
ADK와 MCP로 만드는 실전 AI 에이전트 도구 모음
핵심 요약
이 글은 ADK와 MCP를 활용해 "진짜로 일을 대신 해주는" 소프트웨어 버그 어시스턴트를 어떻게 구성하는지, 도구 관점에서 단계별로 설명한다. 핵심은 다양한 종류의 도구(Function, Built-in, LangChain, MCP API, MCP DB)를 한 에이전트에 결합해, 검색·분석·데이터베이스 조작까지 자동으로 수행하게 만드는 것이다.
에이전트를 에이전트답게 만드는 것: 도구
AI 에이전트를 일반 챗봇과 구분해 주는 가장 큰 특징은, 단순히 "설명"이 아니라 외부 세계에 실제로 손을 뻗어 행동할 수 있는 능력이다.
이 능력을 제공하는 것이 바로 도구다. 도구는 함수, 데이터베이스, 외부 API, 심지어 다른 에이전트까지 포함할 수 있다.
ADK(Agent Development Kit)는 이런 도구들을 에이전트에 쉽게 연결해 주고, 모델이 언제 어떤 도구를 쓸지 선택하고 응답에 반영할 수 있도록 설계되어 있다.
도구를 적절히 조합하면, "버그가 생겼는데 비슷한 이슈 찾고, 패치 여부 확인하고, 내부 티켓까지 생성해줘" 같은 긴 작업 흐름을 한 번에 처리하는 어시스턴트를 만들 수 있다.
ADK 에이전트의 기본 동작 구조
에이전트가 도구를 사용하는 과정은 크게 세 단계로 생각하면 이해하기 쉽다.
첫째, 도구 선택 단계다. 개발자는 에이전트에 사용할 수 있는 도구 목록과, 각 도구가 어떤 상황에서 유용한지에 대한 설명(시스템 프롬프트)을 제공한다. 사용자의 요청이 들어오면, LLM이 이 정보를 바탕으로 "어떤 도구를 쓸지"를 스스로 결정한다.
둘째, 함수 호출 준비(Function Calling) 단계다. 모델이 직접 네트워크 요청을 보내는 것은 아니고, 각 도구의 입력 형식에 맞게 요청 바디(파라미터)를 구성한다. ADK는 이 구조화된 요청을 받아 실제 도구(함수, API, DB 등)를 대신 호출한다.
셋째, 결과 해석과 후속 행동 단계다. 도구 실행 결과가 들어오면, 모델은 그 내용을 읽고 추가 도구를 더 호출할지, 아니면 사용자의 질문에 답을 반환할지 결정한다.
이 세 단계를 반복하며, 에이전트는 복잡한 버그 분석 흐름을 여러 번의 도구 호출로 이어 붙여 문제를 해결한다.
Function Tool: 가장 단순한 도구
Function Tool은 파이썬 함수 하나를 그대로 도구로 노출하는 방식이다.
예를 들어 "지난 일주일 동안 열린 티켓"을 조회하려면 현재 날짜를 알아야 하므로, 오늘 날짜를 제공하는 도구를 만들 수 있다.
def get_current_date() -> dict:
"""
Get the current date in the format YYYY-MM-DD
"""
from datetime import datetime
return {"current_date": datetime.now().strftime("%Y-%m-%d")}이 도구를 에이전트에 연결해 두면, 모델은 "지난 7일" 같은 인간의 표현을 실제 날짜 범위로 환산할 때 get_current_date를 호출해 정확한 기준일을 얻을 수 있다.
Function Tool의 장점은 구현 난도가 낮고, 계산·포맷팅·간단한 비즈니스 로직 같은 것을 빠르게 캡슐화하기 좋다는 점이다.
Built-in Tool과 "에이전트를 도구로 쓰기"
Built-in Tool은 Google이 제공하는 기능(예: 코드 실행, Google Search)을 ADK에서 바로 쓸 수 있게 한 도구 유형이다.
예를 들어 버그 어시스턴트에 웹 검색 능력을 추가하려면, Google Search를 도구로 붙인 별도의 검색 에이전트를 만들고, 이 에이전트를 다시 "도구처럼" 감싸 메인 에이전트에 연결할 수 있다.
from google.adk.tools import google_search
from google.adk.tools.agent_tool import AgentTool
from google.adk import Agent
search_agent = Agent(
model="gemini-2.5-flash",
name="search_agent",
instruction="You're a specialist in Google Search.",
tools=[google_search],
)
search_tool = AgentTool(search_agent)이렇게 하면 루트 에이전트가 "search_tool" 하나만 알면 되고, 실제 검색 전략이나 결과 정리는 검색 에이전트에 위임할 수 있다.
