
GLM 4.7: 최신 코딩 특화 대형 언어 모델 완전 정리
개요
GLM-4.7은 중국 Zhipu AI(Z.ai)가 공개한 최신 플래그십 기초 모델로, 특히 코딩, 추론, 에이전트(Agentic) 워크플로에 초점을 맞춘 버전이다.12 이전 세대인 GLM-4.6 및 GLM-4.5 계열에서 발전해, 다국어 코딩 성능과 복잡한 도구 호출, 장문 맥락 처리 능력, 수학·추론 능력을 크게 향상시킨 것이 특징이다.14

이 모델은 Z.ai 클라우드 API는 물론, 오픈소스 가중치 형태로도 제공되어 Hugging Face와 ModelScope에서 내려받아 로컬에 배포할 수 있다.145 또한 OpenRouter를 통해 서드파티 플랫폼에서도 사용할 수 있어, 상용·연구·개인 프로젝트 어디에서도 유연하게 활용 가능한 범용 코딩 파트너를 지향한다.135
GLM-4.7의 핵심 특징
GLM-4.7의 가장 큰 특징은 "코딩 특화"와 "에이전트 지향"이라는 두 축이다. Z.ai는 이 모델을 "당신의 새로운 코딩 파트너"라고 소개하며, 실제로 SWE-bench, Terminal Bench 같은 코딩·터미널 벤치마크에서 이전 버전 대비 큰 향상을 보였다고 강조한다.14 예를 들어 SWE-bench Verified에서 73.8% (GLM‑4.6 대비 +5.8%p), Terminal Bench 2.0에서 41.0% (+16.5%p)를 기록해 복잡한 리포지터리 기반 버그 수정과 터미널 작업에서 실질적인 성능 개선을 달성했다.14
또 하나의 축은 "생각 모드(Thinking mode)"와 도구 사용 능력이다. GLM-4.7은 Interleaved Thinking, Preserved Thinking, Turn-level Thinking 같은 메커니즘을 통해, 답변을 내기 전에 내부적으로 사고 과정을 거치고, 여러 턴에 걸친 대화에서도 이전의 추론 내용을 재활용하며, 요청 단위로 생각 모드의 온·오프를 제어할 수 있다.14 이는 브라우저 도구(BrowseComp), τ²-Bench 같은 에이전트 벤치마크에서 성능 향상으로 이어지며, 실제 서비스 자동화나 도구 조합 워크플로에 잘 맞도록 설계되어 있다.145
모델 구조와 아키텍처 개요
세부 아키텍처 논문은 GLM-4.5 기술 리포트에 초점을 두고 있지만, GLM-4.7 역시 그 연장선 모델로, 대규모 Mixture-of-Experts(MoE) 구조를 사용하는 것으로 알려져 있다.45 Apidog의 기술 소개에 따르면 GLM-4.7은 3580억(358B) 파라미터 규모의 MoE 아키텍처를 채택하여, 추론 깊이와 표현력을 확보하면서도 활성화되는 전문가 수를 조절해 효율적인 추론을 지향한다.5
컨텍스트 길이는 20만(200K) 토큰 수준으로, 대형 코드베이스나 긴 문서·대화를 한 번에 다루면서도 맥락을 유지할 수 있다.25 이는 대규모 리포지터리 기반 버그 수정, 장문의 기술 문서 분석, 긴 에이전트 세션 관리 등에서 특히 유리하다. 모델은 텍스트 중심이지만, GLM-4.5V·4.6V로 이어지는 계열과 함께 멀티모달 생태계를 구성하며, GLM-4.7도 텍스트·비전 입력을 결합한 멀티모달 워크로드에 맞춰 설계되었다고 외부 평가에서 언급된다.3
