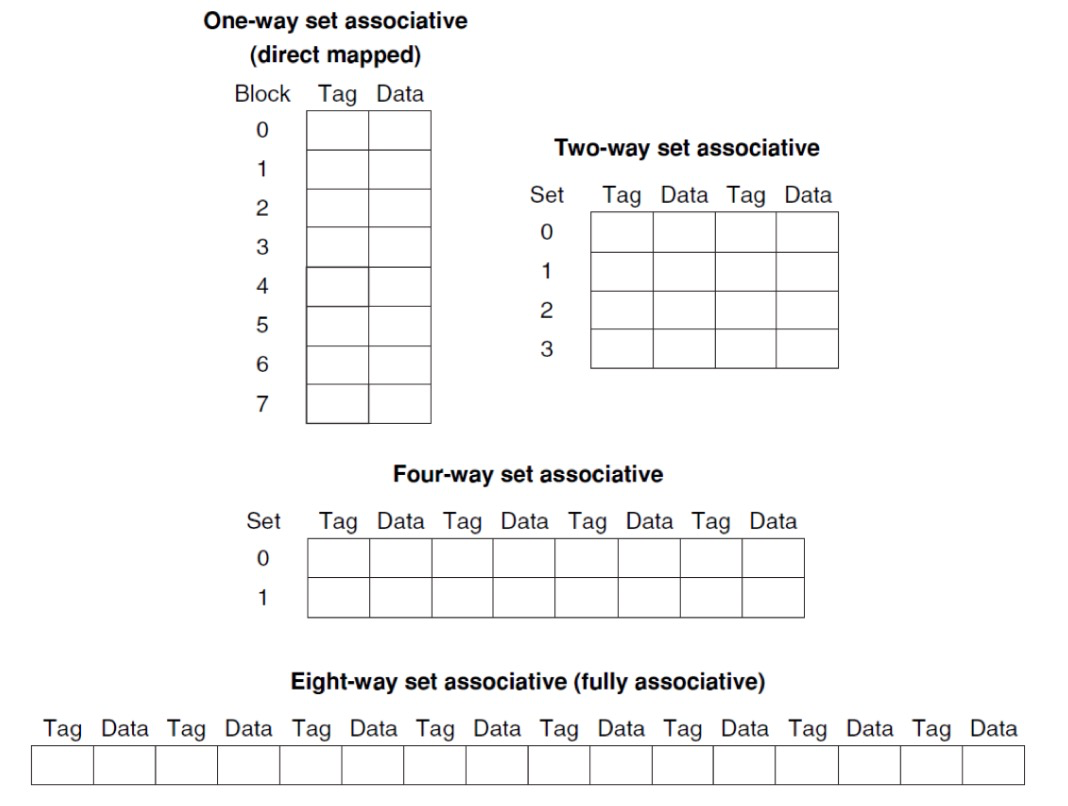
직접 매핑 캐시 (Direct-Mapped Cache):
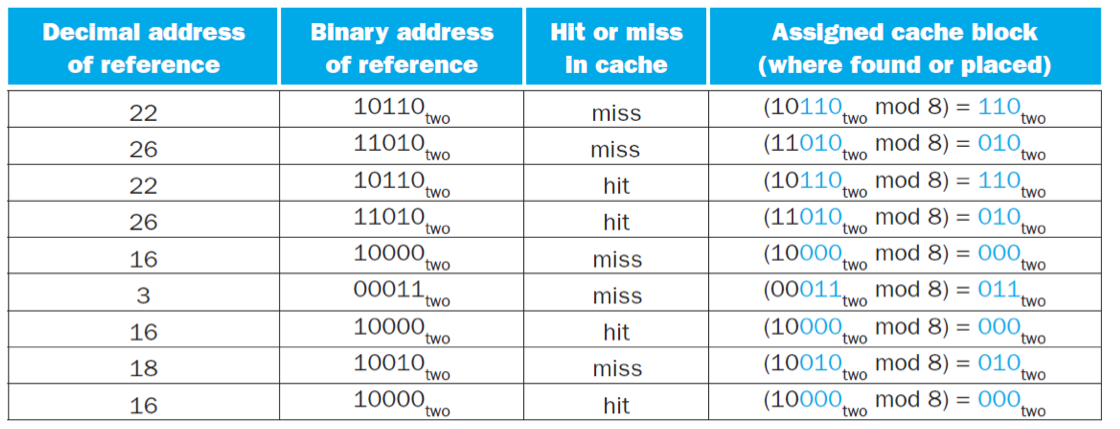
메인 메모리의 각 블록은 캐시 내의 정해진 단 하나의 위치에만 매핑될 수 있습니다. 매핑 위치는
(블록 주소) modulo (캐시 내 블록 수)공식을 통해 결정됩니다.가장 간단한 구조로 구현이 용이하지만, 여러 블록이 동일한 캐시 위치로 매핑될 경우 충돌(Conflict)이 자주 발생하여 성능 저하의 원인(충돌 미스)이 될 수 있습니다.