이 패턴은 복잡한 작업을 하위 에이전트로 분리하고, 상위 에이전트에서는 단순히 "검색 전문가 도구" 정도로만 취급하게 만드는 설계에 유용하다.
LangChain Tool: 서드파티 API를 빠르게 붙이는 방법
이미 LangChain에서 구현된 다양한 서드파티 도구를 재사용하면, 매번 API 클라이언트를 직접 짤 필요가 없다.
예를 들어 StackOverflow의 Q&A를 활용해 버그 해결 힌트를 얻고 싶다면, LangChain의 StackExchange 도구를 그대로 ADK에 연결할 수 있다.
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import StackExchangeTool
from langchain_community.utilities import StackExchangeAPIWrapper
stack_exchange_tool = StackExchangeTool(
api_wrapper=StackExchangeAPIWrapper()
)
langchain_tool = LangchainTool(stack_exchange_tool)이제 버그 어시스턴트는 "에러 메시지를 설명해줘" 같은 요청을 받았을 때, StackOverflow에서 유사한 질문과 답변을 검색해 요약·적용할 수 있다.
LangChain Tool의 강점은 기존에 잘 만들어진 도구 생태계를 그대로 재활용하면서도, ADK의 도구 호출 체계 안에 자연스럽게 편입된다는 점이다.
MCP: 에이전트와 도구 사이의 공통 언어
MCP(Model Context Protocol)는 에이전트와 도구 서버 사이의 표준 프로토콜로, 여러 종류의 API/DB를 하나의 통일된 방식으로 연결할 수 있게 해준다.
MCP의 핵심 아이디어는 다음과 같다. 도구 제공자는 API 위에 MCP 서버를 만들면서, 자체적인 "툴 정의"와 에러형식을 제공한다. 에이전트 쪽에서는 MCP 클라이언트만 구현하면, 서버가 제공하는 모든 툴을 자동으로 발견하고 호출할 수 있다.
이 구조 덕분에, 개발자는 각각의 백엔드(API, DB)마다 별도의 클라이언트 코드를 작성할 필요 없이, 한 번 MCP 클라이언트를 붙여 놓으면 다양한 도구를 "플러그인처럼" 쓸 수 있다.
MCP는 HTTP와 달리 상태를 유지하는 양방향 연결을 지원해, 도구 목록 협상, 스트리밍 응답 등 에이전트 친화적인 기능을 제공한다.
다음 다이어그램은 MCP 구조를 직관적으로 보여준다.
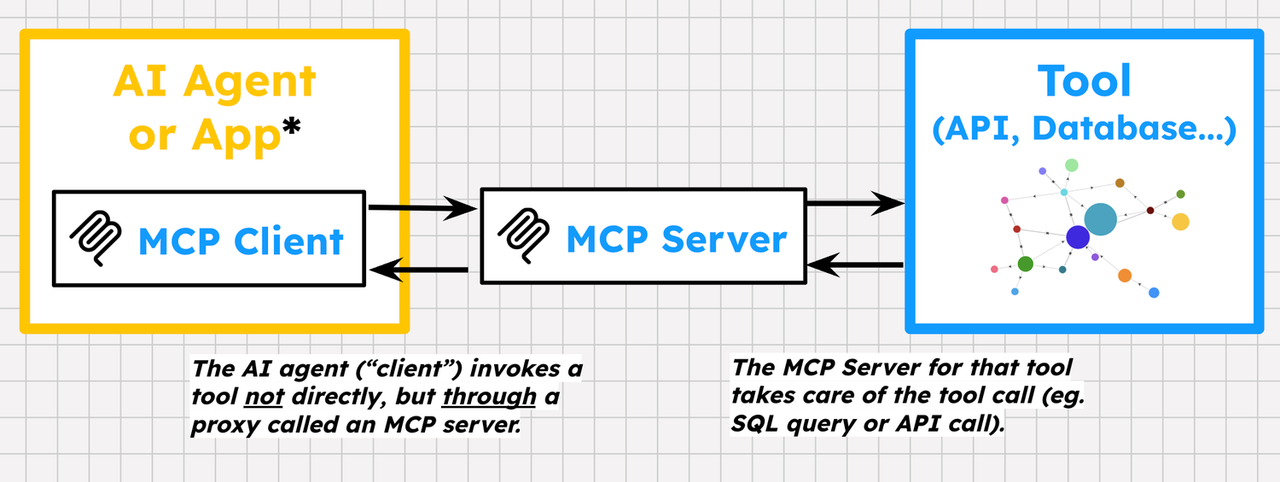
MCP를 이해하면 "도구 서버 한 번 만들어두고 여러 에이전트에서 재사용하는" 아키텍처를 설계하기 매우 쉬워진다.
