
CPU: 5단계 파이프라인 구조와 각 단계별 동작 원리
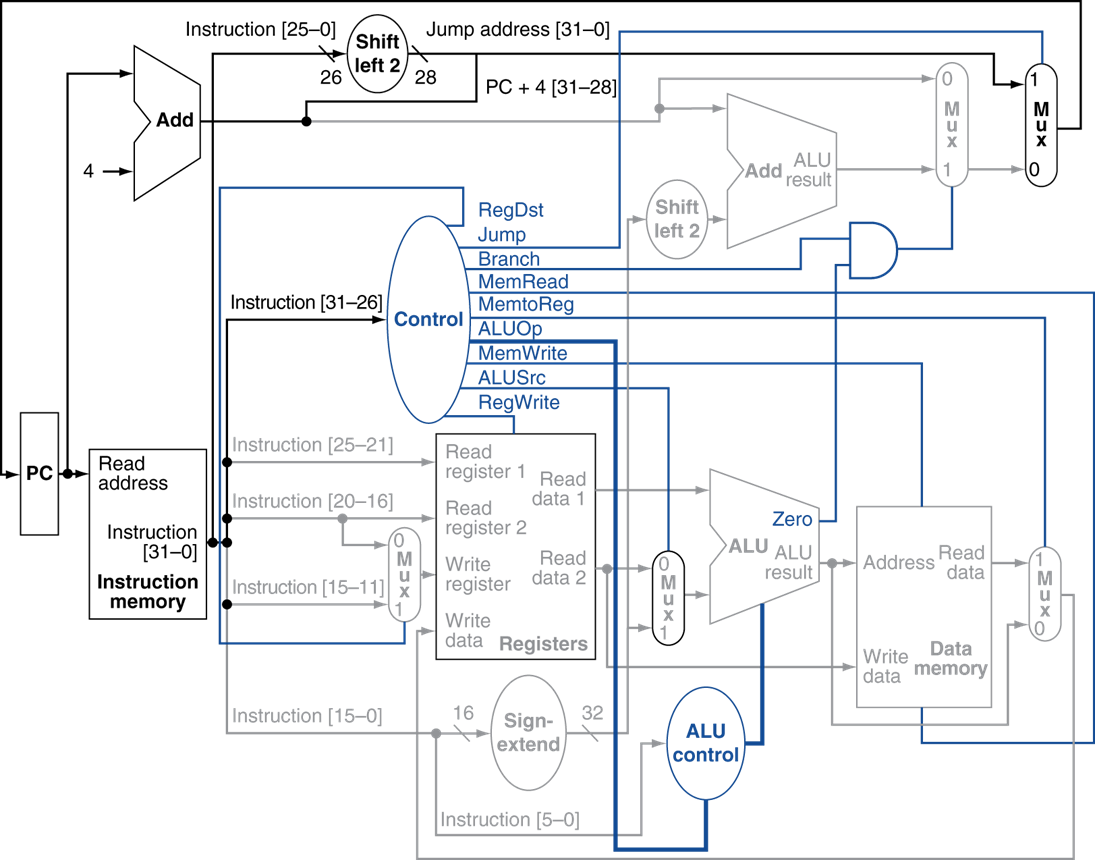
MIPS의 전통적인 5단계 파이프라인은 다음과 같습니다:
IF (Instruction Fetch): 명령어 인출
ID (Instruction Decode/Register Fetch): 명령어 해독 및 레지스터 인출
EX (Execute): 실행
MEM (Memory Access): 메모리 접근
WB (Write Back): 쓰기
각 단계는 하나의 클럭 사이클 동안 수행되며, 각 단계는 독립적인 하드웨어 유닛에 의해 처리될 수 있도록 설계되었습니다. 이는 여러 명령어가 동시에 파이프라인의 다른 단계에 존재할 수 있게 하여 CPU의 전체적인 처리율(throughput)을 크게 향상시킵니다.