성능: 주요 벤치마크 비교
Z.ai와 커뮤니티 자료에서 공개된 벤치마크에 따르면, GLM-4.7은 추론, 코딩, 에이전트 세 가지 영역에서 모두 상위권 성능을 보인다.14
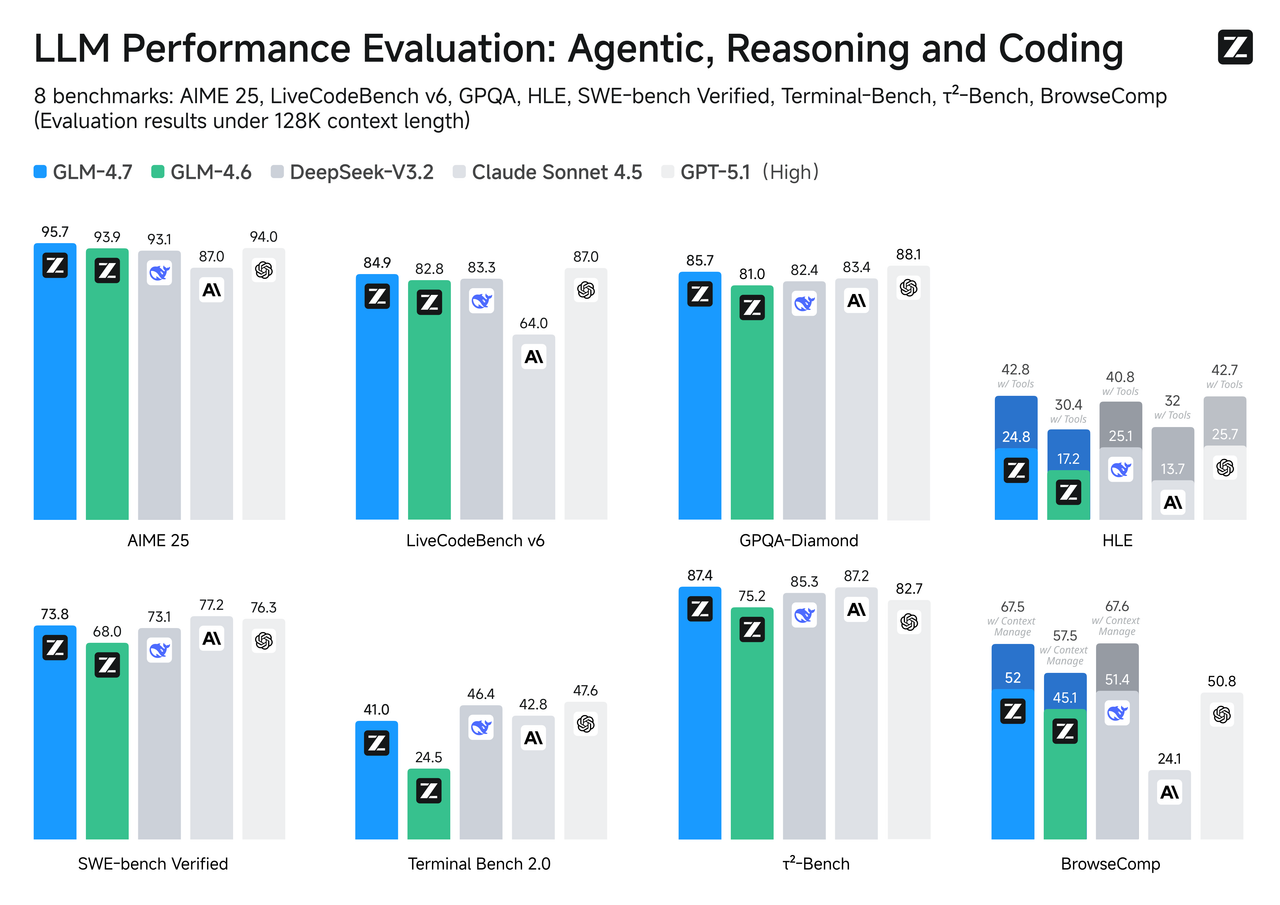
위 그래프와 표에서 볼 수 있듯, GLM-4.7은 MMLU-Pro, GPQA-Diamond 같은 추론·지식 벤치마크, AIME 2025 및 HMMT 등 수학 경진대회 스타일 벤치마크에서 GLM-4.6 및 동급 타 모델보다 개선된 성능을 보인다.14 특히 Humanity's Last Exam(HLE) 벤치마크에서 기본 모드 24.8%, 도구 사용 모드 42.8%로, 전 세대 GLM‑4.6 대비 각각 7.6%p, 12.4%p 상승한 점이 강조된다.14
코딩 영역에서는 LiveCodeBench-v6, SWE-bench Verified, SWE-bench Multilingual, Terminal Bench 계열에서 두드러진 향상을 기록한다.14 예를 들어 SWE-bench Multilingual에서 66.7%로 GLM-4.6의 53.8%보다 크게 올라, 다국어 코드 리포지터리에서 버그를 찾고 수정하는 능력이 강화되었음을 보여준다.14 터미널 상호작용을 평가하는 Terminal Bench 2.0에서도 24.5%에서 41.0%로 상승해, 실제 개발 환경 명령행 작업에서도 성능 개선이 확인된다.14
에이전트·도구 사용 영역에서는 τ²-Bench에서 87.4%, BrowseComp에서 52.0%, 컨텍스트 관리가 포함된 BrowseComp에서는 67.5%를 기록해, 웹 브라우징과 장기 컨텍스트 관리가 필요한 시나리오에서 안정적인 성능을 보여준다.14 이는 단순 답변형 LLM을 넘어, 작업 계획 수립과 도구 조합, 장기 상태 관리에 최적화된 모델이라는 Z.ai의 방향성을 뒷받침한다.13
"생각 모드(Thinking Mode)"와 에이전트 기능
GLM-4.7의 차별점 가운데 하나는 Interleaved Thinking, Preserved Thinking, Turn-level Thinking으로 구성된 "Thinking Mode"이다.14 Interleaved Thinking은 모델이 응답을 생성하기 전에 내부적으로 추론 블록을 거치고, 도구 호출 전에도 마찬가지로 "먼저 생각한 뒤 행동"하도록 하는 방식이다. 이를 통해 지시 사항을 더 잘 따르고, 복잡한 코드 작성·수정 과정에서 실수를 줄이는 효과가 있다.14
Preserved Thinking은 여러 턴에 걸친 코딩 에이전트 시나리오에서, 이전 턴에서 수행한 추론 블록을 유지하고 재사용하는 기능이다.14 일반적인 LLM은 길어진 대화에서 과거 추론 내용을 잊거나 다시 계산하는 경우가 많지만, GLM-4.7은 추론 히스토리를 보존해 장기 작업에서 일관성과 효율성을 높인다. 예를 들어 거대한 리포지터리를 리팩토링하는 에이전트가 수십 번의 수정·실행 사이클을 거칠 때, 이전의 분석 내용을 계속 활용하는 방식이다.14
