
CPU: Single Cycle vs Pipeline 성능 비교
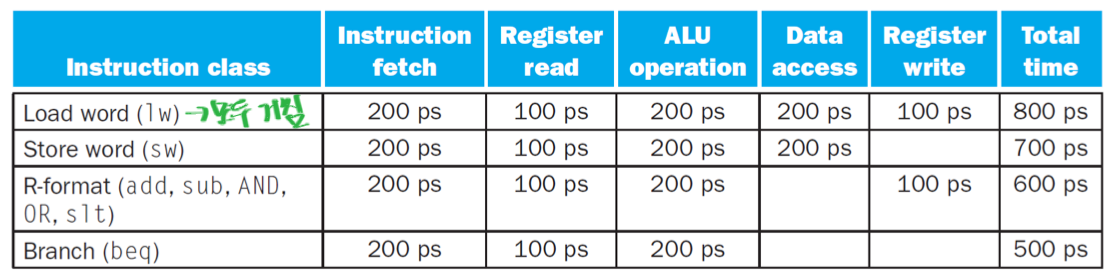
주어진 파이프라인 각 단계의 속도(시간)를 바탕으로 **단일 사이클 프로세서(Single-Cycle Processor)**와 **파이프라인 프로세서(Pipelined Processor)**의 성능을 비교해 보겠습니다.
1. 단일 사이클 프로세서 (Single-Cycle Processor) 성능 분석
단일 사이클 프로세서는 하나의 명령어를 실행하는 데 필요한 모든 단계를 하나의 클럭 사이클 안에 완료합니다. 따라서 클럭 사이클의 길이는 모든 명령어 중 가장 오래 걸리는 명령어의 실행 시간에 의해 결정됩니다.
주어진 표에서 가장 오래 걸리는 명령어는 Load word (lw)로, 총 800 ps가 소요됩니다.
단일 사이클 프로세서의 클럭 사이클 시간 (Cycle Time): 800 ps
클럭 사이클 시간 : 파이프라인에서 다음 단계로 넘어갈 수 있는 최소 시간
단일 사이클 프로세서의 처리율 (Throughput): 1 명령어 / 800 ps = 1.25 x 10^9 명령어/초 = 1.25 GIPS (Giga Instructions Per Second)
장점: 구현이 단순합니다. 단점: 클럭 사이클이 가장 느린 명령어에 맞춰지기 때문에, 빠른 명령어들도 불필요하게 오래 걸리게 되어 전체적인 성능(처리율)이 낮습니다.
2. 파이프라인 프로세서 (Pipelined Processor) 성능 분석
파이프라인 프로세서는 각 파이프라인 단계가 독립적으로 작동하며, 가장 긴 파이프라인 단계의 시간이 클럭 사이클 시간이 됩니다.
주어진 표에서 각 파이프라인 단계의 시간을 살펴보겠습니다:
Instruction fetch: 200 ps
Register read: 100 ps
ALU operation: 200 ps
Data access: 200 ps
Register write: 100 ps
가장 긴 단계는 Instruction fetch, ALU operation, Data access로 모두 200 ps입니다.(모두 가장 긴 단계의 속도로 맞춰줍니다.)
파이프라인 프로세서의 클럭 사이클 시간 (Cycle Time): 200 ps
파이프라인 프로세서의 처리율 (Throughput): 1 명령어 / 200 ps = 5 x 10^9 명령어/초 = 5 GIPS (Giga Instructions Per Second)
(이상적인 경우): 파이프라인이 항상 가득 차 있고 해저드가 없다고 가정할 때, 매 클럭 사이클마다 하나의 명령어가 완료됩니다.
장점: 클럭 사이클 시간이 단축되어, 동일 시간당 더 많은 명령어를 처리할 수 있습니다 (높은 처리율). 단점: 해저드(Hazard) 발생 시 스톨(Stall) 등으로 인해 성능이 저하될 수 있으며, 파이프라인 레지스터 등으로 인해 하드웨어 복잡성이 증가합니다.
