

인공지능 챗봇 사용 통찰 얻기, 개인정보는 지킬 수 있을까? – AI와 프라이버시의 미래
인공지능(인공지능, AI)이 우리의 삶 곳곳에 스며들어 있습니다. 이메일 작성이나 코드 개발, 여행 계획까지 대형 언어 모델(LLM) 챗봇이 매일 수백만 명의 손끝에서 활약하는 요즘, 서비스 제공자들은 이런 대화들을 통해 어떻게 더 좋은 플랫폼을 만들 수 있을까 고민하게 됩니다. 하지만 사용자들이 나누는 이야기에는 민감한 정보도 포함돼 있기 때문에, 데이터를 분석해 인사이트를 얻는 일은 곧 개인정보 보호와 씨름하는 일이 됩니다.
이번 글에서는 구글 리서치가 제안한 ‘차등적으로 개인화된 프레임워크’의 핵심을 쉽고 재미있게 풀어보면서, AI 챗봇 시대의 프라이버시 문제와 해결책, 그리고 미래 방향까지 함께 탐색합니다.
AI 챗봇 사용 통찰, 왜 프라이버시가 중요할까?
AI 챗봇은 단순한 대화 파트너 이상의 역할을 합니다. 사용자들은 이메일을 첨삭받고, 복잡한 코딩 도움을 받고, 커피숍 메뉴를 뽑아달라는 등 진짜 생활 속 고민을 털어놓죠. 이렇게 쌓인 대화 데이터는 플랫폼 혁신과 서비스 개선에 소중한 자원이 됩니다.
하지만 여기엔 커다란 고민이 따릅니다. 만약 대화 속에 이름, 계좌번호 또는 회사 기밀 같은 민감한 정보가 숨어 있다면 어떻게 해야 할까요? 