Turn-level Thinking은 세션 내에서 턴 단위로 생각 모드를 켜고 끄는 기능이다.145 단순 질의에는 생각 모드를 꺼서 지연 시간과 비용을 줄이고, 복잡한 디버깅이나 설계 문제 등에는 생각 모드를 켜서 더 깊은 추론을 수행할 수 있다. Z.ai와 커뮤니티 가이드는 τ²-Bench나 Terminal Bench 2 같은 멀티턴 에이전트 태스크에서는 Preserved Thinking 모드를 켤 것을 권장하고, 일반 대화·코딩에서는 기본 Interleaved Thinking을 활용하는 구성을 제안한다.145
코어 코딩과 "Vibe Coding"
GLM-4.7은 전통적인 의미의 코드 생성뿐 아니라, UI·문서 생성 품질을 포함하는 "코딩 경험 전체"를 개선하는 데 초점을 맞춘다.14 Z.ai는 이를 "코어 코딩(Core Coding)"과 "바이브 코딩(Vibe Coding)"이라는 두 가지 키워드로 설명한다. 코어 코딩은 알고리즘 구현, 버그 수정, 리팩토링, 다국어 코드 이해와 같은 정통 코딩 능력을 의미하며, 앞서 살펴본 SWE-bench, LiveCodeBench 등의 벤치마크 성능이 이를 뒷받침한다.14
반면 Vibe Coding은 사용자가 눈으로 보는 산출물, 즉 웹 페이지, 슬라이드, 포스터 등의 "감각적인 품질"을 강조한다.1 GLM-4.7은 이전 버전에 비해 더 깔끔하고 현대적인 웹 UI를 생성하고, 레이아웃·폰트·색상 조합이 정돈된 슬라이드와 포스터를 만들어낼 수 있도록 튜닝되었다.1 예를 들어 "다크 모드, 굵은 헤딩, 애니메이션 티커, 카테고리 칩, 자기장처럼 끌리는 CTA 버튼이 있는 웹페이지" 같은 복잡한 프런트엔드 요구사항도 단일 프롬프트로 구현하는 사례가 공식 블로그에 소개되어 있다.1
이러한 Vibe Coding 능력은 단순 코드 작성 도우미를 넘어, 기획·디자인·프런트엔드 구현을 한 번에 도와주는 "풀스택 크리에이티브 도구"로서의 활용 가능성을 보여준다.13 실무에서는 프로토타입 웹 페이지, 마케팅 랜딩 페이지, 프레젠테이션 초안 등 시각·구조가 동시에 중요한 작업에 특히 유용하다.
도구 사용과 웹 브라우징 능력
GLM-4.7은 도구 호출(tool calling)과 웹 브라우징을 핵심 기능으로 지원하며, 이는 τ²-Bench, BrowseComp 같은 에이전트 벤치마크에서 높은 점수로 나타난다.145 모델은 OpenAI 스타일의 도구 스키마를 받아, 함수 인자를 자동으로 구성하고, 여러 도구를 순차·병렬적으로 호출하는 시나리오에 최적화되어 있다.45 예를 들어 코드 저장소에서 파일을 읽고, 테스트를 실행하고, 결과를 파싱하는 도구들을 조합해, "테스트를 통과하도록 버그를 수정하라"는 고수준 목표를 단계별로 수행할 수 있다.145
웹 브라우징의 경우, BrowseComp 벤치마크에서 기본 모드 52.0%, 컨텍스트 관리가 포함된 모드에서 67.5%를 기록해, 검색→페이지 탐색→정보 추출→요약 같은 일련의 과정을 비교적 안정적으로 수행할 수 있음을 보여준다.14 특히 BrowseComp-ZH(중국어 환경)에서 66.6%를 기록해, 중국어 웹 환경에서의 정보 수집·이해 능력이 강하다는 점도 특징이다.14
