

AI가 진짜 '기억력'을 갖게 됐다: Google Titans 아키텍처와 MIRAS 프레임워크의 혁신
AI가 우리 일상에 깊숙이 자리 잡으면서, 이제 인간처럼 장기 기억을 갖는 인공지능이 필요한 시대가 왔습니다. 구글의 최신 연구, 'Titans' 아키텍처와 'MIRAS' 이론은 AI가 더 길고 풍부한 문맥을 기억하고, 실시간으로 배우는 똑똑한 인공지능의 미래를 열어줍니다. 이 글에서는 Titans와 MIRAS가 기존 인공지능의 한계를 어떻게 극복하고, 우리가 기대하는 ‘진짜 기억력’을 AI에 어떻게 심어주는지 쉽고 재미있게 풀어봅니다.
왜 AI에게 '장기 기억'이 필요할까?
지금의 AI, 특히 최신 챗봇이나 LLM(대규모 언어모델)들은 대화를 마치고 나면 이전에 했던 말을 대부분 잊어버립니다. 매번 처음 보는 사람처럼 새로 시작하죠. 이렇게 ‘단기 기억’만 가진 AI는 긴 문서나 복잡한 프로젝트, 장기간의 데이터 흐름을 충분히 이해할 수 없습니다. 실제로 기존 Transformer 계열 AI들은 입력 문맥이 길어질수록 연산량이 폭증해, 책 한 권이나 유전체(Genome) 분석처럼 엄청난 분량의 정보를 처리하는 데 한계가 있었습니다.
AI의 발전이 한 단계 더 나아가려면, 인간처럼 ‘중요한 정보만 오래 기억하고, 필요 없는 정보는 자연스럽게 잊는’ 장기 메모리 능력이 꼭 필요합니다.
Titans: 실시간으로 배우며 기억하는 AI
구글이 제안한 Titans 아키텍처는 기존 AI의 한계를 한 번에 뛰어넘는 구조를 갖고 있습니다. 그 비밀은 바로 ‘실시간 학습’과 ‘깊은 기억 모듈’!
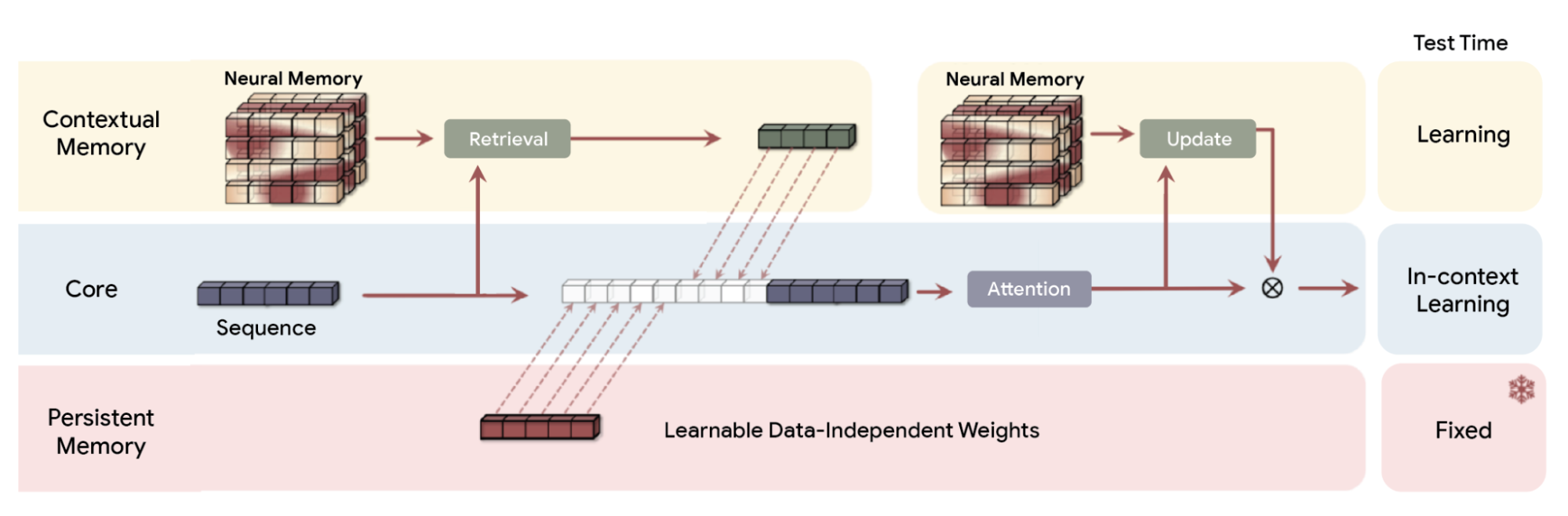
AI가 데이터를 처리할 때, Titans는 두 가지 메모리 구조를 동시에 활용합니다.