기존 방식들은 챗봇이 대화를 요약할 때 ‘개인정보를 내보내지 않도록’ 휴리스틱(경험적) 방법에 의존하는데, 이 방법은 공식적으로 검증하기 어렵고 모델이 진화할수록 불안정해질 수 있습니다. 결국, 엉겁결에 누군가의 정보가 드러날 위험이 항상 있습니다.
차등 개인정보 보호(Differential Privacy): 데이터 보호의 마법 공식
구글의 새로운 ‘차등 개인정보 보호(DP)’ 프레임워크는 이 문제를 똑똑하게 풀어내는 방법을 제시합니다.
차등 개인정보 보호란, 아무리 데이터 분석을 해도 특정 개인의 정보가 결과에 미치는 영향이 극히 제한되도록 한 수학적 방법입니다. 이를 위해 프레임워크는 ‘프라이버시 예산’(ε, 엡실론)이라는 값을 설정해놓고, 어떤 대화가 분석 결과에 너무 크게 작용하지 않도록 잡아둡니다. 쉽게 말해, 내 메시지가 아무리 특이해도 그 정보가 밖으로 새어나갈 확률을 지수적으로 낮춥니다.
단계별 프로세스가 궁금하다면!
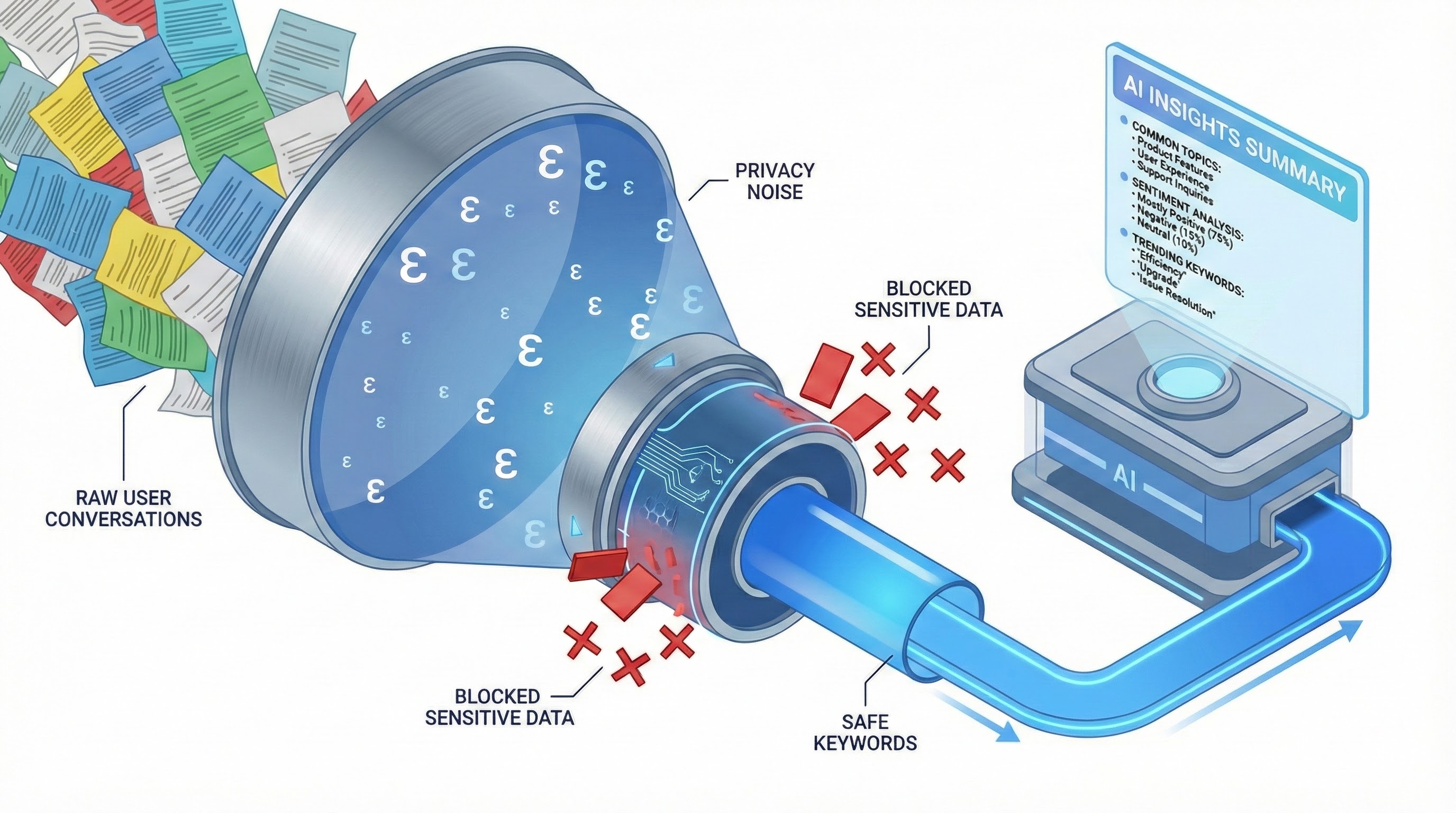
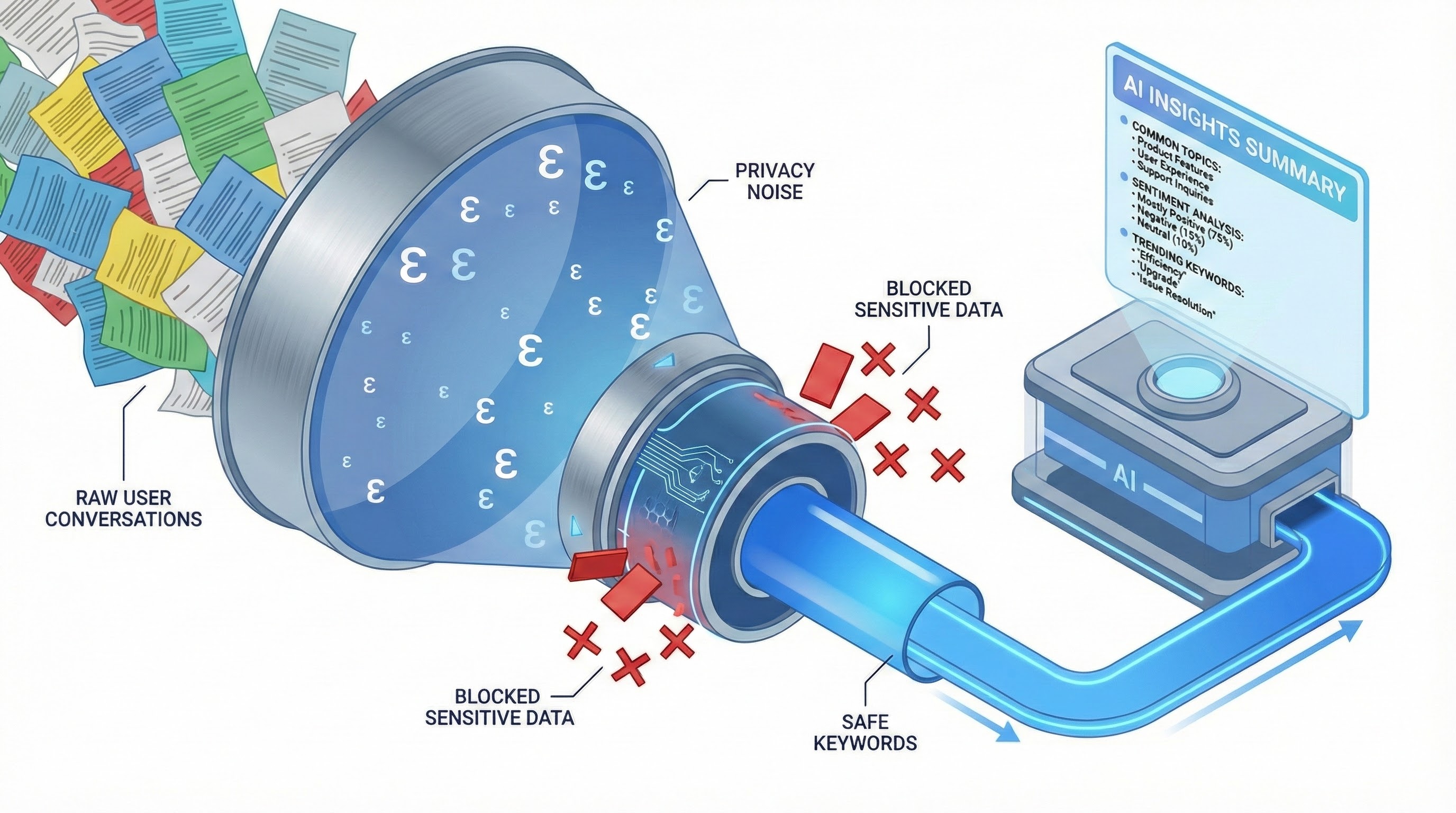 이미지 출처: googleapis
이미지 출처: googleapis
{kind=link}
DP 클러스터링 – 먼저 챗봇 대화들을 숫자(벡터)로 변환한 뒤, 유사한 대화끼리 묶습니다. 이때 각 그룹(클러스터)의 중심이 한 개인의 특이한 행동 때문에 튀어나가지 않도록 소음(노이즈)을 추가합니다.
