
Unsloth: 오픈 소스 LLM 파인튜닝 및 강화학습 프레임워크 완전 정리
개요
Unsloth는 대규모 언어 모델(LLM)을 빠르고 메모리 효율적으로 파인튜닝하고, 강화학습(RL)까지 수행할 수 있도록 해주는 오픈 소스 프레임워크이다.12 특히 GPU 연산을 직접 최적화한 커스텀 커널을 사용해 동일한 하드웨어에서 더 빠른 학습 속도와 더 적은 VRAM 사용량을 달성하는 것이 핵심 목표다.13

사용자는 Google Colab, Kaggle과 같은 무료 환경이나 개인 GPU 머신에서, Llama, Gemma, Qwen, DeepSeek, gpt-oss 등 다양한 오픈 모델을 손쉽게 파인튜닝할 수 있으며, RL 기반 추론/추론강화(Reinforcement Learning for Reasoning, GRPO 등)까지 상대적으로 적은 자원으로 시도할 수 있다.23 또한 기업 환경을 위한 Pro·Enterprise 에디션을 통해 멀티 GPU·멀티 노드 확장 및 추가적인 최적화 기능도 제공한다.1
Unsloth란 무엇인가?
Unsloth는 "파인튜닝과 강화학습을 최대한 싸고 빠르게"라는 문제의식에서 출발한 프레임워크로, 기존 Hugging Face Transformers 기반 학습을 대체하거나 가속하는 역할을 한다.23 핵심은 GPU 연산에서 병목이 되는 수학 연산 단계들을 수동으로 미분·전개하고, 이를 커스텀 GPU 커널(주로 Triton 등)로 구현해 학습 속도를 극대화한다는 점이다.12
공식 웹사이트와 GitHub 저장소는 모두 오픈 소스 버전을 중심으로 제공되며, 누구나 pip install unsloth로 설치해 활용할 수 있다.12 오픈 소스 버전 외에도 상용 Pro·Enterprise 플랜이 별도로 존재해, 보다 큰 규모의 학습 워크로드를 가지는 기업 고객을 대상으로 한다.1
전체 구조와 철학
Unsloth의 철학은 크게 세 가지로 요약할 수 있다. 첫째, "하드웨어를 바꾸지 않고 소프트웨어만으로 성능을 끌어올린다"는 것이다. 개발팀은 복잡한 수학 연산을 직접 풀어 GPU 커널로 최적화하는 방식으로 FA2(FlashAttention 2) 대비 최대 30배까지 빠른 학습 성능과 90%에 달하는 메모리 절감 효과를 주장한다.1
둘째, "모든 사람이 쉽게 쓸 수 있는 파인튜닝 도구"를 지향한다. 이를 위해 Colab·Kaggle용 노트북을 풍부하게 제공하고, 사용자는 데이터셋만 넣으면 대부분의 설정이 잡힌 상태로 학습을 실행할 수 있다.2 셋째, "친환경·비용 절감"이다. 동일한 작업을 더 적은 연산과 VRAM으로 처리함으로써 전력 소비와 클라우드 비용을 줄이겠다는 목표를 내세운다.1
Unsloth UI·로고 이미지

주요 특징 개요
Unsloth의 대표적인 특징은 "속도·메모리·지원 범위" 세 축으로 설명할 수 있다. 속도 측면에서는 FA2 대비 단일 GPU에서 10배, 멀티 GPU에서 최대 30배까지 빠른 학습을 목표로 한다고 소개한다.1 GitHub 기준으로는 gpt-oss, Qwen, Gemma, Llama 등의 실제 모델 파인튜닝에서 1.5~2배 속도 향상과 50~80% VRAM 절감 수치를 예시로 제시하고 있다.2
메모리 측면에서는 4비트·8비트·16비트 LoRA, Dynamic 4-bit Quantization, 양자화 인지 학습(Quantization-Aware Training, QAT) 등 다양한 양자화 기법을 통합해, 고용량 모델을 더 작은 VRAM에 올릴 수 있도록 돕는다.2 지원 범위 측면에서는 텍스트 LLM뿐 아니라 TTS, STT, BERT, Mamba, 비전·멀티모달(VLM) 모델, 롱 컨텍스트 모델(예: 500K 토큰 컨텍스트)까지 폭넓게 지원하는 것이 특징이다.2