이러한 도구 사용 능력은 기업용 워크플로 자동화, 고객 상담 봇의 후단 시스템 연동, 데이터 파이프라인 제어, 인프라 관리 등 다양한 시나리오에서 GLM-4.7을 "작업을 실제로 수행하는 에이전트"로 활용할 수 있게 해준다.35
API를 통한 GLM-4.7 접근 방법
Z.ai 공식 플랫폼
GLM-4.7에 접근하는 가장 직접적인 방법은 Z.ai 개발자 플랫폼의 API를 사용하는 것이다.125 개발자는 Z.ai 포털에서 계정을 생성한 뒤 API 키를 발급받고, https://api.z.ai/api/paas/v4/chat/completions 엔드포인트로 OpenAI 호환 형식의 요청을 보내면 된다.5 요청 본문에는 model: "glm-4.7", messages 배열과 함께 temperature, max_tokens, thinking(생각 모드 옵션) 등을 지정할 수 있다.5
Apidog 예제에서는 ZaiClient SDK를 사용한 Python 코드가 소개되어 있다.5
from zai import ZaiClient
client = ZaiClient(api_key="your-api-key")
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "Write a Python script for data analysis."}],
thinking={"type": "enabled"},
max_tokens=4096,
temperature=1.0
)
print(response.choices[0].message.content)Z.ai는 스트리밍 응답을 지원하며, 특히 "GLM Coding Plan" 구독 상품을 통해 저렴한 가격(예: 월 3달러 수준의 프로모션)으로 GPT·Claude급 코딩 모델을 사용할 수 있다고 홍보하고 있다.125 Claude Code, Cline 등 여러 코딩 에이전트 툴에서 모델 이름만 glm-4.7로 변경하면 곧바로 연동할 수 있도록 설계되어 있다는 점도 특징이다.12
OpenRouter를 통한 접근
GLM-4.7은 OpenRouter 플랫폼에서도 z-ai/glm-4.7이라는 모델 ID로 제공된다.135 OpenRouter는 여러 제공자(예: Z.ai, AtlasCloud, Parasail)를 통합해 단일 API로 노출하는 서비스로, 동일 모델에 대해 여러 인프라를 선택하거나, 장애 시 자동 폴백을 구성하는 데 유리하다.5
요청은 https://openrouter.ai/api/v1/chat/completions 엔드포인트로 보내며, model: "z-ai/glm-4.7"을 지정한다.5 또한 reasoning: true 옵션을 통해 단계별 사고 과정을 함께 반환하도록 설정할 수 있어, 디버깅이나 연구 용도로 유용하다.5
curl -X POST "https://openrouter.ai/api/v1/chat/completions"
-H "Authorization: Bearer YOUR_OPENROUTER_KEY"
-H "Content-Type: application/json"
