
CPU: 예외(Exception)
MIPS 아키텍처에서의 예외(Exception) 이해
MIPS 프로세서에서 예외(Exception)란, 프로그램의 정상적인 실행 흐름을 방해하고 특별한 처리를 요구하는 예상치 못한 이벤트를 의미합니다. 이는 프로세서의 내부적인 원인(예: 잘못된 명령어 실행) 또는 외부적인 원인(예: I/O 장치 요청)에 의해 발생할 수 있습니다. 예외는 시스템의 안정성과 신뢰성을 보장하기 위해 프로세서가 반드시 인식하고 적절히 처리해야 하는 중요한 메커니즘입니다.
1. 예외의 종류 및 분류
MIPS에서 다양한 이벤트를 예외 또는 인터럽트로 분류하는 방식을 명확히 보여줍니다.
| 이벤트 유형 | 발생 위치 | MIPS 용어 | 예시 |
|---|---|---|---|
| I/O 장치 요청 | 외부 (External) | 인터럽트 (Interrupt) | 키보드 입력, 마우스 클릭, 네트워크 패킷 수신, 디스크 읽기/쓰기 완료, 타이머 만료 등. 프로세서 외부 장치에서 발생하며 비동기적입니다. |
| 사용자 프로그램의 OS 요청 | 내부 (Internal) | 예외 (Exception) | syscall 명령어와 같이 사용자 프로그램이 운영체제 서비스(파일 입출력, 메모리 할당 등)를 명시적으로 요청할 때 발생합니다. |
| 산술 오버플로우 | 내부 (Internal) | 예외 (Exception) | add 명령어와 같이 부호 있는 정수 연산 결과가 레지스터의 표현 범위를 초과할 때 발생합니다. (예: 32비트 레지스터에 2^31-1을 초과하는 값 저장 시) |
| 정의되지 않은 명령어 사용 | 내부 (Internal) | 예외 (Exception) | 프로세서가 인식할 수 없는 비표준 명령어 코드를 실행하려고 할 때 발생합니다. |
| 하드웨어 오작동 | 내부/외부 (Either) | 예외 또는 인터럽트 | 메모리 오류(버스 오류 등)나 기타 하드웨어 결함으로 인해 발생할 수 있습니다. 상황에 따라 내부 예외로 처리되거나 외부 신호에 의한 인터럽트로 처리될 수 있습니다. |
핵심 구분:
인터럽트는 프로세서 외부에서 오는 예외의 한 종류로, 주로 I/O 장치와 관련이 있습니다.
나머지 대부분의 예외는 프로세서 내부에서 발생하며, 프로그램 실행 중 발생한 오류나 운영체제 요청과 관련이 깊습니다.
2. MIPS에서의 예외 처리 절차 (General)
예외가 발생했을 때 MIPS 프로세서는 CP0(Coprocessor 0, 시스템 제어 코프로세서)의 특수 레지스터들을 활용하여 정해진 절차에 따라 예외를 처리합니다.
문제 발생 명령어의 주소 저장 (Save EPC):
프로세서는 예외가 발생한 명령어의 주소(또는 파이프라인에서 지연 슬롯에 있었을 경우 지연 슬롯의 명령어 주소)의 다음 줄(PC+4)을 EPC (Exception Program Counter) 레지스터 (CP0, Reg 14)에 저장합니다. 이는 예외 처리 후 원래 프로그램으로 복귀할 지점을 알려주는 역할을 합니다.
예외 원인 저장 (Save Cause Register):
발생한 예외의 유형(원인, 32비트)을 Cause 레지스터에 기록합니다. Cause 레지스터 내의 ExcCode(Exception Code) 필드는 각 예외 유형에 대한 고유한 코드를 가집니다 (예: 정의되지 않은 명령어는
10, 산술 오버플로우는12).
예외 핸들러로 점프 (Jump to Handler):
CP0 레지스터(특히 Cause 레지스터의 ExcCode, Status 레지스터의 BEV 비트 등)의 정보를 기반으로, 프로세서는 미리 정해진 예외 벡터 주소로 점프합니다. 이 주소에는 해당 예외를 처리하기 위한 특별한 코드인 **예외 핸들러(Exception Handler)**가 위치합니다.
정의되지 않은 명령어의 경우
8000 0000_hex로, 산술 오버플로우의 경우8000 0180_hex로 점프합니다.
예외 핸들러는 발생한 예외의 종류를 식별하고, 적절한 처리(예: 에러 메시지 출력, 리소스 할당, 프로그램 재시작 등)를 수행합니다. 처리 완료 후에는
eret(Exception Return) 명령어 등을 사용하여EPC에 저장된 주소로 돌아가 프로그램 실행을 재개합니다.