지원 모델과 기능
Unsloth는 최신 오픈 모델들을 폭넓게 지원한다. GitHub와 공식 문서에 따르면 gpt-oss(OpenAI의 오픈 모델 계열), DeepSeek-R1, Qwen3, Gemma 3 및 Gemma 3n, Llama 3.x/4, Phi-4, Mistral/Ministral 3 등 주요 LLM 계열이 포함된다.2 또 Llama 3.2 Vision, Qwen3-VL 같은 비전·멀티모달 모델, Orpheus-TTS, Whisper 기반 STT 모델 등 음성 관련 모델도 지원 목록에 올라 있다.2
웹사이트의 가격 플랜 설명에서도 Mistral, Gemma, Llama 1·2·3, 그리고 4비트·16비트 LoRA 등의 지원이 명시되어 있으며, 오픈 소스 버전에서 멀티 GPU 지원은 "coming soon" 상태로 안내되어 있다.1 Enterprise 플랜에서는 멀티 노드 환경에서의 풀 파인튜닝, 30배 수준의 속도 향상, 정확도 최대 30% 향상, 추론 5배 속도 향상 등을 목표로 하고 있다고 소개한다.1
또한 강화학습 측면에서는 GRPO·GSPO 등 추론 강화를 위한 알고리즘을 지원하며, 비전 모델에 대한 RL, 메모리 효율적 RL, FP8 기반 RL 등 최신 기법도 빠르게 통합하는 경향을 보인다.23
성능과 최적화 기술
Unsloth는 "수작업 미분 + 수동 GPU 커널 튜닝"이라는 다소 하드코어한 접근을 취한다. 공식 사이트에 따르면 연산량이 큰 수학 연산들을 사람 손으로 직접 유도한 뒤, 이를 GPU 커널로 구현함으로써, 동일한 GPU에서도 더 적은 연산·메모리 접근으로 학습을 진행할 수 있도록 설계했다.1
GitHub와 블로그에서는 RoPE·MLP용 Triton 커널, 패딩 프리(padding free)·packing 기법, 새로운 Dynamic 2.0·4비트 양자화, 500K 이상의 롱 컨텍스트 학습, 메모리 절약형 RL 알고리즘 등 다양한 최적화 기법을 발표하고 있다.2 이들 기술의 조합을 통해, 예를 들어 20B급 모델을 14GB VRAM에서 돌리거나, 80GB GPU에서 50만 토큰 이상의 컨텍스트를 가진 모델을 학습하는 시연이 보고된다.2
NVIDIA의 공식 블로그에서도 Unsloth를 "NVIDIA GPU에서 메모리 효율적인 LLM 파인튜닝을 제공하는 대표적인 오픈 소스 프레임워크"로 소개하며, RTX 50 시리즈 데스크톱부터 DGX Spark까지 다양한 GPU에서 Hugging Face Transformers 대비 2.5배 성능 향상을 보여준다고 평가한다.3 이 글에서는 Unsloth가 복잡한 수학 연산을 효율적인 GPU 커널로 변환해 VRAM 사용량을 줄이는 방식과, 다양한 파인튜닝 시나리오별 VRAM 요구량을 도표로 정리하고 있다.3
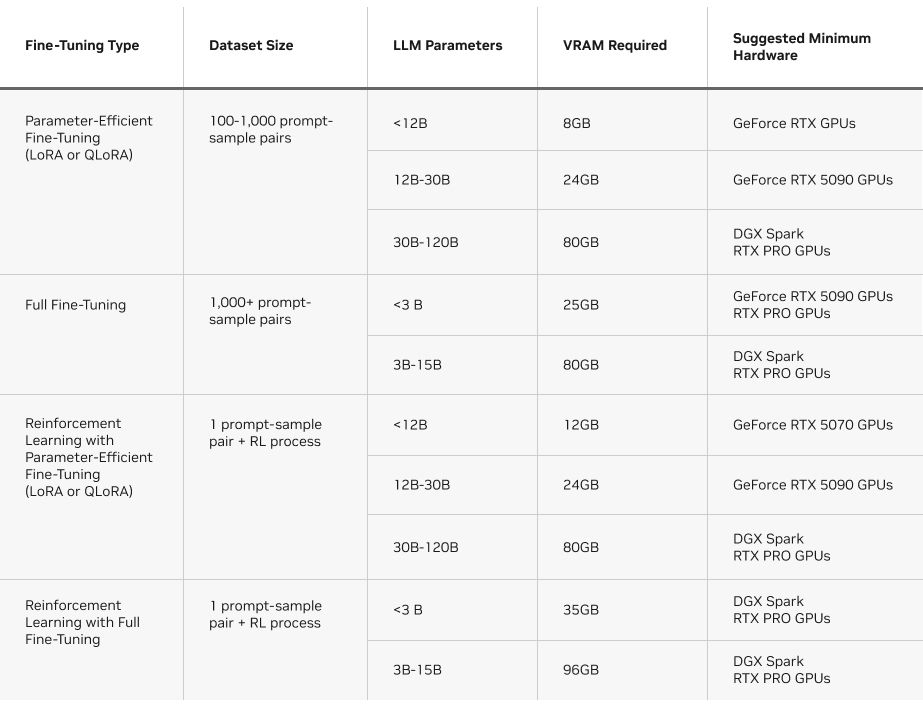
파인튜닝 방식: LoRA, 풀 파인튜닝, 강화학습
NVIDIA 블로그와 Unsloth 문서는 파인튜닝 방식을 LoRA/QLoRA 같은 파라미터 효율적 파인튜닝(PEFT), 전체 파라미터를 조정하는 풀 파인튜닝, 그리고 강화학습(RL)으로 구분해 설명한다.3
LoRA·QLoRA 방식은 모델의 일부(저랭크 어댑터 파라미터)만 학습해 속도가 빠르고 VRAM 요구량이 낮으며, 100~1,000개 정도의 프롬프트-응답 쌍 데이터셋으로도 효과를 얻을 수 있는 것으로 설명된다.3 반면 풀 파인튜닝은 모든 파라미터를 업데이트하므로 훨씬 많은 데이터와 VRAM을 요구하지만, 모델의 스타일·형식·행동 방식을 깊게 바꾸고 싶을 때 사용한다.3
