
CPU: 파이프라인 단계별 명령어 속도 비교: lw, sw, R-format, Branch 명령어 처리 시간
Instruction class에 따른 속도 차이\
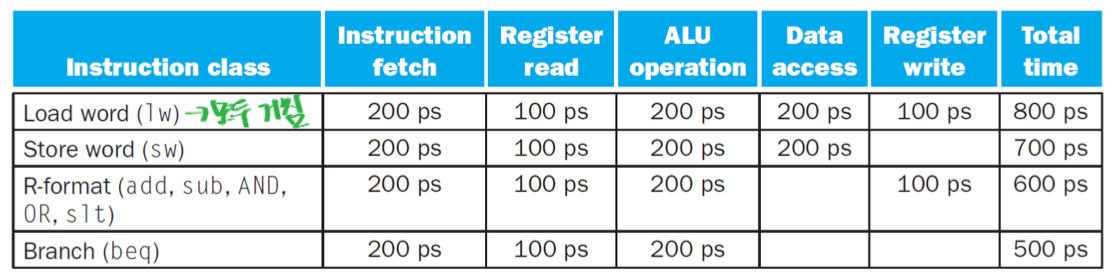
주어진 표를 보면 Load word (lw) 명령어가 다른 명령어들보다 Total time이 가장 길게 나와있습니다. 그 이유는 lw 명령어가 5단계 파이프라인의 모든 단계를 거쳐야 하기 때문입니다.
각 명령어가 거치는 단계와 해당 단계의 시간을 자세히 살펴보겠습니다.
Load word (lw):
Instruction fetch: 200 ps
Register read: 100 ps
ALU operation: 200 ps (주소 계산:
Base + Offset)Data access: 200 ps (계산된 주소에서 데이터 메모리 읽기)
Register write: 100 ps (읽어온 데이터를 레지스터에 쓰기)
Total time: 800 ps
lw명령어는 메모리에서 데이터를 읽어와 레지스터에 쓰는 명령어이므로, **Instruction Fetch, Register Read, ALU Operation (주소 계산), Data Access (메모리 읽기), Register Write (결과 저장)**의 모든 5단계를 거쳐야 합니다. 따라서 가장 긴 시간이 소요됩니다.Store word (sw):
Instruction fetch: 200 ps
Register read: 100 ps
ALU operation: 200 ps (주소 계산:
Base + Offset)Data access: 200 ps (계산된 주소에 데이터 메모리 쓰기)
Register write: (없음)
Total time: 700 ps
sw명령어는 레지스터의 데이터를 메모리에 쓰는 명령어입니다.lw와 마찬가지로 주소를 계산하고 메모리에 접근해야 하지만, 메모리에 데이터를 쓴 후 레지스터에 결과를 다시 쓸 필요가 없습니다. (Store 명령어는 레지스터를 업데이트하지 않음) 따라서Register write단계가 생략되어100 ps가 줄어듭니다.R-format (add, sub, AND, OR, slt):
Instruction fetch: 200 ps
Register read: 100 ps
ALU operation: 200 ps (레지스터 값 간의 연산)
Data access: (없음)
Register write: 100 ps (ALU 연산 결과를 레지스터에 쓰기)
Total time: 600 ps
R-format 명령어는 레지스터 간의 연산만 수행합니다. 따라서 데이터 메모리에 접근할 필요가 없습니다.
Data access단계가 생략되어200 ps가 줄어듭니다.Branch (beq):
Instruction fetch: 200 ps
Register read: 100 ps
ALU operation: 200 ps (두 레지스터 값 비교)
Data access: (없음)
Register write: (없음)
Total time: 500 ps
beq명령어는 두 레지스터 값을 비교하고 (ALU), 조건이 맞으면 분기합니다. 이 명령어는 데이터 메모리에 접근하지 않고, 레지스터에 어떤 값도 쓰지 않습니다. 따라서Data access와Register write단계가 모두 생략됩니다.