캐시에서 데이터를 찾을 때, 유효 비트(Valid Bit)와 태그(Tag)를 사용하여 원하는 데이터가 캐시에 있는지 확인합니다. 유효 비트는 엔트리에 유효한 데이터가 있는지, 태그는 실제 메모리 주소의 상위 부분을 저장하여 매핑된 블록이 요청된 블록과 일치하는지 확인합니다.
완전 연관 캐시 (Fully Associative Cache):
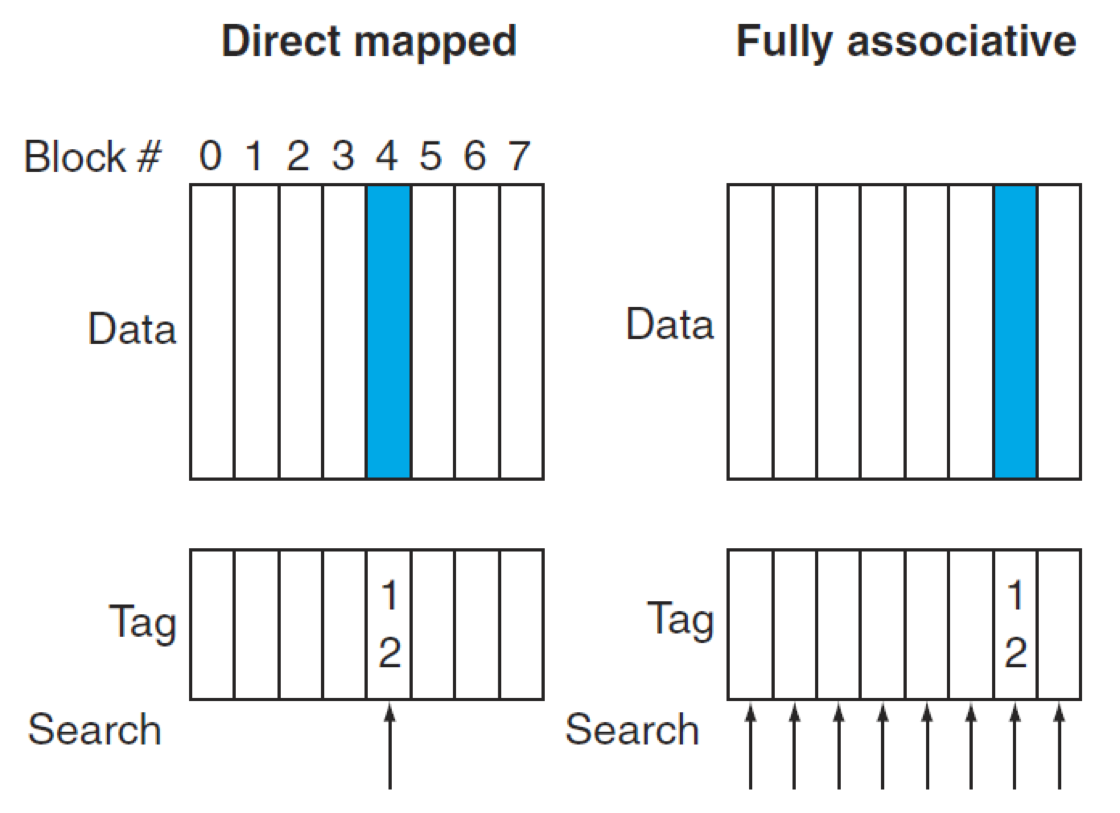
메인 메모리의 어떤 블록이든 캐시 내의 비어있는 아무 위치에나 저장될 수 있습니다.
충돌 미스가 전혀 발생하지 않아 미스율이 가장 낮습니다.
하지만, 원하는 블록을 찾기 위해 캐시 내의 모든 엔트리(블록)를 동시에 검색해야 하므로, 각 캐시 엔트리에 전용 비교기(Comparator)가 필요하여 하드웨어 비용이 매우 높고 히트 타임이 가장 깁니다.