DP 키워드 추출 – 각 클러스터에서 빈번하게 등장하는 키워드를 뽑는데, 여기서도 마찬가지로 소음을 더해 흔하지 않은 단어(즉, 개인 전문용어나 고유 정보)가 드러나지 않게 만듭니다. 키워드는 세 가지 방식으로 만들 수 있는데, AI가 대화에서 5개 키워드를 뽑거나, DP 버전 TF-IDF 등 수학적 방식, 공적 데이터로 만든 후보 리스트에서 선택하는 방식이 활용됩니다.
요약 생성 – 마지막으로, AI 챗봇은 원래 대화 내용 대신 익명화된 키워드만 보고 그룹별 요약을 만듭니다. 요약에 민감 정보가 섞일 틈 자체가 없는 것이죠.
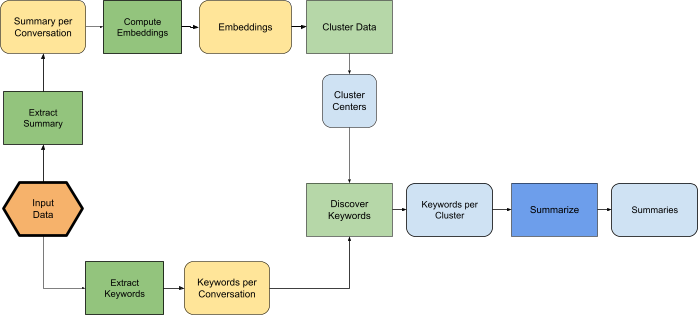 이미지 출처: googleapis
이미지 출처: googleapis
{kind=link}
노란색은 DP가 적용되지 않은, 초록은 DP 혹은 대화별 처리, 파란색은 비(非)프라이빗 활성값을 의미합니다. 모든 흐름이 프라이버시를 보장하는 설계입니다.
프라이버시 vs. 분석력: 양립 가능한가?
차등 개인정보 보호를 엄격하게 적용하면 세부적인 분석력이 떨어질 것 같지만, 실험 결과는 흥미로웠습니다. 오히려 중요한 키워드만 사용한 AI의 요약이 더 명확하고 집중된 정보를 제공할 때가 많았습니다. 흔히 사람 평가관들이 ‘더 잘 정리됐다’라고 꼽은 결과는 최대 70%였습니다.