3. 파이프라인에서의 예외 처리
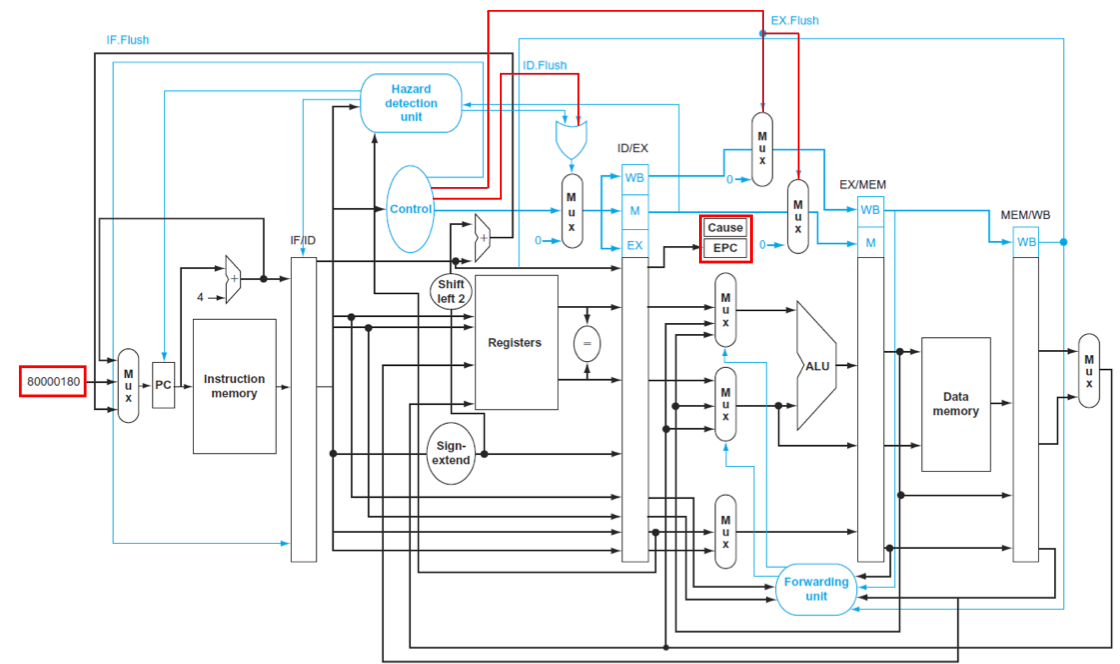
add $1, $2, $1 명령어에서 EX(Execute) 스테이지에서 오버플로우가 발생했다고 가정할 경우, 파이프라인은 다음 절차를 따릅니다.
오버플로우 값 저장 방지:
ALU에서 오버플로우가 감지되면, 잘못된 결과 값($1 레지스터)이 레지스터 파일에 쓰이는 것을 즉시 중단해야 합니다. 이는 해당 명령어의 Write Back (WB) 스테이지를 취소(stall 또는 flush)함으로써 이루어집니다.
이전 명령어들 완료:
오버플로우가 발생한
add명령어보다 먼저 파이프라인에 들어와 있었던 모든 명령어들은 정상적으로 실행을 완료하도록 허용합니다. 파이프라인은 명령어들의 원래 프로그램 순서를 보장해야 하므로, 이미 시작된 이전 작업들은 완료되어야 합니다.
이후 명령어들 플러시 (Flush):
오버플로우가 발생한
add명령어 뒤에 파이프라인에 들어온 모든 명령어들은 즉시 파이프라인에서 제거되고 버려집니다 (Flush, 비우다). 이 명령어들은 예외 처리 루틴으로의 점프 이후에는 더 이상 유효하지 않기 때문입니다. 이미지에서 "EX.Flush"는 EX 스테이지에서 예외가 감지되었을 때 플러시가 시작됨을 나타냅니다.
EPC 및 Cause 레지스터 값 설정:
예외 발생 시점의 정확한 프로그램 상태를 기록합니다. 예외가 발생한
add명령어의 주소를 EPC에, 오버플로우를 나타내는 코드(12)와 기타 정보를 Cause 레지스터에 저장합니다.
오버플로우 핸들러로 점프:
마지막으로, 파이프라인의 다음 인출될 명령어 주소를 오버플로우 예외 핸들러의 시작 주소(
8000 0180_hex)로 변경하여 제어권을 넘깁니다. 이로써 예외 처리 루틴이 시작됩니다.
파이프라인에서의 예외 처리의 중요성: 파이프라인 환경에서의 예외 처리는 정확한 예외(Precise Exception) 개념과 밀접하게 관련됩니다. 이는 예외 발생 시, 예외를 일으킨 명령어까지는 모든 동작이 완료되고, 그 이후의 명령어는 아무런 영향을 미치지 않도록 해야 한다는 원칙입니다. 이를 위해 파이프라인은 복잡한 플러싱 및 상태 저장 메커니즘을 동원하게 됩니다.


