
ChatGPT Images · GPT Image 1.5 한눈에 이해하기
핵심 요약
새로운 ChatGPT Images와 GPT Image 1.5는 "내가 상상한 그대로" 이미지를 만들고 고치는 데 초점을 맞춘 모델이다. 정교한 편집, 더 정확한 지시 이해, 작은 글자까지 읽히는 텍스트 렌더링, 더 자연스러운 화질과 빠른 속도로 실전 활용성이 크게 올라갔다.
새로워진 ChatGPT Images 개요
이번 업데이트의 핵심은 이미지 생성과 편집이 "속도, 정확도, 일관성" 면에서 모두 크게 개선됐다는 점이다. 사용자는 텍스트로만 설명하거나, 기존 사진을 올려 수정 지시를 내리는 방식으로 이미지를 만들 수 있고, 모델은 이전보다 세부 지시를 훨씬 잘 따라준다.
이미지 생성 속도는 최대 4배 빨라져, 여러 버전을 돌려보며 아이디어를 탐색하는 과정이 훨씬 가벼워졌다. 이 기능은 ChatGPT 내 일반 사용자에게 순차적으로 적용되고 있으며, API에서는 GPT Image 1.5라는 이름으로 제공된다.

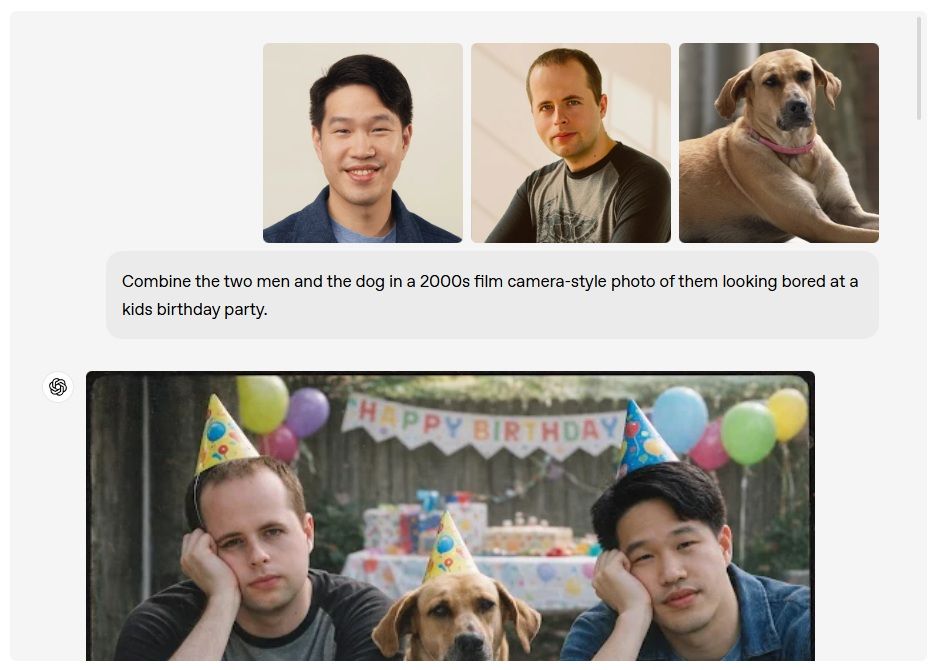
정밀 편집: 원하는 것만 바꾸고 나머지는 유지 (Edit)
이번 모델의 가장 중요한 변화 중 하나는 "다른 건 건드리지 말고 여기만 바꿔줘"라는 요청을 잘 처리한다는 점이다. 빛, 구도, 인물의 얼굴 특징 등 핵심 요소는 그대로 유지하면서, 옷, 표정, 배경 객체, 스타일만 바꾸는 식의 편집이 자연스럽게 가능해졌다.
예를 들어, 두 남자와 개가 나오는 사진 두 장을 합쳐 한 장의 사진으로 만들고, 그 뒤에 어린이 생일파티의 혼잡한 장면을 추가하고, 한 남자만 애니메이션 스타일로 바꾸는 등 복잡한 연속 편집이 가능하다. 또 같은 인물의 얼굴을 여러 번 편집해도, 이전 버전과 얼굴이 완전히 달라지는 현상이 줄어들어 "같은 사람으로 보이는지"가 훨씬 잘 유지된다.