 이미지 출처: googleapis
이미지 출처: googleapis
{kind=link}
프라이버시를 강화하면, 만약 누군가 특정 대화가 데이터셋에 포함되어 있는지 추리려고 해도(회원 정보 유출 공격), 맞출 확률이 거의 동전 던지기(50:50) 수준에 머물렀습니다. 반면, 기존 비(非)개인정보 보호 방식엔 정보 유출 위험이 더 컸죠.
AI 시대의 프라이버시: 실질적 방어책은 무엇일까?
이론적으로 완벽한 보호를 자랑하는 차등 개인정보 보호는 실제 서비스에도 점점 적용되고 있습니다. 구글, 아마존, 애플 등 글로벌 기업들은 이미 개인정보를 익명화하거나 DP 기법을 부분적으로 접목한 제품을 내놓고 있습니다. 또한, LLM 챗봇 자체를 클라우드가 아닌 내 컴퓨터에서 ‘로컬’로 돌리는 솔루션(Ollama, LM Studio 등)이 속속 등장해, 민감한 데이터는 아예 외부로 나가지 않게 하는 움직임도 활발합니다.
AI 보안 전문 기업들은 자동화된 공격 탐지(예: 프롬프트 인젝션, 데이터 유출 시도), 내장 데이터 암호화, 실시간 모니터링을 통해 챗봇 운영 리스크를 줄이고 있습니다. 사용자 스스로도 할 수 있는 방어법이 있습니다. 예를 들어, 여러 챗봇을 분산 사용해 한 서비스에 내 모든 정보를 맡기지 않거나, 절대 공개하기 싫은 내용은 온라인 서비스에 입력하지 않는 습관을 들이는 것도 중요합니다.
참고로, 프라이버시와 윤리 문제는 더이상 IT 기술자만의 이슈가 아닙니다. AI가 의료, 교육, 금융 등 생활 인프라에 녹아들수록, ‘내 데이터가 어떻게 쓰이는지’에 대한 투명성 요구와 책임 경영, 신뢰 구축이 사회적으로 큰 과제가 되고 있습니다.
앞으로의 방향: 기술의 진화와 사용자 권리의 균형
DP 프레임워크의 다음 목표는 실시간(온라인) 대화에서도 프라이버시를 지키는 방법, 사진이나 음성 등 다중 모달 데이터에 대한 보안 적용, 그리고 예산에 맞는 다양한 보호 수준을 제공하는 방식 등이 개발되고 있습니다. 사용자의 프라이버시를 지키면서도, 플랫폼 혁신을 도모하려는 시도는 앞으로 더 활발해질 예정이죠.
사람에게 ‘개인정보’는 단순한 숫자가 아니라 신뢰와 존엄의 문제입니다. AI와 챗봇 사용이 일상화된 지금, 우리가 원하는 혁신이 무엇인지, 그리고 데이터를 맡길 때 어떤 보장이 필요한지 현명하게 고민해야 할 때입니다.
시사점: 우리 삶을 바꾸는 AI, 프라이버시는 내 힘으로
AI 챗봇 사용 분석은 서비스 혁신의 열쇠지만, 개인정보 보호 없이는 신뢰도, 윤리도 사라집니다.
차등 개인정보 보호(DP)는 ‘수학적 안전망’을 제공해 민감한 정보를 안전하게 숨겨주는 기술입니다.
엄격한 DP 적용이 오히려 더 집중되고 가치 있는 분석 결과를 만들어냅니다.
AI 보안 도구와 로컬 LLM, 사전 예방적 사용법 등 다양한 방법으로 프라이버시를 지키는 노력 필요합니다.
미래를 바라보며, 기술뿐 아니라 투명성, 윤리, 사용자 권리의 균형을 잡는 것이 AI 시대의 핵심 과제입니다.
AI가 우리의 대화와 삶을 더 나은 방향으로 이끄는 만큼, 내 정보의 안전도 우리가 직접 챙기는 똑똑한 사용자가 되어야 하겠습니다.
참고
[1] A differentially private framework for gaining insights into AI chatbot use - Google Research
[2] 10 Best AI Security Tools for LLM Protection (2025) - Mindgard
[3] A Computer Expert's Advice On Protecting Chatbot Privacy - Psychiatric Times
[4] Top 5 Open-Source AI Apps to Run LLMs Locally for Windows, Linux, macOS, iOS and Android - MEDevel
[5] Ethics of artificial intelligence - Wikipedia