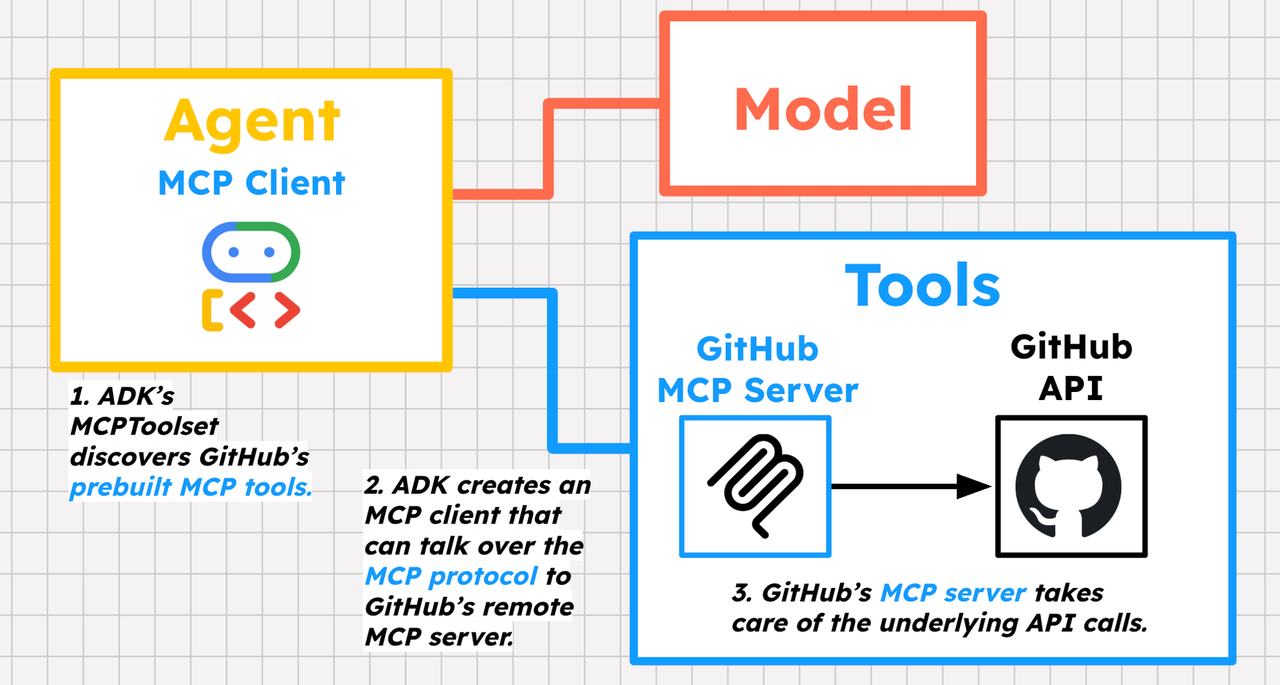
GitHub MCP 서버로 이슈·PR 검색 붙이기
GitHub는 MCP 기반의 원격 서버를 제공해, 에이전트가 GitHub의 다양한 기능을 쉽게 활용할 수 있도록 하고 있다.
버그 어시스턴트에서는 GitHub MCP 서버를 통해 오픈소스 의존성의 이슈·PR 상태를 조회하고, 내부 버그와 연결해 원인을 추적한다.