강화학습은 보상 모델과 환경을 구성해, 모델이 상호작용을 통해 성능을 끌어올리는 방식이다. Unsloth는 GRPO 기반 추론 강화, 비전 RL, FP8 RL 등 다양한 RL 시나리오에 최적화된 커널과 알고리즘을 제공하며, 메모리 효율적 RL 기법으로 VRAM을 절반 수준까지 줄이면서도 컨텍스트 길이는 10배 늘릴 수 있다고 주장한다.23
설치와 사용 개요
설치는 비교적 단순하다. Linux/WSL 환경에서는 pip install unsloth 명령으로 설치할 수 있고, Windows에서는 PyTorch가 먼저 설치되어 있어야 한다는 제약이 있다.2 Windows 사용자를 위해서는 별도의 설치 가이드가 제공되며, Docker 이미지를 통해 손쉽게 통합 환경을 사용할 수도 있다.2
Colab·Kaggle 노트북은 초보자도 따라 하기 쉽게 구성되어 있다. 예를 들어 gpt-oss 20B 모델용 파인튜닝 노트북에서는 데이터셋 업로드, 하이퍼파라미터 설정, 학습 실행, 학습된 모델을 GGUF·llama.cpp·Ollama·vLLM·SGLang·Hugging Face로 내보내는 과정까지 한 번에 안내한다.2 사용자는 자신의 데이터셋과 약간의 설정만 바꾸면, 같은 노트북으로 다른 도메인 모델을 쉽게 학습시킬 수 있다.
또한 Unsloth는 Docker Hub에 공식 이미지를 제공해, 의존성 문제를 줄이고 곧바로 컨테이너 환경에서 학습을 실행할 수 있도록 한다.2 NVIDIA DGX Spark나 RTX 50 시리즈 GPU에 맞춘 별도의 가이드도 존재해, 이들 플랫폼에서 최적의 설정으로 파인튜닝을 수행하는 방법을 단계별로 안내한다.23
하드웨어 요구사항과 로컬 LLM 머신
Unsloth는 "적은 VRAM으로 큰 모델을 돌리기"에 특화되어 있지만, 여전히 LLM 파인튜닝 작업 자체는 메모리·연산 집약적인 워크로드이다. Hugging Face 포럼에서도 로컬 LLM 머신을 구축하려는 사용자가, 통합 메모리를 많이 가진 시스템과 전통적인 고용량 VRAM GPU 시스템 사이에서 고민하는 내용이 논의된다.4 이 스레드에서는 NVIDIA DGX Spark 같은 고가 장비가 메모리 면에서는 매력적이지만, 가격 대비 효율 측면에서 고민이 필요하다는 점이 언급된다.4
Unsloth 공식 문서(링크는 포럼에서 인용됨)는 각 모델·파인튜닝 방식별 VRAM 요구량을 정리해, 어떤 GPU에서 어떤 방식의 파인튜닝이 가능한지 참고할 수 있도록 하고 있다.4 예를 들어 8~14GB 범위의 일반 소비자용 GPU에서는 소형 모델의 LoRA·QLoRA 파인튜닝과 일부 RL 시나리오를, 24GB 이상 GPU나 DGX Spark급 통합 메모리 환경에서는 30B 이상 모델의 풀 파인튜닝과 고난도 RL이 가능하다고 안내한다는 맥락이다.34
에디션과 가격 구조
Unsloth는 크게 무료 오픈 소스 버전, Pro, Enterprise 세 가지 라인업을 제공한다.1
무료 버전은 GitHub에서 소스 코드와 함께 제공되며, Llama 1·2·3, Gemma, Mistral 등의 모델과 4비트·16비트 LoRA를 지원한다.1 단일 GPU에서 2배 빠른 파인튜닝을 무료로 경험해 볼 수 있고, MultiGPU 기능은 "곧 제공 예정"으로 표기되어 있다.1
Pro 버전은 오픈 소스 대비 약 2.5배 빠른 학습 속도와 20% 적은 VRAM 사용을 내세우며, 최대 8개의 GPU를 활용하는 확장된 멀티 GPU 지원을 제공한다.1 Enterprise 버전은 더욱 극단적인 최적화를 통해 FA2 대비 32배까지 빠른 속도, 최대 30% 정확도 향상, 5배 빠른 추론, 멀티 노드 지원, 고객 지원 등을 포함하는 것으로 소개된다.1
활용 사례와 사용 시나리오
Unsloth는 다음과 같은 상황에서 특히 유용하다.