MIPS 5단계 파이프라인 상세 설명
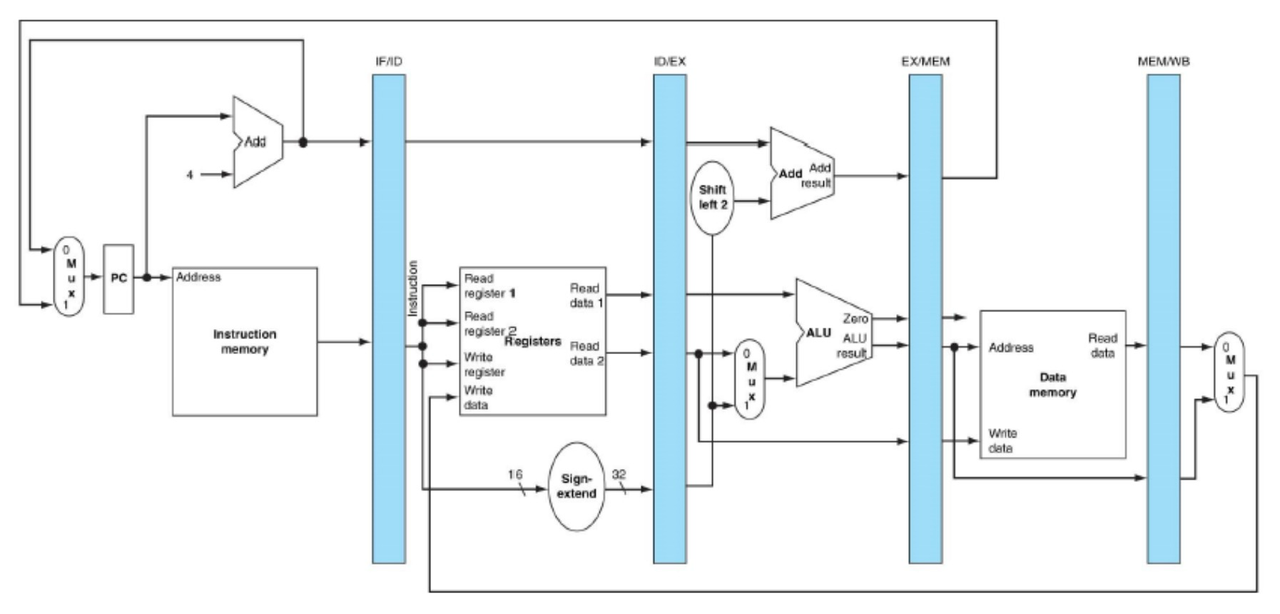
각 단계 사이에는 **파이프라인 레지스터(Pipeline Registers 또는 Latch)**가 존재하여 이전 단계의 결과를 다음 단계로 전달하고, 각 단계가 다음 클럭 사이클에 동시에 실행될 수 있도록 격리하는 역할을 합니다. (예: IF/ID, ID/EX, EX/MEM, MEM/WB)
1. IF (Instruction Fetch) 단계: 명령어 인출
목표: 프로그램 카운터(PC)가 가리키는 메모리 주소에서 다음 32비트 명령어를 가져옵니다.
관련 하드웨어:
PC (Program Counter): 현재 Fetch할 명령어의 주소를 저장합니다.
Instruction Memory (IM): 명령어가 저장된 주 메모리 영역입니다.
Adder (PC + 4): 다음 순차 명령어의 주소(
PC + 4)를 미리 계산합니다. (MIPS 명령어는 4바이트이므로)
작동 방식:
현재 PC 값으로 Instruction Memory에 접근하여 해당 주소의 32비트 명령어를 읽어옵니다.
PC + 4값을 계산하여 다음 클럭 사이클에 Fetch할 다음 명령어의 주소를 준비합니다. (분기/점프가 없는 경우)읽어온 명령어와
PC + 4값은IF/ID 파이프라인 레지스터에 저장되어 다음 클럭 사이클에 ID 단계로 전달됩니다.
특징: 이 단계에서 명령어 자체는 해석되지 않고 단순히 메모리에서 가져오기만 합니다.
2. ID (Instruction Decode / Register Fetch) 단계: 명령어 해독 및 레지스터 인출
목표: IF 단계에서 가져온 명령어를 해독하고, 명령어 실행에 필요한 레지스터 값을 레지스터 파일에서 읽어옵니다.
관련 하드웨어:
Control Unit: 명령어의 Opcode 및 Funct 필드를 분석하여 모든 파이프라인 단계에 걸쳐 필요한 제어 신호(RegWrite, MemRead, ALUOp, Branch 등)를 생성합니다.
Register File (RegFile): 32개의 범용 레지스터를 포함하며, 최대 두 개의 레지스터 값을 동시에 읽을 수 있습니다.
Sign Extender: I-type 명령어의 16비트 즉시값(Immediate Value)을 32비트로 부호 확장합니다.
Shift Left 2 (for Branch Target): 분기 명령어의 16비트 오프셋을 2비트 왼쪽 시프트하여 (워드 단위 오프셋으로 변환) 분기 타겟 주소 계산에 준비합니다.
작동 방식:
IF/ID 레지스터에서 32비트 명령어를 읽어옵니다.Control Unit은 명령어의 Opcode와 Funct 필드를 해독하여 명령어 유형(R-type, I-type, J-type)을 식별하고, 해당 명령어에 필요한 제어 신호들을 생성합니다. 이 제어 신호들은ID/EX 레지스터로 전달됩니다.명령어의
rs필드(Source Register 1)와rt필드(Source Register 2)를 사용하여Register File에서 해당 레지스터의 값을 읽어옵니다. 이 값들도ID/EX 레지스터로 전달됩니다.I-type 명령어의 16비트 즉시값은
Sign Extender를 통해 32비트로 확장되어ID/EX 레지스터로 전달됩니다.분기 명령어의 경우, 분기 타겟 주소를 부분적으로 계산합니다:
(PC from IF/ID) + (Sign Extended Immediate << 2). 이 값도ID/EX 레지스터로 전달됩니다.
특징: 이 단계에서 레지스터 읽기, 명령어 해독, 즉시값 확장이 병렬적으로 수행되어 시간을 절약합니다.