이미지 조합·변형: 더 자유로운 창작 스튜디오
모델은 추가, 삭제, 합성, 스타일 변경 등 다양한 변형을 안정적으로 수행해, 마치 간단한 "이미지 합성 스튜디오"처럼 쓸 수 있다. 서로 다른 사진에서 인물을 꺼내 한 장의 장면에 배치하거나, 실제 사진을 일부만 인형·애니메이션 스타일로 바꾸는 등 현실과 상상을 섞는 작업이 유연해졌다.
예를 들어, 동일한 장면에서 한 사람은 손그림 레트로 애니메이션 스타일, 개는 봉제 인형 느낌, 다른 사람과 배경은 사진 그대로 두는 식의 혼합 스타일도 잘 처리한다. 이런 능력은 패션 시착, 헤어스타일 시뮬레이션, 홍보용 합성 이미지 제작 등에 직접 활용할 수 있다.

프롬프트 없이도 시작 가능한 창의적 변환
새로운 ChatGPT Images 인터페이스에서는 굳이 프롬프트를 길게 쓰지 않고도 다양한 변환을 쉽게 시도할 수 있다. 미리 준비된 스타일, 구도, 아이디어 템플릿을 선택하면, 현재 이미지를 영화 포스터, 카드 디자인, 일러스트 등 다양한 형식으로 자동 변환할 수 있다.
예를 들어 두 남자의 사진을 "고전 할리우드 영화 포스터"로 바꾸면서, 배우 이름, 감독·제작자 정보를 원하는 대로 바꾸는 식의 텍스트·레이아웃 재구성이 가능하다. 이미지 속 텍스트와 구성을 함께 바꾸면서도, 인물의 정체성이나 핵심 요소는 유지하는 것이 특징이다.
지시 따르기(Instruction Following)의 비약적 향상
이번 모델은 "구조가 있는 복잡한 지시"를 훨씬 잘 따라간다. 예를 들어, 6×6 격자를 그리고 각 칸에 서로 다른 사물·기호·문자·숫자를 정확한 위치에 배치하는 과제를 이전 세대보다 훨씬 정확히 해결한다.
이 능력은 인포그래픽, 아이콘 배열, 게임 보드, UI 모형 등 "배치가 중요한 이미지"를 만들 때 특히 유용하다. 즉, 단순히 "분위기만 비슷한 그림"이 아니라, "정확히 A는 왼쪽 위, B는 오른쪽 아래에 있어야 한다"는 요구를 꽤 잘 만족시킨다.

텍스트 렌더링: 작은 글자와 복잡한 레이아웃까지
이전 세대에서 약점이었던 "이미지 속 텍스트" 표현이 크게 개선되었다. 신문 기사 레이아웃처럼 긴 제목, 소제목, 본문, 표, 숫자, 구분선 등으로 이루어진 복잡한 마크다운을 거의 그대로 이미지로 옮길 수 있다.
예시로, GPT-5.2 소개 기사 전체를 신문 지면 형태로 표현하고, 이후 같은 레이아웃에 GPT-Image-1.5 소개 글로 내용을 통째로 교체하는 작업을 안정적으로 수행한다. 작은 글자나 촘촘한 표도 비교적 읽기 좋게 표현할 수 있어, 포스터, 인쇄물 모형, UI 시안 등에 활용도가 높다.

전반적 화질·현실감 향상
새 모델은 "사람이 많은 장면, 작은 얼굴, 복잡한 배경"에서도 더 자연스러운 결과를 내놓는다. 예를 들어 1970년대 런던 첼시 길거리에서 사람과 버스, 광고판, 건물 등이 모두 또렷하게 잡히는 사진풍 장면을 만들 때, 이전보다 얼굴 왜곡이나 이상한 디테일이 줄어들었다.

