Gemini 3 Agentic Vision(=Gemini 3 Flash) 개념 및 핵심 기능 요약

개요
Agentic Vision은 Gemini 3 Flash의 이미지 이해 방식을 "한 번 보고 답하기"에서 "조사해서 확인하고 답하기"로 바꾸는 기능이다. 핵심은 모델이 에이전트처럼 계획을 세우고, 도구를 호출해(현재는 특히 파이썬 코드 실행) 이미지를 단계적으로 조작·분석하면서, 픽셀 수준의 시각적 증거에 근거(grounding)해 답을 만든다는 점이다.
정확히는 모델이 작은 글자, 멀리 있는 표지판, 부품 시리얼 같은 미세 디테일을 놓쳤을 때 추측으로 메우는 대신, "확인 가능한 절차"를 밟도록 설계된 흐름이다.
한 줄 요약/결국 뭐냐
Agentic Vision은 ‘이미지를 그냥 읽는 것’이 아니라, 필요하면 도구(코드 실행 등)로 확대/크롭/측정/카운트/추출을 반복해 증거 기반으로 답을 만드는 에이전트식 비전이다.
즉, 단순히 이미지 분석 성능이 좋아졌다기보다, 분석을 “절차적으로 수행하게 만드는 동작 방식(워크플로/기능)”이 추가된 것이다.
그 결과 작은 글자·카운팅·표/차트처럼 실수·환각이 나기 쉬운 구간에서 확인 가능한 근거(grounding)를 강화해 정확도를 끌어올린다.
작동 방식(Think-Act-Observe 루프)
Think 단계에서 모델은 사용자의 질의와 초기 이미지를 함께 보고, 어떤 정보를 어떤 순서로 확인할지 다단계 계획을 세운다. 이때 "어디를 확대할지", "무엇을 세거나 측정할지", "표에서 어떤 값을 뽑을지" 같은 작업 단위로 쪼개는 것이 포인트다.
Act 단계에서 모델은 파이썬 코드를 생성·실행해 이미지를 직접 다룬다. 예를 들어 줌/크롭/회전 같은 변환을 하거나, 바운딩 박스를 그려 객체를 세고, 특정 영역의 텍스트를 확인하는 식으로 "조작과 분석"을 수행한다.
Observe 단계에서 Act의 결과로 나온 변환 이미지(예: 크롭된 패치, 주석이 그려진 캔버스, 변환된 그림)가 모델의 컨텍스트에 추가된다. 모델은 이 새 이미지를 다시 관찰해 다음 추론 단계에 사용하고, 필요하면 Think-Act-Observe를 반복한 뒤 최종 답을 낸다.

핵심 기능과 기대 효과
미세 디테일 자동(암묵적) 줌이 가장 대표적이다. 모델이 이미지에서 작은 글자나 세부 표식을 "정확도 리스크"로 감지하면, 별도 지시 없이도 확대·크롭을 통해 확인하는 행동이 잘 트리거되도록 학습되어 있다고 설명한다.
이미지 주석(visual scratchpad)은 카운팅과 로컬라이징 오류를 줄이는 방향의 기능이다. 단순히 "손가락이 다섯 개"라고 말하는 대신, 모델이 파이썬으로 박스와 라벨을 그려가며 어떤 픽셀을 무엇으로 셌는지를 스스로 고정해 둔다. 이 방식은 "세다가 하나 빼먹는" 류의 실수를 줄이는 데 직관적으로 유리하다.
시각적 수학·표/차트 처리는 "모델의 확률적 추론"이 흔들리기 쉬운 구간을, "검증 가능한 실행"으로 치환한다는 의미가 있다. 고밀도 표에서 값을 추출한 뒤 정규화·계산을 파이썬으로 수행하고, 필요하면 Matplotlib 같은 방식으로 플로팅까지 해 결과를 확인 가능한 형태로 만든다. 다단계 시각 산술에서 발생하는 환각을 줄이기 위한 설계다.
품질 측면에서는 코드 실행을 활성화했을 때, 비전 벤치마크 전반에서 5~10%의 일관된 품질 향상이 있었다는 발표 수치가 제시됐다.
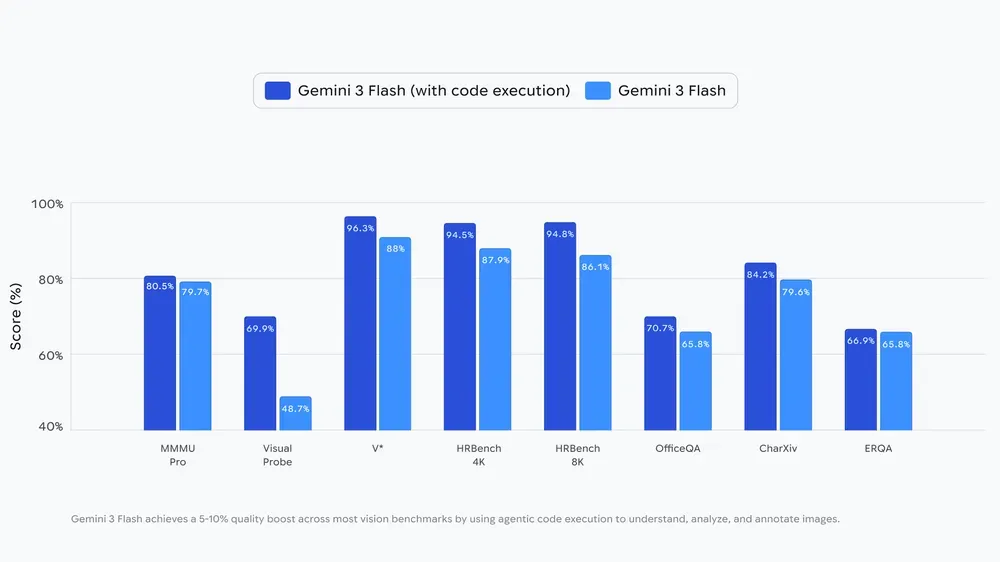
어디서 쓰나
개발자 관점에서는 Gemini API에서 사용 가능하며, Google AI Studio와 Vertex AI에서 제공된다고 안내되어 있다. AI Studio에서는 Tools에서 "Code Execution"을 켜서 실험하거나 데모 앱으로 동작을 확인하는 흐름을 제시한다.
사용자 제품 측면에서는 Gemini 앱에서도 일부 롤아웃이 시작됐고, 모델 선택에서 'Thinking'을 선택하는 방식으로 접근한다고 설명한다.
의미와 주의점(한계/로드맵)
현재 강점은 "줌을 언제 할지"를 비교적 암묵적으로 잘 결정한다는 점이다. 반면 회전, 시각 수학 같은 다른 코드 기반 행동은 상황에 따라 프롬프트로 "이 도구를 써서 확인하라"는 식의 유도가 필요할 수 있다고 공개적으로 언급한다. 즉, 에이전트 루프가 항상 자동으로 최적 행동을 다 수행한다고 가정하기보다는, 필요한 경우 사용자가 확인 절차를 요청하는 편이 안전하다.
로드맵으로는 더 많은 도구(예: 웹 검색, 역이미지 검색)를 붙여 grounding을 강화하는 방향, 그리고 Flash 외의 다른 모델 크기로 확장하는 계획이 공개돼 있다. 또한 줌 외의 행동들도 점점 더 암묵적으로 발동되도록 개선해 나가겠다는 메시지다.
참고
이 노트는 요약·비평·학습 목적으로 작성되었습니다. 저작권 문의가 있으시면 에서 알려주세요.