단기 메모리(Attention) : 인간의 집중력처럼, 바로 지금 필요한 정보를 빠르게 끄집어냅니다.
장기 메모리(Neural Long-Term Memory) : 깊은 신경망(MLP: Multi-Layer Perceptron)으로 설계된 특별한 저장소에 정말 중요한 정보만 골라서 오랫동안 기억합니다.
이 장기 메모리가 혁신적인 이유, 바로 ‘깜짝 지수(surprise metric)’ 덕분인데요. 새로운 정보가 기존 기억과 크게 다를수록, 즉 예상치 못한 일이 벌어질수록 AI는 그 내용을 적극적으로 오래 기억하도록 학습합니다. 반대로 평소처럼 반복되는 평범한 정보는 자연스럽게 무시하고, 기억 공간을 효율적으로 유지합니다.
 이미지 출처: googleapis
이미지 출처: googleapis
{kind=link}
Titans 아키텍처는 더 나아가 '모멘텀(관성)'과 '적응형 망각(Adaptive Weight Decay)'이라는 기능까지 도입해, 최신 정보뿐만 아니라 그 여파까지 기억할지 판단하고, 필요없는 정보는 자연스럽게 지워버립니다. 이런 능력을 통해 Titans는 2백만 토큰이 넘는 방대한 문맥도 실시간으로 기억하며, GPT-4와 같은 초대형 모델보다도 뛰어난 정확도를 보여줍니다.
MIRAS: 모든 AI 기억의 공통 공식
Titans가 실제 무기라면, MIRAS는 그 무기를 만드는 설계도입니다. MIRAS 프레임워크는 다양한 AI 메모리 시스템을 하나의 관점으로 재해석합니다.
MIRAS가 정의하는 핵심 질문 4가지:
기억을 저장하는 구조(아키텍처) : 벡터, 행렬, 혹은 깊은 신경망 등 다양할 수 있다.
저장할 정보를 고르는 기준(Attentional Bias) : 어떤 정보가 더 중요하고, 먼저 저장해야 할지 결정하는 내부 규칙.
얼마나 오래 동안 기억할지 정하는 방법(Retention Gate) : 새로운 정보가 등장할 때 기존 기억을 얼마나 유지할지, 또는 잊을지 조절하는 ‘망각 메커니즘’.
기억을 업데이트하는 알고리즘 : 저장된 내용을 어떻게 빠르게 최신 상태로 바꿀지, 다양한 최적화 알고리즘(비유클리드 목적 등) 활용.
이 토대 위에서 Titans를 비롯해, attention-free 모델 YAAD, MONETA, MEMORA 등 새로운 AI 구조들이 계속해서 등장하고 있습니다. 이들은 각각 ‘오타 등 오류에 강한 모델’, ‘더 엄격한 기억 규칙 적용’, ‘기억의 안정성 극대화’ 같은 특성을 갖추고 있습니다.
실제 성능: 초거대 문맥도 척척 기억하는 Titans
구글 연구진은 기존 AI 모델들과 Titans, MIRAS 기반 모델들을 다양한 상황에서 직접 비교했습니다.
결과는 놀랍습니다!
