

AI, 인공지능 그리고 진실의 딜레마: FACTS 벤치마크가 드러낸 현실
대형 언어 모델(LLM)이 우리 일상과 산업 곳곳에서 활약하고 있지만, 이들이 과연 진실만을 말하는지에 대한 의문은 여전히 남아 있습니다. 최근 Google DeepMind가 도입한 'FACTS' 벤치마크는 AI의 사실 정확성을 네 가지 측면에서 엄격하게 평가하며, 세계 최강 AI라 해도 진실의 벽 앞에서는 예상외로 흔들린다는 흥미로운 결과를 공개했습니다. 이번 글에서는 FACTS 벤치마크의 구조, 주요 결과, 그리고 AI의 ‘진실 탐험’이 왜 중요한지 쉽고 재미있게 풀어봅니다.
FACTS 벤치마크란? AI의 '진실 파악력'을 종합 진단
FACTS는 Google DeepMind가 개발한 AI 모델의 사실 신뢰도를 측정하는 새로운 기준점입니다. 단일 기술에만 초점을 맞추지 않고, 시각적 정보 해석, 내부 지식, 웹 검색, 텍스트 근거 등 네 가지 축을 아우르는 것이 특징입니다.
이전까지의 평가 방식은 종종 한 분야(예: 문서 요약)만을 측정했습니다. 하지만 FACTS는 다양한 실사용 시나리오에서 모델의 종합적 성능을 시험해, 진짜 ‘만능 AI’가 존재하는지 파고듭니다.
어떤 AI가 더 잘 맞혔나? 분야별로 드러나는 강점과 한계
벤치마크 결과를 보면, Google의 Gemini 3 Pro가 전체 68.8점으로 1위를 차지했지만, 영광은 잠시뿐입니다. 상위 모델인 Gemini 2.5 Pro(62.1점), OpenAI GPT-5(61.8점)가 뒤를 잇지만, 분야별로 들여다보면 약점이 훤히 드러납니다.
검색(Search) 능력: Gemini 3 Pro는 83.8%의 정확도로 ‘검색’ 분야에서 압도적이지만...
내부 지식(Parametric): 76.4%로 강세를 보이지만,
이미지/멀티모달(Multimodal): 46.1%에 그쳐, 시각적 정보 해석에서 크게 흔들립니다.
GPT-5도 추세는 비슷해, 복잡한 검색 질의에는 강하지만, 내부 사실 회상이나 이미지 이해에서는 명확히 성능이 떨어지죠.
벤치마크, 어떻게 작동하나? 4가지 진실 탐험 미션
FACTS는 총 4가지 서브 테스트로 모델의 능력을 다층적으로 체크합니다.
Multimodal(시각 기반): 이미지를 보고 핵심 사실을 빠짐없이 찾아내야 함.
Parametric(내부 지식): 위키피디아 기반 어려운 질문에, 외부 도구 없이 답해야 함.
Search(웹 검색): 검색 엔진을 활용해, 기존 데이터에 없는 정보도 찾게 함.
Grounding(문서 기반): 제공된 긴 문서만 참고해, 정확하게 사실을 재구성해야 함.
이 테스트들은 Kaggle 플랫폼에서 관리되어, 모델의 사전 학습이나 특정 질문에 최적화되는 것을 방지합니다.
AI의 전략적 침묵 vs. 가짜 답변: 거짓말보다 차라리 아무 말도 안 하는 게 낫다?
재미있는 발견 중 하나는 '불확실성'에 대한 AI의 대응입니다. 최신 GPT-5는 13%의 질문에 답변을 거부하는 '전략적 침묵' 덕분에, 엉뚱한 말을 하는 초기 버전(GPT-o3)보다 더 높은 정확성을 유지합니다.
반면, Gemini 3 Pro는 답을 모를 때 88%의 확률로 ‘가짜 답’을 만들어내는 경향이 있습니다. Omniscience Index라는 추가 평가지에서는 이런 허구적 답변에 무거운 패널티가 주어집니다. 이는 '모른다'고 말하는 AI가 오히려 더 믿을 만하다는 교훈을 남깁니다.
모델 크기와 일반 지능, 진실 앞에선 무력할 수 있다
수십억 파라미터를 자랑하는 거대 LLM도, 정보 오류나 '환상(hallucination)' 문제에서 자유롭지 못하다는 것이 FACTS 벤치마크의 뼈아픈 결론입니다. 즉, 크고 똑똑하다고 진실을 보장하는 것은 아니며, 훈련 방법과 평가 방식의 혁신이 더 절실하다는 뜻이죠.