ADK에서는 MCPToolset을 사용해 GitHub MCP 서버에 연결하고, tool_filter로 사용할 도구를 제한한다.
from google.adk.tools.mcp_tool import MCPToolset, StreamableHTTPConnectionParams
import os
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url="https://api.githubcopilot.com/mcp/",
headers={
"Authorization": "Bearer " + os.getenv("GITHUB_PERSONAL_ACCESS_TOKEN"),
},
),
tool_filter=[
"search_repositories",
"search_issues",
"list_issues",
"get_issue",
"list_pull_requests",
"get_pull_request",
],
)이때 사용하는 GitHub Personal Access Token은 읽기 전용(public repo) 범위로 최소 권한만 부여해, 보안 위험을 줄인다.
tool_filter로 불필요하거나 위험한 도구를 숨기면, 모델이 도구를 선택할 때 옵션이 줄어들어 판단이 쉬워지고, 의도치 않은 민감 작업(예: 삭제, 쓰기)을 막을 수 있다.
다음 그림은 ADK 에이전트가 GitHub MCP 서버와 연동되는 구조를 요약한다.
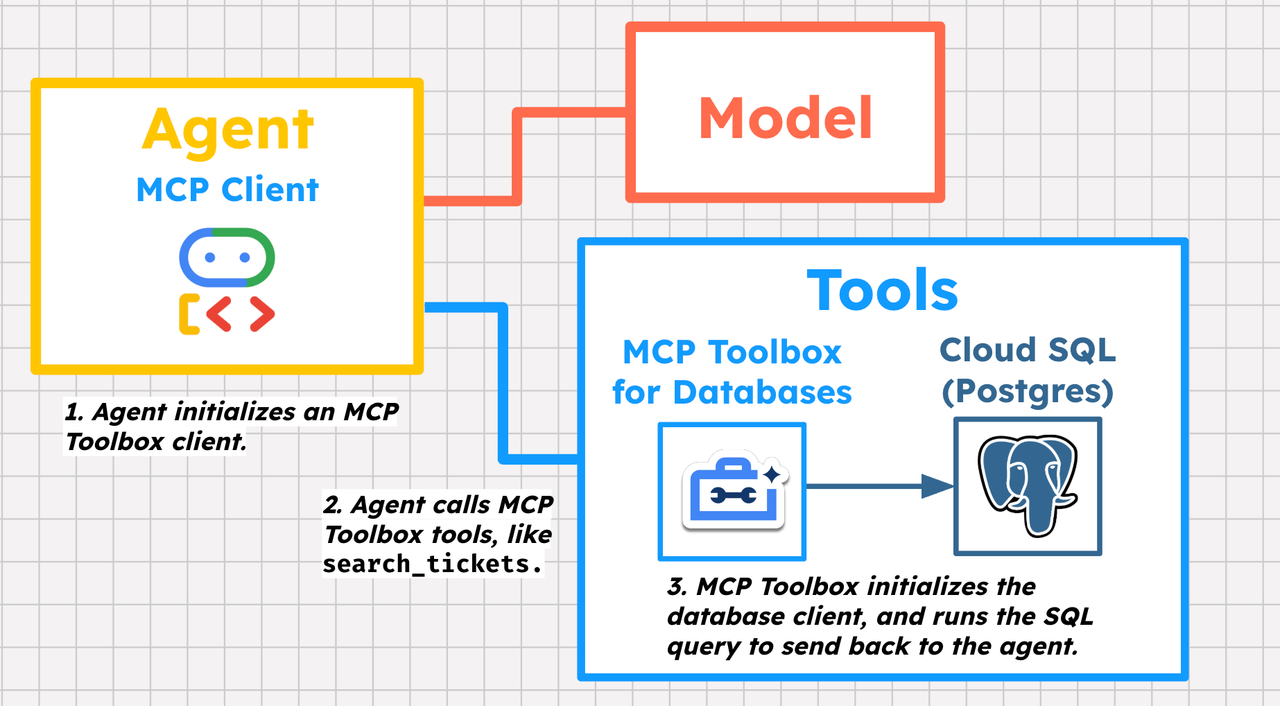
MCP Toolbox로 내부 버그 데이터베이스 연결하기
QuantumRoast 내부의 버그 티켓은 Cloud SQL(PostgreSQL)에 저장되어 있다.
이 DB에 직접 Python ORM을 붙여 Function Tool로 감싸도 되지만, 연결·인증·쿼리 관리까지 매번 구현해야 하므로 유지보수가 번거롭다.
이를 대신해 Google이 제공하는 MCP Toolbox for Databases를 사용하면, DB를 MCP 서버 뒤에 숨기고 에이전트에서는 MCP Toolset만 사용하면 된다.