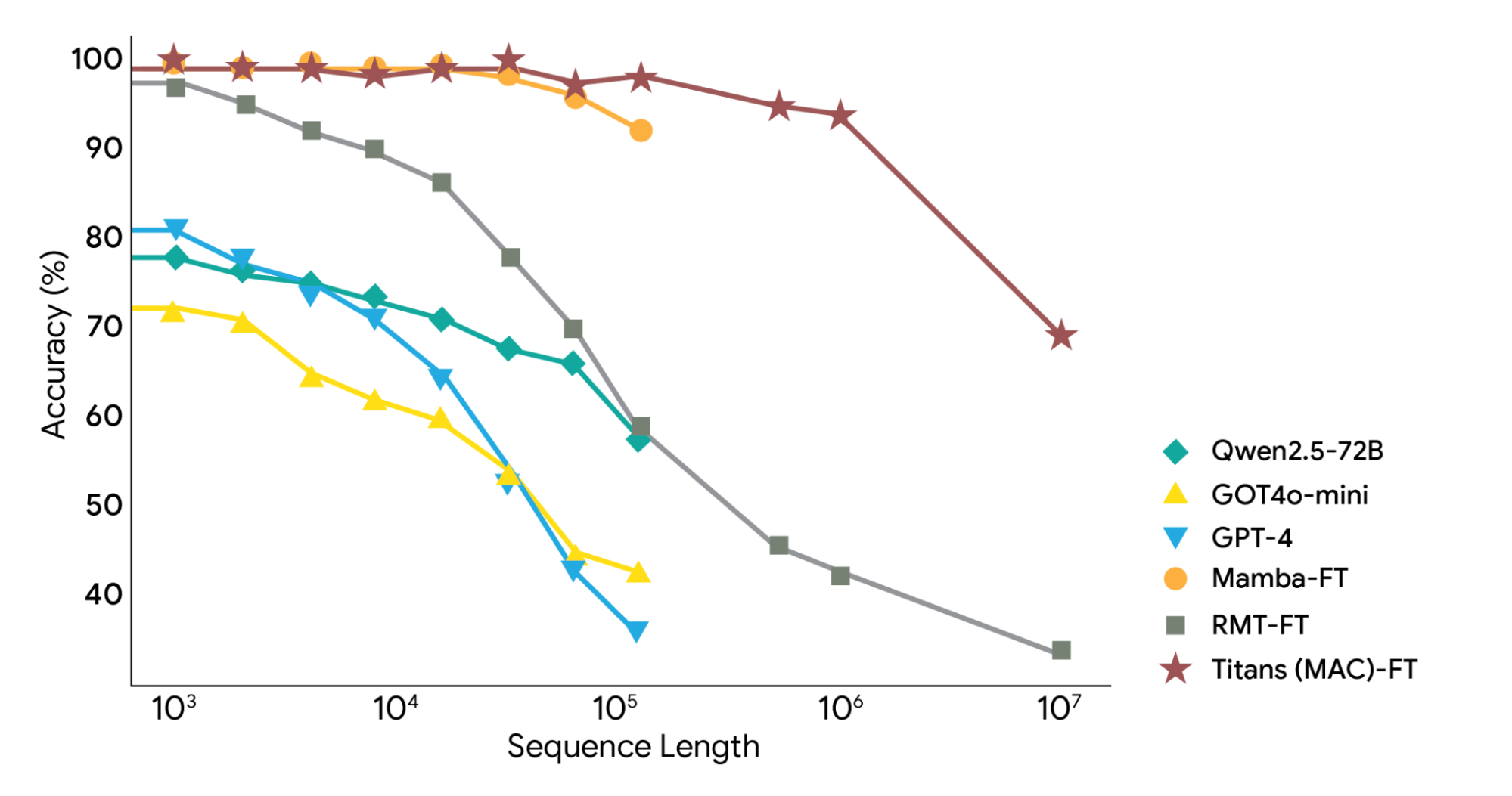
BABILong Benchmark : 방대한 맥락에서 특정 정보를 찾아내는 ‘바늘 찾기’ 테스트에서, Titans 모델은 GPT-4, Llama3 등 훨씬 더 큰 모델들을 뛰어넘었습니다. 2백만 토큰이 넘는 정보를 기억하며, 효율적으로 ‘결정적 순간’을 포착해 정확도를 높였습니다.
상용 언어모델(Basic LM) 및 타임 시리즈/유전체 분석 : 텍스트뿐만 아니라 시간을 따라 변화하는 데이터(DNA 정보 등)에서도 Titans가 돋보이는 확장성을 보여줍니다.