최신 벤치마크 ARC-AGI, 그리고 진짜 ‘추론력’의 경쟁
다른 분야인 ARC-AGI-2와 같은 최신 벤치마크에서는 ‘추상적 추론력’을 테스트합니다. 예를 들어, 2025년도 Kaggle ARC-AGI-2에서 OpenAI GPT-5.2가 52.9%, Gemini 3 Deep Think가 45.1% 스코어를 기록했는데, 이는 단순 암기나 패턴 매칭을 넘어서, AI가 얼마나 ‘창의적으로’ 문제를 해결하는지를 보여줍니다. 여기서도 거대 모델이 만능은 아니었습니다(관련 비교 화상 참고).
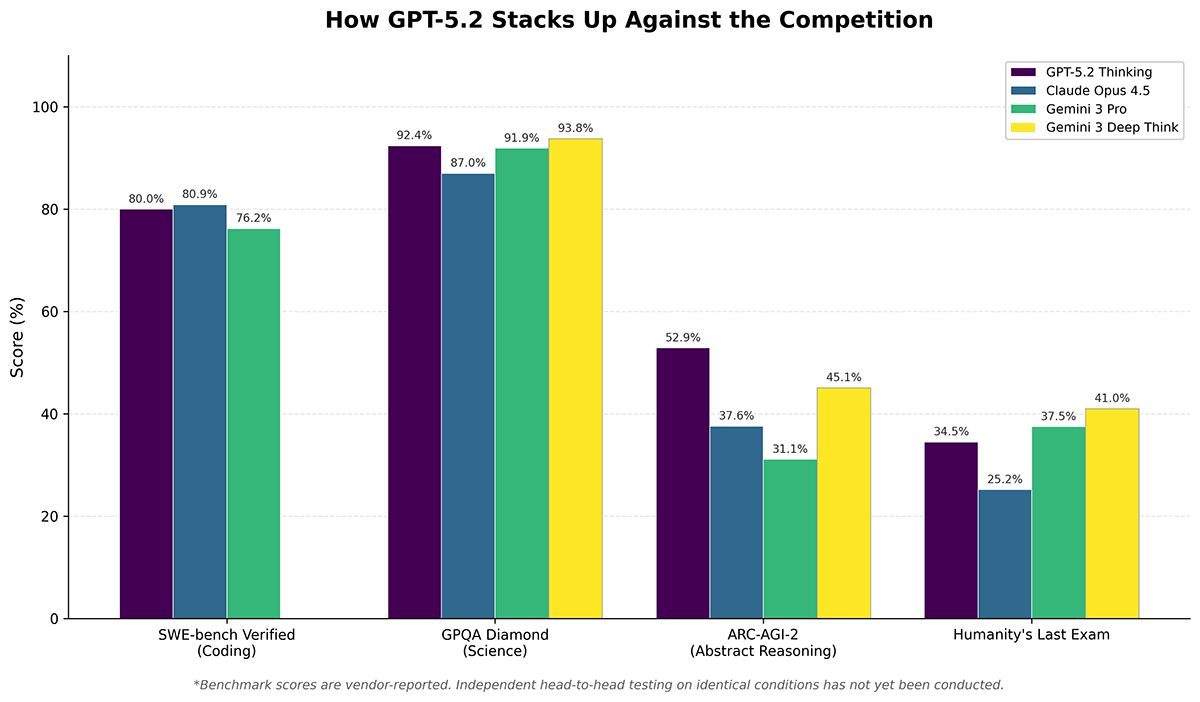{kind=link}
실전에서의 의미와 조언: AI, 만능 도구가 아니라 현명하게 써야 할 친구
FACTS 벤치마크는 AI를 쓰는 모든 이들에게 중요한 신호를 줍니다.
AI의 답변은 분야에 따라 신뢰성이 크게 다를 수 있다.
때로는 “모른다”는 답변이 “틀렸다”보다 낫다.
최신 모델도 실수를 피할 수 없으니, 중요한 의사결정에는 인간 검증이 꼭 필요하다.
다양한 평가 기준(예: FACTS, ARC-AGI-2 등)을 활용해 AI의 실제 한계를 정확히 파악해야 한다.
인공지능이 일상과 비즈니스에서 더 활약하기 위해서는, ‘진실을 얼마나 잘 다루는가’에 대한 냉정한 평가와 함께, 모델 개발과 사용에 좀 더 현명한 접근법이 요구된다는 사실을 기억해야 합니다.
참고
[1] FACTS benchmark shows that even top AI models struggle with the truth - THE DECODER
[2] Google DeepMind - Wikipedia - Wikipedia
[3] How GPT-5.2 stacks up against Gemini 3.0 and Claude Opus 4.5 - R&D World
[4] Gemini 3 Pro vs GPT 5.1: which is better? A Complete Comparison - CometAPI
[5] NVIDIA Kaggle Grandmasters Win Artificial General Intelligence Competition - NVIDIA Technical Blog