2-1. 파이프라인 속도 향상 수식 (Pipelining Speed-up Formula)
수식은 다음과 같습니다:
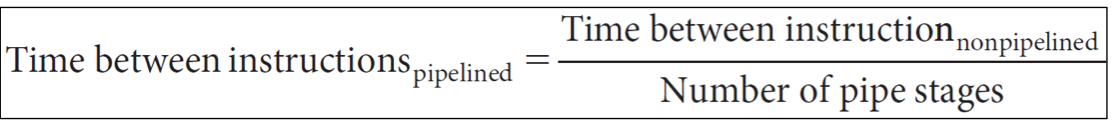
이 수식은 이상적인 경우 (If the stages are perfectly balanced) 파이프라인 프로세서에서 연속된 명령어들 사이의 시간 간격(즉, 한 명령어가 완료되고 다음 명령어가 완료될 때까지 걸리는 시간)이 어떻게 단축되는지를 보여줍니다.
각 용어의 의미는 다음과 같습니다:
Time between instructions_pipelined: 파이프라인 프로세서에서 두 개의 연속적인 명령어 완성 사이의 시간 간격입니다. 이상적인 파이프라인에서는 **가장 긴 파이프라인 단계의 시간(클럭 사이클 시간)**과 같습니다. 이것이 바로 파이프라인이 성능을 향상시키는 핵심 지표입니다. 이 시간이 짧을수록 프로세서의 처리율(Throughput)이 높아집니다.
Time between instructions_nonpipelined: 단일 사이클 프로세서에서 하나의 명령어를 완전히 실행하는 데 걸리는 시간입니다. 이는 모든 명령어 중 가장 긴 실행 시간을 가진 명령어의 전체 실행 시간과 같습니다. (주어진 표에서는 Load word의 800 ps)
Number of pipe stages: 프로세서 파이프라인의 총 단계 수입니다. (MIPS의 경우 5단계)
수식의 의미:
이 수식은 "만약 모든 파이프라인 단계의 시간이 정확히 동일하게 분배되어 있다면, 파이프라인을 사용했을 때 명령어 간의 시간 간격(즉, 클럭 사이클 시간)은 단일 사이클 프로세서의 명령어 실행 시간을 파이프라인 단계 수로 나눈 것과 같다"는 것을 말해줍니다.
예시:
만약 단일 사이클 명령어 실행 시간이 800 ps이고, 파이프라인이 5단계로 완벽하게 균형 잡혀 있다면, 각 단계는 800 ps / 5 = 160 ps가 되어야 합니다.
따라서, 이상적인 파이프라인의 클럭 사이클 시간은 160 ps가 될 것이라는 이론적인 예측입니다.
2-2. 실제 파이프라인의 불균형과 그 의미 (However, the stages are not perfectly balanced)
이미지 하단에 있는 설명은 이 수식이 현실에 완벽하게 적용되지 않는 이유를 보여줍니다.
Time between instructions_{pipelined} = 200ps:이는 주어진 표에서 실제로 가장 긴 파이프라인 단계의 시간입니다. (Instruction fetch, ALU operation, Data access가 모두 200 ps)
실제 파이프라인의 클럭 사이클 시간은 이론적인 160 ps가 아니라, 가장 느린 단계의 시간인 200 ps로 결정됩니다.
800ps / 5 = 160ps:이것은 위에 설명된 수식에 단일 사이클 시간(800 ps)과 단계 수(5)를 대입하여 얻은 이론적인 최적 클럭 사이클 시간입니다.
200ps ≠ 160ps:이 불등호(
≠)는 **실제 파이프라인의 클럭 사이클 시간(200 ps)**이 **이론적인 최적 클럭 사이클 시간(160 ps)**과 다르다는 것을 명확히 보여줍니다.이러한 차이가 발생하는 이유는 파이프라인의 각 단계에 걸리는 시간이 완벽하게 균등하게 분배되어 있지 않기 때문입니다 ("the stages are not perfectly balanced").