 이미지 출처: googleapis
이미지 출처: googleapis
{kind=link}
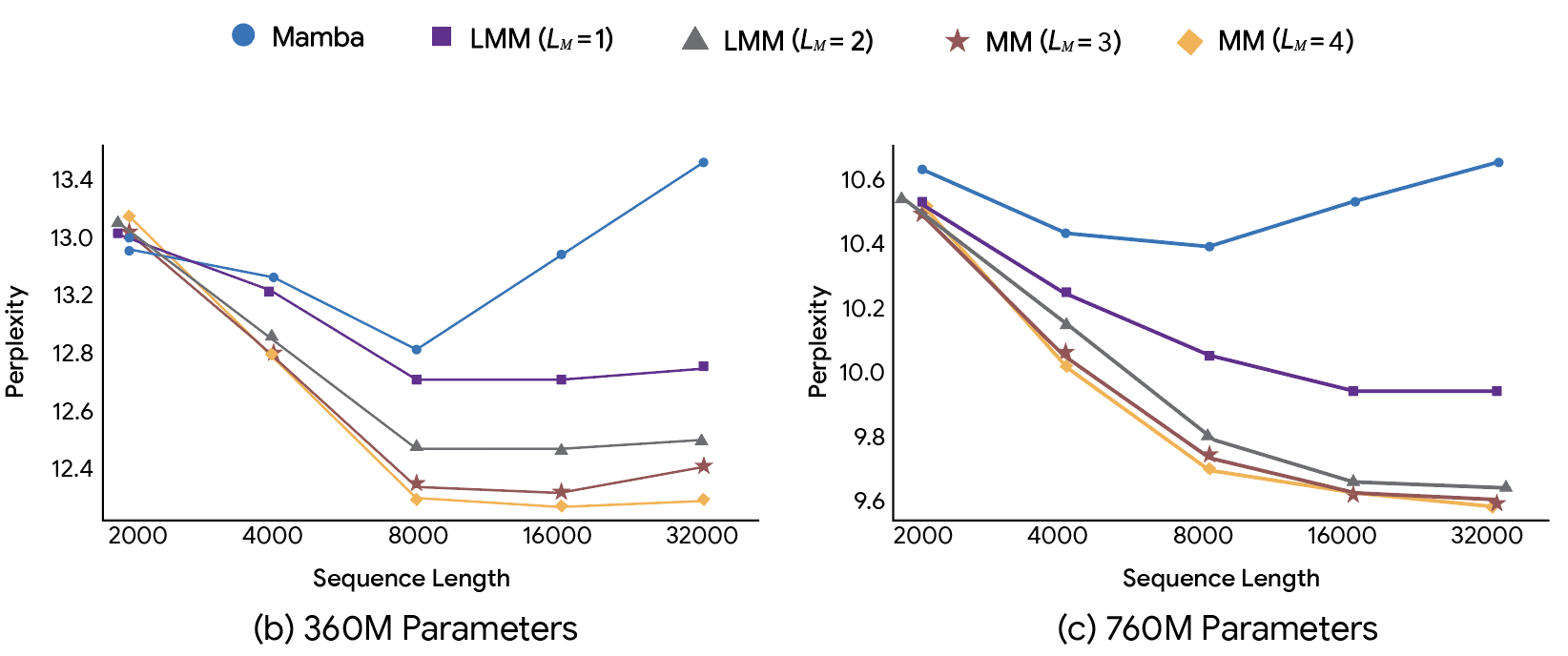
기억의 깊이 : 메모리 모듈이 깊을수록(레이어가 많을수록), 훨씬 더 정확하게 장기 문맥을 유지합니다. 메모리 차원이 같더라도, 구조가 깊어지면 '혼동도(perplexity)'가 줄어들고 성능이 크게 개선됩니다.
 이미지 출처: googleapis
이미지 출처: googleapis
{kind=link}
효율성과 확장성 : Titans와 MIRAS 모델들은 병렬 학습이 가능하며, 빠른 선형 추론 속도를 유지해 대규모 실제 적용에도 용이합니다.
시사점과 앞으로의 AI
Titans와 MIRAS는 단순한 이론이나 논문에 그치지 않습니다. 이 기술은 AI에게 ‘잊지 않는 습관’, 즉 인간처럼 중요한 정보를 오래도록 기억하고 활용하는 능력을 선물합니다. 그 덕분에 앞으로의 챗봇, 검색엔진, 전문분야 분석 AI 등은 사용자의 과거 맥락, 업무 이력, 프로젝트 흐름 등을 훨씬 더 깊이있게 파악할 수 있습니다.
특히 의료, 법률, 과학 연구 등 ‘정확한 기억과 대규모 문맥’이 중요한 분야에서 Titans는 혁신적인 현장 변화를 예고합니다.
앞으로 AI를 도입할 기업이나 개발자는 이제 “메모리 구조와 망각 기능까지 설계·커스터마이즈”할 수 있는 시대를 맞게 됩니다. 실시간 학습, 문맥 연결, 그리고 효율적 망각이 결합된 Titans 아키텍처는 인공지능의 진짜 ‘뇌’를 만드는 첫걸음이 될 것입니다.
참고
[1] Google Unveils 'Titans' Architecture, Enabling AI to Memorize 2 Million Tokens in Real-Time - WinBuzzer
[2] Google outlines MIRAS and Titans, a possible path toward continuously learning AI - THE DECODER
[3] Google Introduces Titans Architecture To Give LLMs Long-Term Memory - OfficeChai
[4] Titans + MIRAS: Helping AI have long-term memory - Google Research