-d '{
"model": "z-ai/glm-4.7",
"messages": [{"role": "user", "content": "Explain quantum computing basics."}],
"reasoning": true
}'가격 측면에서, OpenRouter는 제공자별로 토큰 단가가 다르며, 예를 들어 AtlasCloud, Parasail, Z.ai 제공자 간에 입력·출력 단가가 소폭 차이난다.5 장기적으로 Z.ai 생태계에 머물 계획이라면 Z.ai 구독이, 다양한 모델과 제공자를 섞어 쓰고 싶다면 OpenRouter가 더 적합한 선택이 될 수 있다.35
로컬 배포와 실행(Serve GLM-4.7 Locally)
GLM-4.7의 가중치는 Z.ai가 직접 Hugging Face와 ModelScope에 공개하여, 자체 인프라에서 실행할 수 있다.145 Hugging Face에는 zai-org/GLM-4.7 등 공식 리포지토리가 있으며, unsloth 등 커뮤니티에서 GGUF 등 다양한 포맷으로 변환한 버전도 제공한다.4
vLLM과 SGLang은 GLM-4.7을 메인 브랜치에서 지원하며, 도커 이미지 또는 pip 설치를 통해 곧바로 추론 서버를 띄울 수 있다.4 예를 들어 vLLM에서는 다음과 같이 명령을 실행해 OpenAI 호환 서버를 띄울 수 있다.4
vllm serve zai-org/GLM-4.7-FP8
--tensor-parallel-size 8
--tool-call-parser glm47
--reasoning-parser glm45
--enable-auto-tool-choice
--served-model-name glm-4.7-fp8SGLang 역시 유사한 방식으로 추론 서버를 구동하며, 특히 chat_template_kwargs에 enable_thinking: true, clear_thinking: false를 넣어 Preserved Thinking 모드를 활성화할 수 있다.4
"chat_template_kwargs": {
"enable_thinking": true,
"clear_thinking": false
}Transformers 기반 단일 GPU/멀티 GPU 환경에서도 zai-org/GLM-4.7 체크포인트를 불러 실행할 수 있으며, 예제 코드에서는 torch_dtype=torch.bfloat16, device_map="auto" 설정으로 자동 디바이스 할당을 사용한다.4 대규모 배포에서는 vLLM·SGLang과 같은 고성능 서빙 프레임워크를 권장하고, 소규모 실험이나 연구 환경에서는 Transformers 직접 로딩이 유용하다.4
평가·튜닝 시 권장 하이퍼파라미터
GLM-4.7의 공식 가이드와 Hugging Face 페이지에서는 벤치마크 평가에 사용된 대표적인 하이퍼파라미터도 함께 제시한다.14 일반적인 태스크의 기본 설정은 temperature=1.0, top_p=0.95, max_new_tokens=131072이다.14 이는 창의적인 생성과 충분한 길이의 출력이 필요한 대부분의 대화·코딩 작업에 적합한 값이다.