세트 연관 캐시 (Set-Associative Cache):
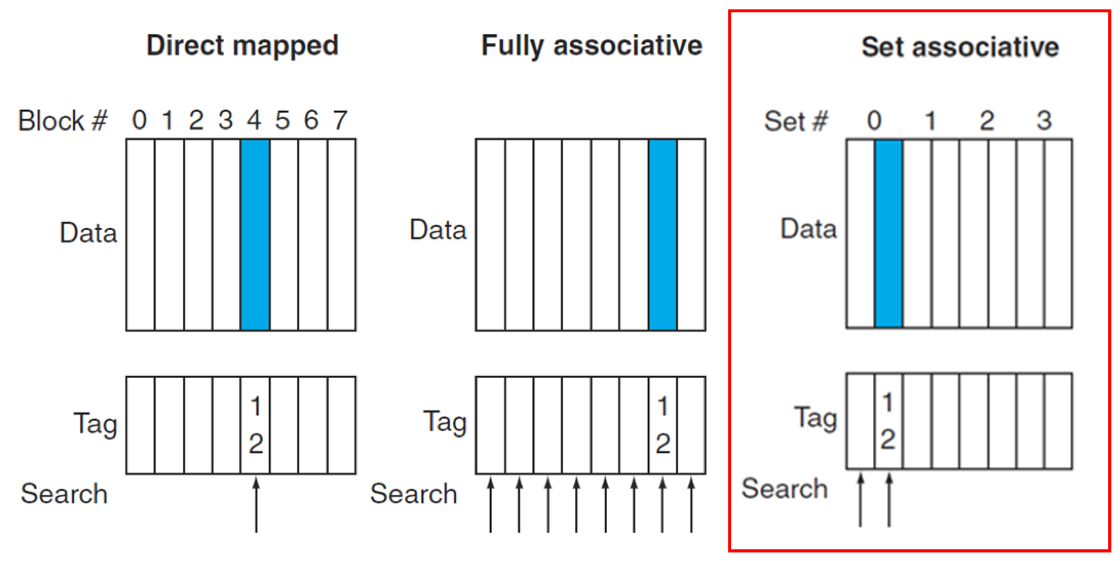
메인 메모리의 블록은 캐시 내의 특정 '세트(Set)' 중 어느 한 위치에 저장될 수 있습니다. 각 세트는 N개의 블록을 포함하며, 이를 N-way 세트 연관 캐시라고 합니다.
메모리 블록은
(블록 번호) modulo (캐시 내 세트 수)를 통해 매핑될 세트를 결정합니다.직접 매핑 방식보다 충돌 미스를 줄여 미스율을 낮추는 데 효과적입니다. 그러나 하나의 세트 내에서 여러 블록을 동시에 비교해야 하므로, 완전 연관 캐시보다는 덜 복잡하지만 직접 매핑보다는 더 많은 비교기(Comparator)가 필요하여 히트 타임이 약간 증가할 수 있습니다.
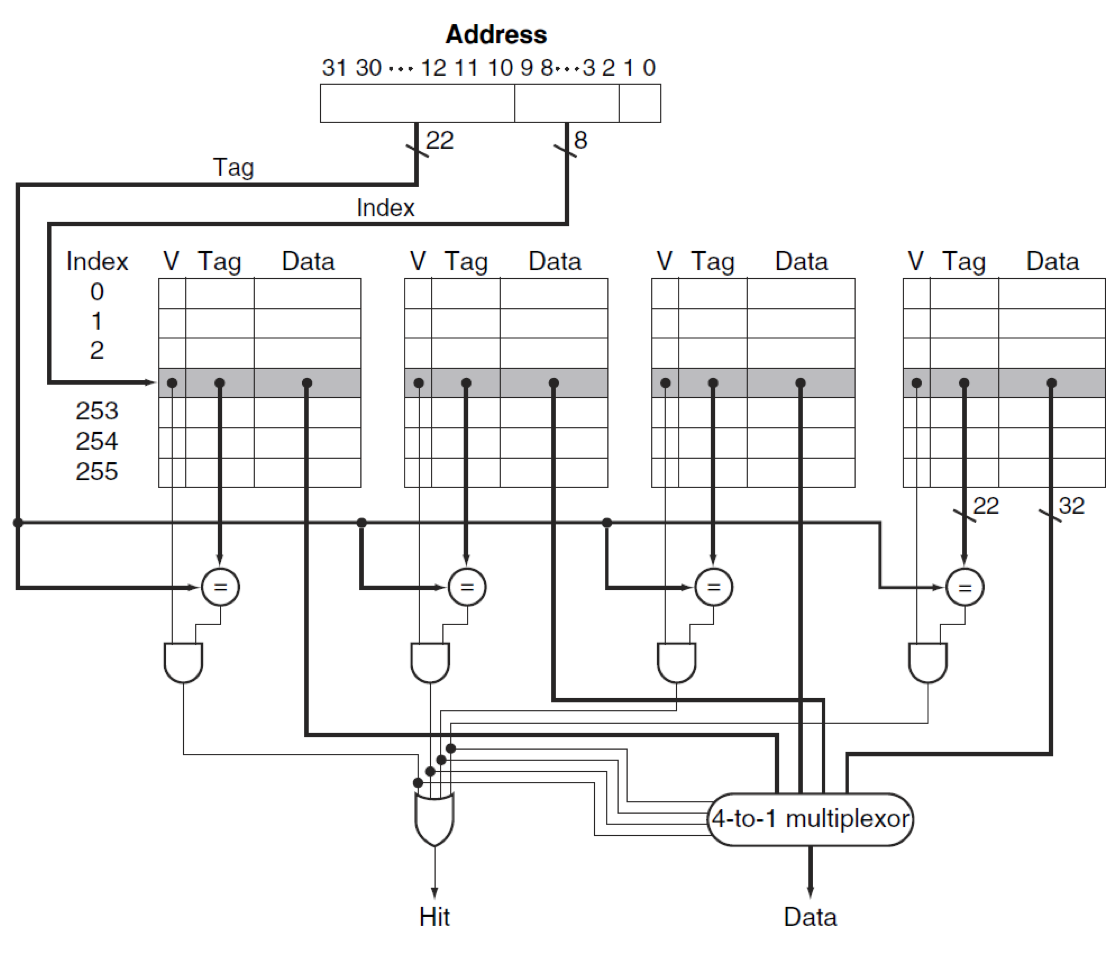
4 way set associative cache 입니다.
