
LLM(Large Language Model) 처음부터 만들기 학습 노트
파인만 기법으로 배우는 LLM의 핵심 원리
LLM을 처음부터 만들어 보기!
1. LLM의 핵심 개념
LLM이 하는 일을 한 문장으로 말하면: "다음 토큰 예측"이 전부입니다.
"오늘 날씨가 정말 ___" 이라는 문장이 있으면, 모델은 "좋다", "덥다", "춥다" 같은 단어가 올 확률을 계산합니다. 이걸 수십억 번 반복 학습하면, 결국 문맥을 이해하고 적절한 응답을 생성하는 것처럼 보이게 됩니다.
2. LLM의 전체 구조
입력부터 출력까지의 흐름:
토큰화: "오늘" → [5, 12] (글자에 번호표 붙이기)
임베딩: [5, 12] → [[0.2, -0.5, ...], [0.8, 0.1, ...]] (숫자를 의미 있는 벡터로)
Transformer 블록 통과: 단어들이 서로 정보 교환 (여러 번 반복)
출력: 다음 토큰 확률 계산 → "좋" 30%, "춥" 25%, "덥" 20%...
샘플링: 확률에 따라 하나 선택 → 이어붙이고 반복
3. 핵심 개념 상세 설명
3.1 토큰화 vs 임베딩
토큰화: 글자 → 숫자 (ID만 붙임, 의미 없음)
임베딩: 숫자 → 의미 있는 벡터 (비슷한 단어는 비슷한 벡터)
3.2 Q, K, V (Attention)
도서관에서 책 찾는 것에 비유:
Q (Query, 질문): "파이썬 프로그래밍 관련 책 찾고 싶어"
K (Key, 열쇠): 각 책의 라벨/태그 ("요리", "역사", "파이썬"...)
V (Value, 값): 책의 실제 내용
과정: Q와 K를 비교 → 관련 높은 책 찾기 → 그 책의 V(내용) 가져오기
3.3 Head (Multi-Head Attention)
Head는 "관점" 또는 "눈" 하나입니다. 여러 눈으로 다양한 패턴을 파악합니다:
눈 1: 문법을 봄 (주어-동사 관계)
눈 2: 의미를 봄 (고양이-생선 관계)
눈 3: 거리를 봄 (가까운 단어)
눈 4: 다른 패턴...
3.4 Transformer Block
레고 조각처럼 같은 구조를 반복해서 쌓습니다:
Self-Attention (단어들이 서로 정보 교환)
Add & Normalize (안정화)
Feed Forward (정보 처리/변환)
Add & Normalize (안정화)
블록을 많이 쌓을수록: 1-2층 = 단순 문법, 10-20층 = 문장 관계, 50층+ = 복잡한 추론
3.5 잔차 연결 (Residual Connection)
코드: x = x + attention(x)
잔차의 의미: "남은 것", 즉 원본과의 차이
일반 방식: 완전히 새로운 결과 만들기 (어려움)
잔차 방식: 원본 + 차이만 학습 (쉬움, 원본 보존)왜 필요한가? 레이어가 깊어지면 원본 정보가 사라집니다. 잔차 연결은 "고속도로"를 만들어 원본 정보를 보존합니다.
일반: 서울 → 대전 → 대구 → 부산 (중간에 막히면 끝)
잔차: 서울 → 부산 직통 고속도로 + 중간 경유지
4. 학습 vs 예측
4.1 학습 (Training)
흐름: 입력 → 모델 → 예측 → 정답 비교 → 모델 수정
다음 글자 맞추기 게임을 수십억 번 반복합니다:
x (입력): "오늘날씨가좋"
y (정답): "늘날씨가좋다" (한 칸 뒤)
모델이 예측한 것과 y를 비교해서 틀린 정도(loss)를 줄이는 방향으로 학습
4.2 예측 (Inference)
흐름: 입력 → 모델 → 예측 → 출력 (정답 비교 없음)
한 토큰씩 생성해서 이어붙입니다:
"날씨" → 모델 → "가" 선택 → "날씨가"
"날씨가" → 모델 → " " 선택 → "날씨가 "
"날씨가 " → 모델 → "좋" 선택 → "날씨가 좋"
... 반복 ...