3. EX (Execute) 단계: 실행
목표: 명령어의 핵심 연산(산술/논리 연산, 주소 계산)을 수행하거나, 분기 조건을 평가합니다.
관련 하드웨어:
ALU (Arithmetic Logic Unit): 산술(덧셈, 뺄셈 등) 및 논리(AND, OR 등) 연산을 수행합니다.
ALU Control:
Control Unit에서 넘어온ALUOp신호와 명령어의 Funct 필드를 바탕으로 ALU가 수행할 정확한 연산을 결정합니다.Mux (ALU Source): ALU의 두 번째 입력으로 레지스터 값(
rt)을 쓸지, 아니면 확장된 즉시값을 쓸지 선택합니다. (제어 신호ALUSrc에 의해 결정)
작동 방식:
ID/EX 레지스터에서 필요한 레지스터 값(read data 1, read data 2), 확장된 즉시값, 제어 신호들을 가져옵니다.ALU Control에 따라 ALU의 연산이 결정됩니다.ALU는 선택된 두 입력 값(read data 1과 read data 2 또는 read data 1과 확장된 즉시값)을 가지고 연산을 수행합니다.
R-type 명령어:
(read data 1) op (read data 2)I-type 명령어 (예:
addi):(read data 1) op (Sign Extended Immediate)Load/Store 명령어 (
lw,sw):(read data 1) + (Sign Extended Immediate)로 데이터 메모리 주소를 계산합니다.
분기 명령어 (
beq,bne): ALU는 두 레지스터 값의 같음/다름을 비교하여 분기 조건을 평가하고, 그 결과(zero flag)를EX/MEM 레지스터로 전달합니다. PC update는 MEM 단계까지 지연될 수 있습니다.ALU 결과,
read data 2(Store 명령의 경우), 메모리 및 레지스터 쓰기 제어 신호 등이EX/MEM 레지스터에 저장되어 다음 클럭 사이클에 MEM 단계로 전달됩니다.
특징: 모든 연산이 이루어지는 핵심 단계입니다. MIPS의 Load/Store 아키텍처 덕분에 ALU는 연산 또는 주소 계산이라는 명확한 역할에 집중합니다.
4. MEM (Memory Access) 단계: 메모리 접근
목표: 데이터 메모리에 접근하여 데이터를 읽거나(Load 명령어), 쓰거나(Store 명령어) 합니다.
관련 하드웨어:
Data Memory (DM): 프로그램 데이터가 저장된 주 메모리 영역입니다. (하버드 아키텍처에서 Instruction Memory와 분리됨)
Mux (MemRead/MemWrite Control):
Control Unit에서 넘어온 제어 신호(MemRead,MemWrite)에 따라 Data Memory의 읽기/쓰기 동작을 제어합니다.
작동 방식:
EX/MEM 레지스터에서 ALU가 계산한 메모리 주소, Store할 데이터(read data 2), 제어 신호들을 가져옵니다.MemRead신호가 활성화되면: Data Memory에서 ALU가 계산한 주소의 데이터를 읽어옵니다 (lw명령어).MemWrite신호가 활성화되면:read data 2값을 ALU가 계산한 주소에 Data Memory에 씁니다 (sw명령어).메모리에서 읽어온 데이터(Load 명령의 경우),
ALU 결과(Load/Store 외의 명령어), 레지스터 쓰기 제어 신호 및 쓰기 레지스터 주소 등이MEM/WB 레지스터에 저장되어 다음 클럭 사이클에 WB 단계로 전달됩니다.
특징: Load/Store 명령어만이 이 단계에서 실질적인 메모리 접근을 수행합니다. 다른 명령어는 이 단계를 통과하지만 실제 메모리 작업은 하지 않습니다.
5. WB (Write Back) 단계: 쓰기
목표: 명령어 실행 또는 메모리 접근의 최종 결과를 레지스터 파일에 다시 씁니다.
관련 하드웨어:
Register File (RegFile): ALU 연산 결과나 메모리에서 읽어온 데이터를 저장합니다.
Mux (MemToReg): RegFile에 쓸 데이터를 ALU 결과와 메모리에서 읽어온 데이터 중 어느 것으로 할지 선택합니다. (제어 신호
MemToReg에 의해 결정)
작동 방식:
MEM/WB 레지스터에서 ALU 결과, 메모리에서 읽어온 데이터, 레지스터 쓰기 주소, 제어 신호(RegWrite,MemToReg)들을 가져옵니다.RegWrite신호가 활성화되었는지 확인합니다. (Store, Branch, Jump 명령어는 이 단계에서 레지스터에 쓰지 않습니다.)MemToReg신호에 따라 RegFile에 쓸 최종 데이터를 선택합니다:MemToReg = 0(R-type,addi등):MEM/WB래치에 있는ALU 결과를 RegFile에 씁니다.MemToReg = 1(lw):MEM/WB래치에 있는메모리에서 읽어온 데이터를 RegFile에 씁니다.
선택된 데이터는 명령어에서 지정된 목적지 레지스터(
rd또는rt필드)에 쓰여집니다.
특징: 모든 명령어의 최종 결과가 레지스터에 반영되는 단계입니다.


