
RAG (retrieval augmented generation) 이란? 새로운 패러다임 : 검색 증강 생성
RAG 는 검색 증강 생성(Retrieval Augmented Generation)으로 번역할 수 있습니다. 이 RAG는 새로운 개념이라고 부를 수 있는데요. 이것은 무엇일까요?
임베딩 : 인공지능은 모든 데이터를 숫자로 생각한다.
인공지능은 모든 데이터를 숫자로 생각합니다. 예를 들어 OpenAI의 text-embedding-3-large 모델은 "나는 아침에 일어나 커피를 마셨다." 라는 문장을 다음과 같이 3072 차원의 벡터로 생각합니다.
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
],3차원도 생각하기 힘든데 3072차원이라니 상상이 안됩니다. 하지만 쉽게 이해하면 위와 같은 어떤 특성 (feature)가 3072개 있다고 생각하면 됩니다.
이러한 과정을 임베딩이라고 합니다. 그리고 임베딩해서 나온 벡터들을 임베딩 벡터라고 합니다.
인공지능 (LLM) 이 데이터를 숫자로 생각하면 무엇을 할 수 있을까요? 네, 바로 계산을 할 수 있습니다. 어떤 두 문장이 있을 때 벡터값이 서로 비슷하다면 유사한 의미를 가진다는 것을 알 수 있습니다. 일종의 시맨틱 검색이 가능해 진 것입니다.
예전 기술에서는 맥도날드를 검색하면 맥도날드라는 키워드에 일치하는 데이터만 찾을 수 있었습니다. 하지만 이제는 맥도날드를 검색하면 롯데리아와 KFC 등 유사한 의미를 가지는 문맥을 검색할 수 있습니다. 이를 기존 search와 구분하기 위해서 머신러닝에서는 retrieval (검색) 이라고 부릅니다.
이런 임베딩을 통해 LLM이 언어 간의 유사도를 이해하게 되고 이를 통해 일종의 논리를 이해할 수 있습니다.
RAG란?
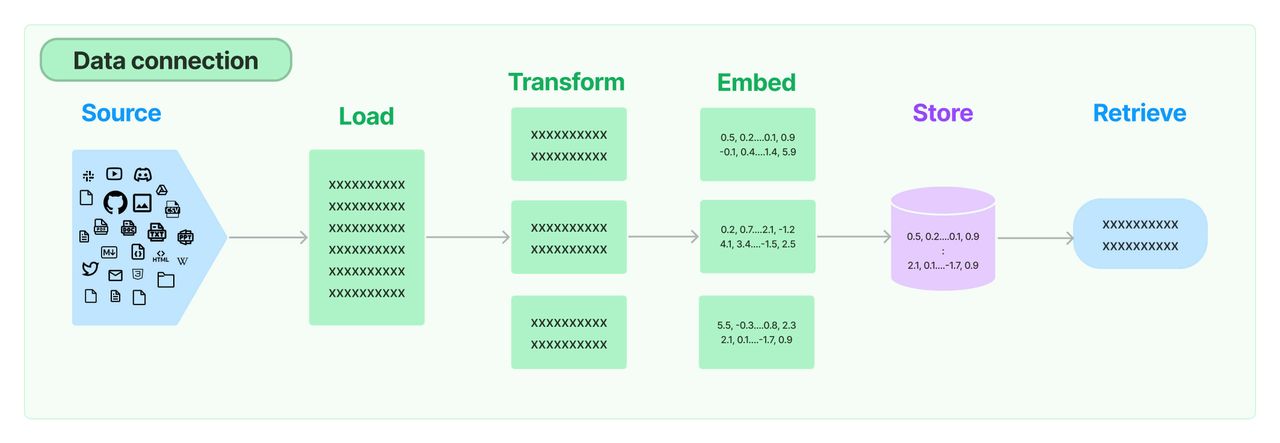
이러한 시맨틱 검색을 가능하게 하기 위해서 만들어 놓은 일련의 프로세스를 의미합니다.
먼저 텍스트를 적절하게 잘라 임베딩 벡터를 만듭니다. 임베딩 모델에도 최대 토큰의 한계가 있기 때문입니다. 예를 들어 OpenAI 임베딩 V3는 8191 토큰의 입력 토큰 한계를 가지고 있습니다. 참고로 텍스트 길이가 길든 짧든 동일한 길이의 임베딩 벡터가 생성됩니다. (예 : 3072개의 벡터.)
그리고 이렇게 자른 벡터를 데이터베이스에 저장합니다. 이 때 굉장히 많은 벡터값을 저장하기 위해 효율적으로 만들어진 벡터 데이터베이스를 사용합니다. 예시로 Pinecone, pgvector, Weaviate, Faiss 등이 있습니다. 이렇게 하면 준비가 끝입니다.
다음에 사용자가 검색어를 입력합니다. 이를 벡터로 변환합니다. 그리고 이 해당 벡터로 벡터데이터베이스에 검색을 합니다. 그러면 유사한 의미의 검색 결과를 받을 수 있습니다.
이제 이렇게 얻은 검색 결과를 바탕으로 사용자의 질문과 결합하여 대답을 합니다. 이 부분이 Augmented Generation 부분입니다.
이렇게 해서 적절한 문맥을 바탕으로 챗봇이 대답을 더 잘할 수 있습니다. 이 때 적합한 데이터가 함께 들어가기 때문에 할루시네이션 등의 오류율도 줄어들겠죠?
이것이 수 많은 커스텀 챗봇, 빙 챗, GPTs의 knowledge 가 작동하는 방식입니다. 물론 여기서 더 나아간 파인튜닝 방법도 있기도 합니다.
이 RAG 개념을 아신다면 앞으로 인공지능이 무엇을 할 수 있을지에 대한 인사이트를 얻으실 수 있습니다. 이 Retrieval은 많은 영역에서 활용할 수 있습니다. 기억해 주세요!
이미지 출처 : 랭체인