핵심 차이: 모델을 통과하는 과정은 동일. 학습은 정답과 비교해서 모델을 수정하고, 예측은 그냥 출력합니다.
5. 핵심 코드 구조 (PyTorch)
5.1 토큰화
char_to_idx = {ch: i for i, ch in enumerate(chars)}
encode = lambda s: [char_to_idx[c] for c in s]5.2 임베딩
self.token_embedding = nn.Embedding(vocab_size, n_embed)
self.position_embedding = nn.Embedding(block_size, n_embed)5.3 Self-Attention
Q = self.query(x) # 질문
K = self.key(x) # 열쇠
V = self.value(x) # 값
scores = Q @ K.transpose(-2, -1) # 유사도
attention = softmax(scores)
out = attention @ V # 가중 합5.4 Transformer Block
x = x + self.attention(self.ln1(x)) # 잔차 연결
x = x + self.ff(self.ln2(x)) # 잔차 연결5.5 학습 루프
logits, loss = model(xb, yb) # 예측 & 손실 계산
loss.backward() # gradient 계산
optimizer.step() # 파라미터 업데이트5.6 텍스트 생성
logits, _ = model(idx) # 모델 통과
probs = softmax(logits[:, -1, :]) # 마지막 위치 확률
idx_next = multinomial(probs) # 샘플링
idx = cat((idx, idx_next)) # 이어붙이기ㅈ전체 코드
import torch
import torch.nn as nn
import torch.nn.functional as F
# GPU 사용
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"Using: {device}")
# ============ 1. 데이터 준비 ============
# 간단한 한글 텍스트 (실제론 더 많은 데이터 필요)
text = """
오늘 날씨가 좋다. 하늘이 맑고 바람이 시원하다.
내일도 날씨가 좋을 것 같다. 기분이 좋아진다.
날씨가 좋으면 산책을 하고 싶다. 공원에 가고 싶다.
하늘이 파랗고 구름이 예쁘다. 정말 좋은 날이다.
"""
# 글자 단위 토큰화
chars = sorted(list(set(text)))
vocab_size = len(chars)
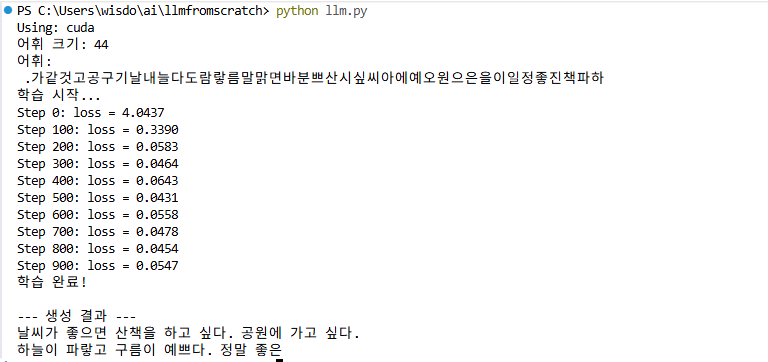
print(f"어휘 크기: {vocab_size}")
print(f"어휘: {''.join(chars)}")
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
encode = lambda s: [char_to_idx[c] for c in s]
decode = lambda l: ''.join([idx_to_char[i] for i in l])
data = torch.tensor(encode(text), dtype=torch.long, device=device)
# ============ 2. 모델 정의 ============
class Head(nn.Module):
"""하나의 Attention Head"""
def __init__(self, head_size):
super().__init__()
self.query = nn.Linear(n_embed, head_size, bias=False)
self.key = nn.Linear(n_embed, head_size, bias=False)
self.value = nn.Linear(n_embed, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
def forward(self, x):
B, T, C = x.shape
q = self.query(x)
k = self.key(x)
v = self.value(x)
# Attention 계산
scores = q @ k.transpose(-2, -1) * (C ** -0.5)
scores = scores.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
attention = F.softmax(scores, dim=-1)
out = attention @ v
return out
class MultiHeadAttention(nn.Module):
"""여러 Head를 병렬로"""
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(n_embed, n_embed)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
return self.proj(out)
class FeedForward(nn.Module):
def __init__(self, n_embed):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embed, 4 * n_embed),
nn.GELU(),
nn.Linear(4 * n_embed, n_embed),
)
def forward(self, x):
return self.net(x)
class Block(nn.Module):
"""Transformer Block"""
def __init__(self, n_embed, n_head):
super().__init__()
head_size = n_embed // n_head