| 캐시 종류 | 교체 대상 블록 선택 기준 | 설명 |
|---|---|---|
| 완전 연관 캐시 | 캐시 내의 모든 블록 | 미스 발생 시, 캐시 전체에 걸쳐 어떤 블록이든 교체될 후보가 됩니다. |
| 세트 연관 캐시 | 요청된 블록이 매핑될 선택된 세트 내의 블록들 중에서 | 미스 발생 시, 해당 블록이 속한 특정 세트 안에서 교체할 블록을 선택합니다. LRU (Least Recently Used) (가장 오랫동안 사용되지 않은 블록) 정책 등이 사용될 수 있습니다. |
| 직접 매핑 캐시 | 요청된 블록이 저장될 정확히 한 위치를 점유하고 있는 블록 | 미스 발생 시, 새로운 블록은 정해진 단 하나의 위치에만 들어갈 수 있으므로, 해당 위치에 있던 기존 블록은 무조건 교체됩니다. |
Associativity 증가 (Associativity 낮은 모델 --> 높은 모델: 직접 매핑 → 세트 연관 → 완전 연관)
장점:
미스율 감소 (특히 충돌 미스 감소): 연관도가 증가할수록 특정 메모리 블록이 캐시 내의 더 많은 위치에 저장될 수 있게 됩니다. 이는 여러 블록이 동일한 캐시 위치를 두고 경쟁하는 **충돌 미스(Conflict Miss)**의 발생 가능성을 크게 줄여줍니다.
특히 직접 매핑(1-way)에서 2-way 세트 연관 방식으로 변경할 때 미스율 감소 효과가 가장 큽니다. 이후 연관도를 더 높여도 미스율 감소 폭은 줄어듭니다.
유연한 블록 배치: 데이터 블록을 캐시 내의 더 많은 위치에 유연하게 배치할 수 있어, 지역성 원리(특히 공간 지역성)를 더 효과적으로 활용할 수 있습니다.
단점:
히트 타임(Hit Time) 증가: 연관도가 증가하면, CPU가 요청한 데이터가 캐시에 있는지 확인하기 위해 더 많은 태그(Tag)를 동시에 비교해야 합니다. 예를 들어, 4-way 세트 연관 캐시는 4개의 비교기와 4-to-1 멀티플렉서(Mux)가 필요합니다. 이러한 병렬 비교 및 선택 과정 때문에 캐시 히트 시 데이터를 가져오는 시간이 길어집니다.
하드웨어 복잡성 및 비용 증가: 여러 태그를 동시에 비교하기 위한 비교기(Comparator)의 수가 늘어나고, 여러 데이터 경로 중 하나를 선택하는 멀티플렉서의 크기가 커지므로 하드웨어의 복잡성이 증가하고 제조 비용이 비싸집니다.
전력 소모 증가: 더 많은 하드웨어와 병렬 연산으로 인해 전력 소모가 늘어날 수 있습니다.
LRU 구현의 어려움: 완전 연관 캐시나 세트 연관 캐시에서 미스 발생 시 교체할 블록을 선택하는 정책(예: LRU, Least Recently Used)의 구현이 복잡해집니다. 특히 연관도가 커질수록 정확한 LRU 구현은 매우 어렵고 비용이 많이 듭니다.(연관도가 커진다는 것은 저장 장소의 경우의 수가 많아진다는 말이므로 LRU를 구현하려면 저장 장소에 대해 모두 추적하고 있어야 하기 때문입니다.)