Terminal Bench 및 SWE-bench Verified와 같은 보다 결정적인 코드 평가에서는 temperature=0.7, top_p=1.0, max_new_tokens=16384를 사용해, 출력의 일관성과 재현성을 높였다.14 τ²-Bench의 경우에는 temperature=0, max_new_tokens=16384로 완전히 결정적인 추론을 수행했다.14 실제 서비스 구축 시에도, 코딩·툴 호출처럼 재현성이 중요한 작업에는 낮은 temperature, 크리에이티브 라이팅·아이디어 브레인스토밍에는 높은 temperature를 사용하는 것이 권장된다.145
또한 멀티턴 에이전트 태스크에서는 Preserved Thinking 모드를 켜는 것이 성능 향상에 도움이 된다고 명시되어 있으며, vLLM·SGLang에서 생각 모드를 끄고 싶다면 extra_body={"chat_template_kwargs": {"enable_thinking": False}}와 같은 옵션을 추가해 제어할 수 있다.4
활용 사례와 시사점
GLM-4.7은 "코딩 파트너"라는 포지셔닝답게, 실제 개발 워크플로 전반을 지원하는 데 초점을 맞춘 모델이다. 프런트엔드 UI 작성, 백엔드 API 설계, 테스트 코드 생성, 버그 분석·수정, 성능 튜닝 제안 등 전통적인 프로그래밍 작업은 물론, 문서화·슬라이드 생성·포스터 디자인과 같은 "주변 작업"까지 아우른다.13 특히 Z.ai가 제공하는 Slide/Poster Agent 등과 결합하면, 요구사항 텍스트만으로 발표 자료와 홍보 이미지를 한 번에 생성하는 사용 시나리오도 가능하다.2
기업·연구 관점에서는, 오픈소스 가중치를 제공하면서도 클라우드 API와 상용 플랜을 병행하는 모델이라는 점이 중요하다.1245 규제가 엄격한 환경에서는 로컬 배포로 데이터 프라이버시를 보장하고, 빠르게 실험·배포해야 하는 프로젝트에서는 Z.ai·OpenRouter API를 통해 손쉽게 통합할 수 있다. 테스트카탈로그(TestingCatalog) 같은 외부 매체에서도 GLM-4.7을 "다른 선도 모델들과 경쟁 가능한 수준의 고급 추론·코딩 모델"로 평가하며, 개방형 API 구조와 일관된 출력 품질을 강점으로 언급한다.3
종합하면, GLM-4.7은 GPT·Claude 계열과 경쟁 가능한 오픈소스 친화형 플래그십 모델로, 특히 코딩·에이전트·장문 맥락 처리에 강점을 가진다는 점에서, 2025년 이후 AI 개발 환경에서 중요한 선택지 중 하나로 자리 잡을 가능성이 크다.12345
참고
1GLM-4.7: Advancing the Coding Capability
2New Released - Overview - Z.AI DEVELOPER DOCUMENT
3Z.AI launches GLM-4.7, new SOTA open-source model for coding
이 노트는 요약·비평·학습 목적으로 작성되었습니다. 저작권 문의가 있으시면 에서 알려주세요.