self.attention = MultiHeadAttention(n_head, head_size)
self.ff = FeedForward(n_embed)
self.ln1 = nn.LayerNorm(n_embed)
self.ln2 = nn.LayerNorm(n_embed)
def forward(self, x):
x = x + self.attention(self.ln1(x))
x = x + self.ff(self.ln2(x))
return x
class MiniLLM(nn.Module):
def __init__(self):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, n_embed)
self.position_embedding = nn.Embedding(block_size, n_embed)
self.blocks = nn.Sequential(*[Block(n_embed, n_head) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embed)
self.lm_head = nn.Linear(n_embed, vocab_size)
def forward(self, idx, targets=None):
B, T = idx.shape
tok_emb = self.token_embedding(idx)
pos_emb = self.position_embedding(torch.arange(T, device=device))
x = tok_emb + pos_emb
x = self.blocks(x)
x = self.ln_f(x)
logits = self.lm_head(x)
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
for _ in range(max_new_tokens):
idx_cond = idx[:, -block_size:]
logits, _ = self(idx_cond)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
return idx
def generate_verbose(model, idx, max_new_tokens):
print("시작:", decode(idx[0].tolist()))
print("-" * 40)
for step in range(max_new_tokens):
idx_cond = idx[:, -block_size:]
logits, _ = model(idx_cond)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
new_char = decode([idx_next[0].item()])
current_text = decode(idx[0].tolist())
print(f"{step+1}회: +'{new_char}' → {current_text}")
return idx
# ============ 3. 하이퍼파라미터 ============
block_size = 32 # 한 번에 보는 글자 수
n_embed = 64 # 임베딩 차원
n_head = 4 # Attention Head 수
n_layer = 4 # Transformer Block 수
batch_size = 16
learning_rate = 1e-3
max_iters = 1000
# ============ 4. 학습 ============
model = MiniLLM().to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
# 배치 생성 함수
def get_batch():
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
return x, y
# 학습 루프
print("학습 시작...")
for iter in range(max_iters):
xb, yb = get_batch()
logits, loss = model(xb, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if iter % 100 == 0:
print(f"Step {iter}: loss = {loss.item():.4f}")
print("학습 완료!")
# ============ 5. 텍스트 생성 ============
print("\n--- 생성 결과 ---")
context = torch.tensor([encode("날씨")], device=device)
generated = model.generate(context, max_new_tokens=50)
print(decode(generated[0].tolist()))실행 결과
6. 복습 퀴즈
LLM이 하는 일을 한 문장으로?
토큰화와 임베딩의 차이는?
Q, K, V를 도서관 비유로 설명하면?
Head를 여러 개 쓰는 이유는?
잔차 연결이 필요한 이유는?
학습과 예측의 차이는?
Transformer Block을 여러 개 쌓으면 왜 더 똑똑해지나?
정답
다음 토큰 예측
토큰화는 숫자만 매김, 임베딩은 의미 있는 벡터로 변환
Q는 찾고자 하는 것, K는 책의 태그, V는 실제 값
여러 눈으로 다양한 패턴을 파악하기 위해
레이어가 깊어지면 원본 정보가 사라지므로 원본 보존
학습은 모델 수정, 예측은 다음 토큰 출력
여러 층에서 더 복잡하고 추상적인 패턴을 이해
7. 다음 학습 단계
Andrej Karpathy의 "Let's build GPT from scratch" 유튜브 시리즈
nanoGPT GitHub 코드 직접 실행해보기
Hugging Face NLP Course
Transformer 원 논문 "Attention Is All You Need" 읽기