3. 성능 비교 및 분석
이상적인 클럭 사이클 시간 비교:
단일 사이클: 800 ps
파이프라인: 200 ps
파이프라인 프로세서의 클럭이 단일 사이클 프로세서보다 4배 빠릅니다. (800 ps / 200 ps = 4)
총 실행 시간 비교 예시
기본 가정:
단일 사이클 프로세서 클럭 사이클 시간: 800 ps
파이프라인 프로세서 클럭 사이클 시간: 200 ps
파이프라인 깊이: 5단계 (MIPS 5단계 파이프라인)
해저드는 없다고 가정합니다.
3-1. 명령어 수 = 3개일 때
3-1-1. 단일 사이클 프로세서
총 실행 시간 = 명령어 수 * 단일 사이클 클럭 시간
총 실행 시간 = 3 명령어 * 800 ps/명령어 = 2400 ps = 2.4 ns
3-1-2. 파이프라인 프로세서
총 사이클 수 = (파이프라인 깊이 + 명령어 수 - 1)
총 사이클 수 = (5 + 3 - 1) = 7 사이클
총 실행 시간 = 총 사이클 수 * 파이프라인 클럭 사이클 시간
총 실행 시간 = 7 사이클 * 200 ps/사이클 = 1400 ps = 1.4 ns
비교 및 분석 (3개 명령어):
이 경우, 파이프라인 프로세서가 단일 사이클 프로세서보다 약 1.7배 빠릅니다. (2400 ps / 1400 ps ≈ 1.71)
명령어 수가 적을 때는 파이프라인을 채우는 데 걸리는 초기 지연(5단계)의 영향이 비교적 크게 나타나지만, 그래도 단일 사이클보다는 성능이 좋습니다.
2. 명령어 수 = 1,000,003개일 때
2-1. 단일 사이클 프로세서
총 실행 시간 = 명령어 수 * 단일 사이클 클럭 시간
총 실행 시간 = 1,000,003 명령어 * 800 ps/명령어 = 800,002,400 ps = 800.0024 ns
2-2. 파이프라인 프로세서
총 사이클 수 = (파이프라인 깊이 + 명령어 수 - 1)
총 사이클 수 = (5 + 1,000,003 - 1) = 1,000,007 사이클
총 실행 시간 = 총 사이클 수 * 파이프라인 클럭 사이클 시간
총 실행 시간 = 1,000,007 사이클 * 200 ps/사이클 = 200,001,400 ps = 200.0014 ns
비교 및 분석 (1,000,003개 명령어):
이 경우, 파이프라인 프로세서가 단일 사이클 프로세서보다 약 4배 빠릅니다. (800,002,400 ps / 200,001,400 ps ≈ 3.9999...)
명령어 수가 매우 많을 때는 파이프라인을 채우는 초기 오버헤드(5단계)의 영향이 거의 무시할 수 있게 됩니다. 따라서 파이프라인의 클럭 사이클 단축 효과가 극대화되어, 클럭 사이클 시간 비율(800 ps / 200 ps = 4배)만큼의 성능 향상에 가까워집니다.
총평
파이프라인은 명령어 수가 많을수록 성능 향상 효과가 극대화됩니다. 이는 초기 파이프라인 채우는 데 필요한 오버헤드(파이프라인 깊이 - 1 사이클)가 전체 실행 시간에서 차지하는 비중이 줄어들기 때문입니다.
반면, 단일 사이클 프로세서는 명령어 수와 관계없이 각 명령어당 고정된 긴 시간을 소요하므로, 명령어 수가 늘어날수록 총 실행 시간도 비례하여 길어집니다.
이 예시는 파이프라인이 왜 현대 프로세서의 필수적인 요소이며, 대규모 프로그램을 실행할 때 얼마나 큰 성능 이점을 제공하는지를 명확하게 보여줍니다.
결론:
파이프라인은 단일 사이클 프로세서에 비해 클럭 사이클 시간을 획기적으로 줄여 더 높은 클럭 주파수에서 동작할 수 있게 합니다. 이로 인해 동일 시간 내에 훨씬 더 많은 명령어를 처리할 수 있게 되어(처리율 증가), 전체 프로그램의 실행 시간을 단축시킵니다.