Toolbox에서는 tools.yaml에 DB 연결 정보와 사용할 도구들을 선언적으로 정의한다. 예를 들어 티켓 설명을 벡터로 임베딩해 유사 티켓을 찾는 search-tickets 도구는 다음과 같이 정의할 수 있다.
sources:
postgresql:
kind: cloud-sql-postgres
project: my-gcp-project
region: us-central1
instance: software-assistant
database: tickets-db
user: postgres
password: ${POSTGRES_PASSWORD}
tools:
search-tickets:
kind: postgres-sql
source: postgresql
description: Search for similar tickets based on their descriptions.
parameters:
- name: query
type: string
description: The query to perform vector search with.
statement: |
SELECT ticket_id, title, description, assignee, priority, status,
(embedding <=> embedding('text-embedding-005', $1)::vector) as distance
FROM tickets
ORDER BY distance ASC
LIMIT 3;Toolbox MCP 서버를 실행한 뒤, 에이전트 코드에서는 다음처럼 Toolset을 로드한다.
from toolbox_core import ToolboxSyncClient
import os
TOOLBOX_URL = os.getenv("MCP_TOOLBOX_URL", "http://127.0.0.1:5000")
toolbox = ToolboxSyncClient(TOOLBOX_URL)
toolbox_tools = toolbox.load_toolset("tickets_toolset")이제 에이전트는 search-tickets, create-new-ticket, update-ticket-status 같은 DB 도구를 호출해, 유사 티켓 검색, 신규 티켓 생성, 상태 업데이트 등을 자동으로 처리할 수 있다.
아래 다이어그램은 MCP Toolbox가 DB 앞단에서 "도구 서버" 역할을 하는 모습을 보여준다.
QuantumRoast 버그 어시스턴트: 전체 구성과 프롬프트 설계
지금까지의 모든 도구를 하나의 에이전트에 모으면, 실제로 업무를 지원하는 "버그 어시스턴트"가 완성된다.
루트 에이전트는 Gemimi 2.5 Flash 모델을 사용하며, 다음 도구들을 모두 가진다.
root_agent = Agent(
model="gemini-2.5-flash",
name="software_bug_assistant",
instruction=agent_instruction,
tools=[
get_current_date, # Function Tool
search_tool, # Google Search Agent Tool
langchain_tool, # StackExchange (LangChain)
*toolbox_tools, # DB 도구들 (MCP Toolbox)
mcp_tools, # GitHub MCP Toolset
],
)여기서 중요한 것은 시스템 인스트럭션(agent_instruction) 이다. 이 안에 다음과 같은 내용을 구체적으로 적어준다.
사용자의 요청을 이해하고, 모호할 경우 추가 질문을 하라는 지침
어떤 상황에서 어떤 도구를 우선 고려해야 하는지(예: 유사 버그 찾기 →
search-tickets우선, 외부 취약점 정보 확인 → Google Search + StackOverflow + GitHub)도구 결과를 어떻게 해석하고, 언제 새로운 티켓을 생성할지에 대한 기준
또한 각 도구에 대한 설명을 프롬프트에 포함해, 모델이 도구의 목적과 입력·출력을 이해하도록 돕는다. 예를 들어 search-tickets에 대해 "설명 기반 벡터 검색, 거리 0.3 이하를 유사·중복으로 간주"와 같이 명시한다.
이 전체 에이전트 스택은 Cloud Run(에이전트 서버, MCP 서버), Cloud SQL(버그 DB), Vertex AI(모델) 위에 배치할 수 있다.