위와 같은 "사람 많고 요소가 많은 사진풍 장면"에서, 새 모델은 구도 유지와 디테일 표현이 더 안정적이다.
또 깊은 바다 생물 포스터처럼 정보량이 많고 과학적 요소가 많은 그림에서도, 생물 형태·배치·스타일이 이전보다 더 정확하고 생생하게 표현된다. 물론 여전히 과학적 정확성은 100%가 아니지만, 시각적 품질과 정보 전달력은 크게 향상됐다.

새로운 이미지 전용 공간과 사용 경험
ChatGPT 안에는 이제 "이미지 작업 전용 공간"이 별도로 제공된다. 웹과 모바일 앱의 사이드바에서 접근할 수 있으며, 이곳에서 이미지 생성, 편집, 스타일 변경을 한 곳에서 수행한다.
이 공간에는 유행하는 스타일, 테마, 활용 예시를 담은 프리셋 필터와 프롬프트가 제공되어, 초보자도 복잡한 프롬프트 없이 다양한 결과를 쉽게 시도할 수 있다. 또 한 번만 얼굴을 업로드해두면, 이후 여러 장의 이미지에서 같은 얼굴을 재사용할 수 있어, 개인 캐릭터·아바타를 만들고 돌려쓰기에 편리하다.
이미지는 더 빠르게 렌더링되며, 한 이미지를 생성하는 동안 다른 이미지를 계속 생성할 수도 있어, 작업 흐름이 끊기지 않는다.
GPT Image 1.5 API: 비용·브랜딩·대규모 제작
GPT Image 1.5는 API에서도 사용할 수 있으며, 여기서도 "편집·보존 능력 향상"이 핵심이다. 브랜드 로고, 제품 형태, 포장 디자인 등 "변하면 안 되는 시각 요소"를 유지하면서 색, 배경, 상황, 소품만 바꾸는 식의 활용이 쉬워졌다.
예를 들어, 같은 제품 사진 한 장으로부터 색상 변형, 여러 배경 연출, 다양한 촬영 각도를 자동으로 생성해 "제품 사진 카탈로그"를 대량으로 만들 수 있다. 또한 GPT Image 1 대비 입력·출력 비용이 약 20% 저렴해져, 이미지 수가 많은 마케팅·커머스·창작 서비스에서 경제성이 좋아졌다.

실제 서비스 사업자들은 새 모델이 "구도·조명·세부 묘사"를 안정적으로 유지해, 컨셉에서 실제 결과물까지 가는 시간을 줄여준다고 평가한다.
인사이트
이번 업데이트의 핵심은 "이미지 생성 = 운에 맡기는 랜덤 그림 뽑기"에서 "구체적인 도구로서의 활용" 단계로 올라왔다는 점이다. 실제 작업에서 쓰려면 중요한 요소는 유지되고, 바꾸고 싶은 부분만 정밀하게 제어되며, 텍스트·레이아웃·스타일을 일관되게 다루는 능력이 필수인데, GPT Image 1.5는 이 지점에서 큰 진전을 보여준다.
실용적으로 활용하고 싶다면 다음을 추천한다.
자주 쓰는 스타일이나 브랜드 요소(로고, 색상, 인물 얼굴)를 하나의 기준 이미지로 저장해두고, 그 위에 반복 편집을 요청한다.
복잡한 장면은 "전체 설명 → 구조(행·열, 레이아웃) 명시 → 세부 요소 나열" 순서로 프롬프트를 짜면, 모델의 지시 이해 능력을 최대한 활용할 수 있다.
포스터·프레젠테이션·앱 UI 시안처럼 텍스트와 이미지가 섞인 결과가 필요하다면, 텍스트까지 구체적으로 작성해 넣어보면 이전 세대와 확실한 차이를 체감할 수 있다.
이 흐름을 이해해두면, 단순한 그림 장난을 넘어서 마케팅, 제품 사진, 교육 콘텐츠, 크리에이터 브랜딩 등 실제 작업에 모델을 자연스럽게 녹여 넣을 수 있다.
출처 및 참고 : The new ChatGPT Images is here | OpenAI