먼저, 제한된 예산의 개인·소규모 팀이 오픈 소스 LLM을 자신의 도메인에 맞게 파인튜닝하고 싶을 때 적합하다. Colab·Kaggle 노트북과 낮은 VRAM 요구량 덕분에 클라우드 고가 GPU 인스턴스를 오래 빌리지 않고도 실험을 진행할 수 있다.2
둘째, RTX 50 시리즈 같은 최신 소비자용 GPU나 NVIDIA DGX Spark와 같은 고급 워크스테이션을 이미 보유한 경우, Unsloth는 해당 하드웨어에서 LLM 파인튜닝을 매우 효율적으로 수행하기 위한 최적화 도구가 된다.3 NVIDIA는 공식 블로그에서, 제품 지원 챗봇이나 개인 비서형 에이전트 등 특화된 에이전트를 만들기 위해 Unsloth를 활용하는 예시를 소개하고 있다.3
셋째, 강화학습 기반 추론 모델을 로컬에서 실험하고 싶은 연구자·파워유저에게도 유리하다. GRPO·GSPO, 비전 RL, FP8 RL 등 최신 기법이 제공되는 만큼, RL 알고리즘 실험과 모델 행동 최적화를 비교적 적은 자원으로 반복해 볼 수 있다.2
장단점 및 한계
장점으로는 무엇보다도 우수한 속도·메모리 효율이 꼽힌다. FA2 대비 수십 배까지 빠른 성능과 큰 폭의 VRAM 절감은, 같은 예산으로 더 많은 실험을 할 수 있게 해 준다.12 또한 다양한 노트북·가이드·예제 덕분에 LLM 파인튜닝 초보자도 비교적 쉽게 입문할 수 있다.23
다만, 몇 가지 한계도 존재한다. 첫째, 최신 최적화 기능과 멀티 노드 지원 등은 Enterprise·Pro 버전에서만 제공되는 경우가 있어, 완전히 무료로 모든 기능을 활용하기는 어렵다.1 둘째, Unsloth는 기본적으로 NVIDIA GPU에 최적화되어 있으며, AMD·Intel GPU에 이식 가능하다고는 하지만 실제로는 CUDA 생태계 중심으로 발전하고 있다는 점이 한계로 지적될 수 있다.13 셋째, 매우 최신 모델·기능은 빠르게 추가·변경되기 때문에, 버전 호환성과 문서를 꼼꼼히 확인해야 한다는 부담도 있다.2
그럼에도 불구하고, Unsloth는 "로컬·온프레미스 LLM 파인튜닝"을 하고자 하는 많은 개발자·연구자에게 사실상 표준 도구 중 하나로 자리잡고 있으며, 특히 NVIDIA GPU 사용자에게는 강력한 선택지로 평가된다.23
참고
1Unsloth AI - Open Source Fine-tuning & RL for LLMs
2GitHub - unslothai/unsloth: Fine-tuning & Reinforcement Learning for LLMs
3How to Fine-Tune an LLM on NVIDIA GPUs With Unsloth
4Unsloth Requirements | Unsloth Documentation (Hugging Face 포럼 링크)
이 노트는 요약·비평·학습 목적으로 작성되었습니다. 저작권 문의가 있으시면 에서 알려주세요.