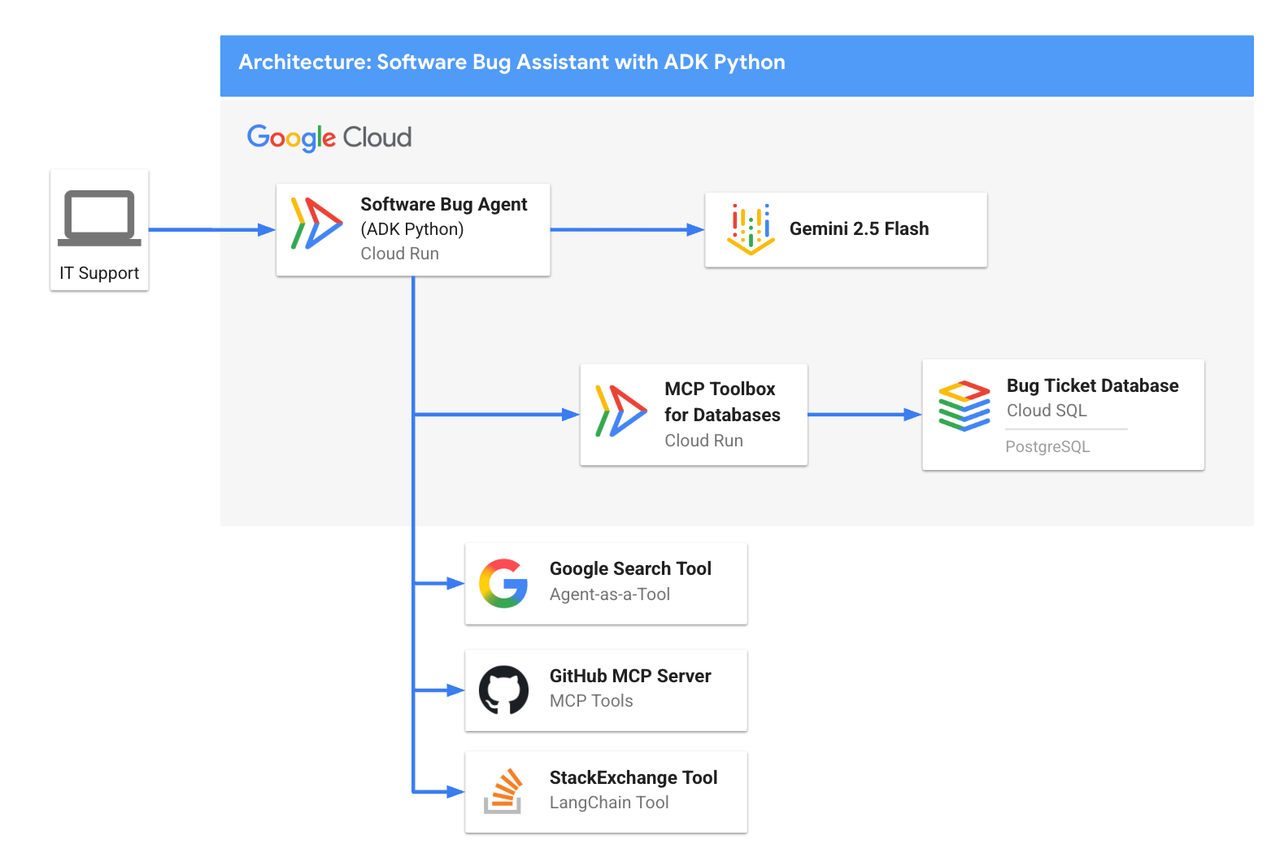
이 아키텍처를 그대로 확장하면, 커피머신 회사뿐 아니라 일반 SaaS, 전자상거래, 내부 IT 헬프데스크 등 다양한 도메인의 "업무용 에이전트"를 설계할 수 있다.
인사이트
도구는 에이전트의 "손과 발"이기 때문에, 무엇을 붙이느냐보다 언제 어떻게 쓰게 할지를 설계하는 것이 더 중요하다. Function Tool로 작은 유틸리티부터 시작해, Built-in·LangChain·MCP로 점진적으로 확장하면 복잡성을 관리하기 쉽다.
MCP와 MCP Toolbox 같은 추상화는 "도구 서버를 한 번 잘 만들어두면 여러 에이전트가 재사용"할 수 있게 해주므로, 조직 규모가 커질수록 가치가 커진다. 처음에는 읽기 전용 도구만 공개해 안전하게 실험하고, 점차 쓰기(티켓 생성·업데이트 등) 권한을 가진 도구를 신중히 추가하는 전략이 좋다.
실무에서 바로 시작해 보고 싶다면, ① 간단한 Function Tool과 한 개의 외부 API 도구로 미니 에이전트를 만들고, ② 이후 내부 데이터베이스를 MCP Toolbox로 노출해 "회사 데이터에 연결된 에이전트"를 만들어 보는 순서를 추천한다.
출처 및 참고 : Tools Make an Agent: From Zero to Assistant with ADK | Google Cloud Blog