

AI 인공지능 혁명, 효율적 추론의 비밀: Apriel-H1과 Mamba 하이브리드의 진짜 힘
인공지능(AI)는 이제 세상을 움직이는 핵심 기술입니다. 그런데, 최신 AI 모델들은 성능만큼이나 '효율성'이 중요한 시대에 들어섰습니다. 오늘은 효율적 추론 모델의 결정판, Apriel-H1의 놀라운 탄생 과정과 그 핵심 기술인 Mamba 하이브리드 구조, 그리고 지금 AI 추론에서 왜 '데이터의 진짜 선택'이 더 중요해졌는지 쉽고 재미있게 풀어봅니다.
(참고: 본 글은 Hugging Face 공식 블로그 및 최근 주요 AI 연구를 바탕으로 작성했습니다.)
추론 모델에 필요한 '속도'와 '똑똑함', 왜 어렵나?
거대한 AI 언어 모델(LLM, Large Language Model)은 엄청나게 많은 계산을 요구합니다. 실제로 AI가 우리의 질문에 답하거나 설명을 생성할 때, 그 뒤에서는 엄청난 추론(inference)이 실시간으로 이루어집니다. 글로벌 AI 시장은 ‘추론’ 분야만 해도 수십억 달러 규모로 성장했고, 데이터센터의 에너지 소비도 90% 이상이 추론 과정에서 발생한다고 알려졌죠.
바꿔 말하면, 아무리 멋진 AI도 실전에서는 ‘빠르고 싸게, 정확하게’ 움직여야만 진짜 쓸모가 있다는 뜻입니다.
Apriel-H1: 효율성과 성능을 동시에 잡은 추론 혁신
Apriel-H1 프로젝트는 흔치 않은 출발점에서 시작됐습니다. 이미 ‘추론’에 강점을 지닌 15B 파라미터의 AI 모델을 어떤 식으로든 더 효율적으로 만들고 싶었다고 합니다. 그런데 여기서 중요한 질문이 나옵니다:
“완성된 모델을 처음부터 새로 설계하거나 거대한 데이터를 재학습시키면 너무 비효율적이지 않을까?”
정답은, 꼭 그렇지 않다고 합니다! 바로 기존의 모델에 새로운 ‘효율 엔진’을 이식하는 방식, 즉 ‘하이브리드화와 증류(distillation)’라는 트릭을 사용했습니다.
실제 변화
Apriel-H1의 핵심은 기존의 복잡한 어텐션(attention) 레이어들을 선별적으로 Mamba라는 ‘선형 시퀀스 모델’로 대체하는 것입니다.
덜 중요한 25개 레이어를 골라 바꾸고, 이후 점진적으로 Mamba 레이어를 늘려 40개까지 확장.
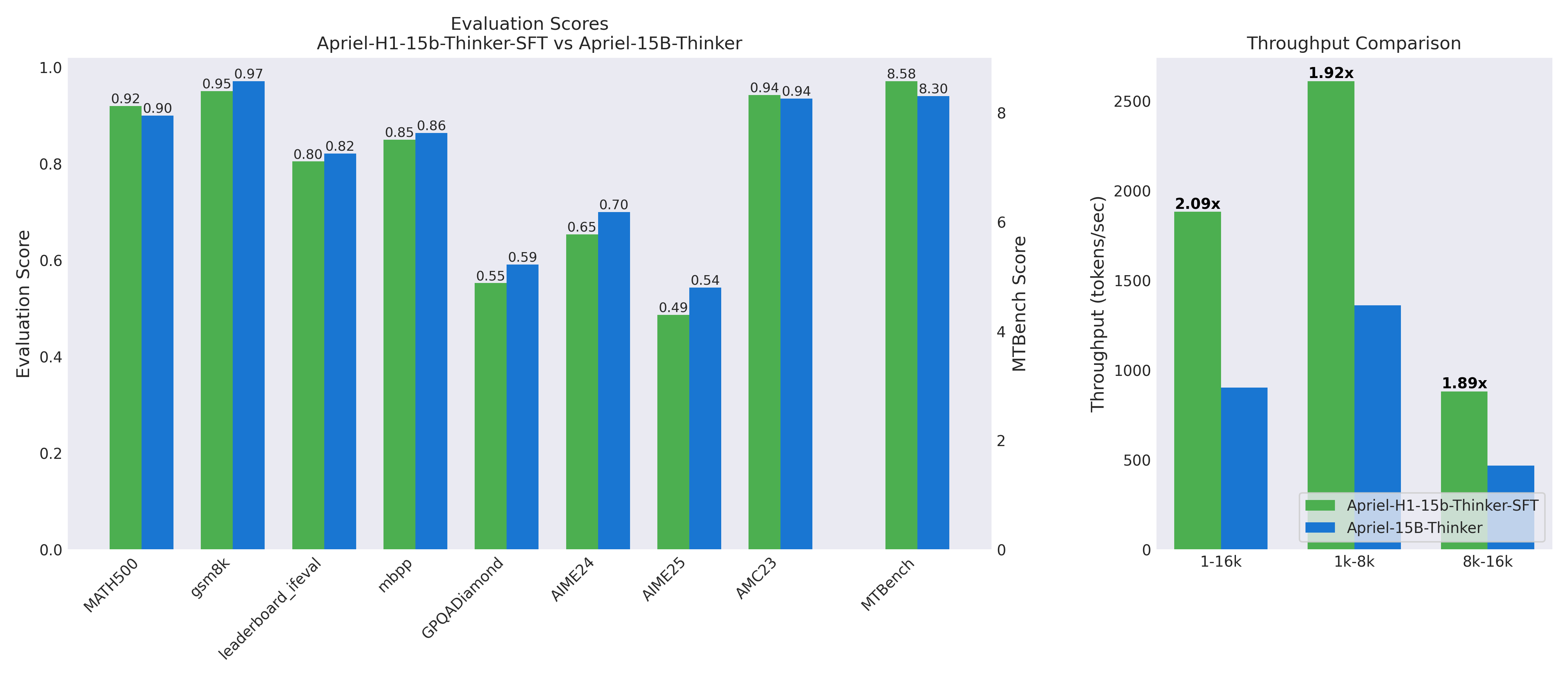
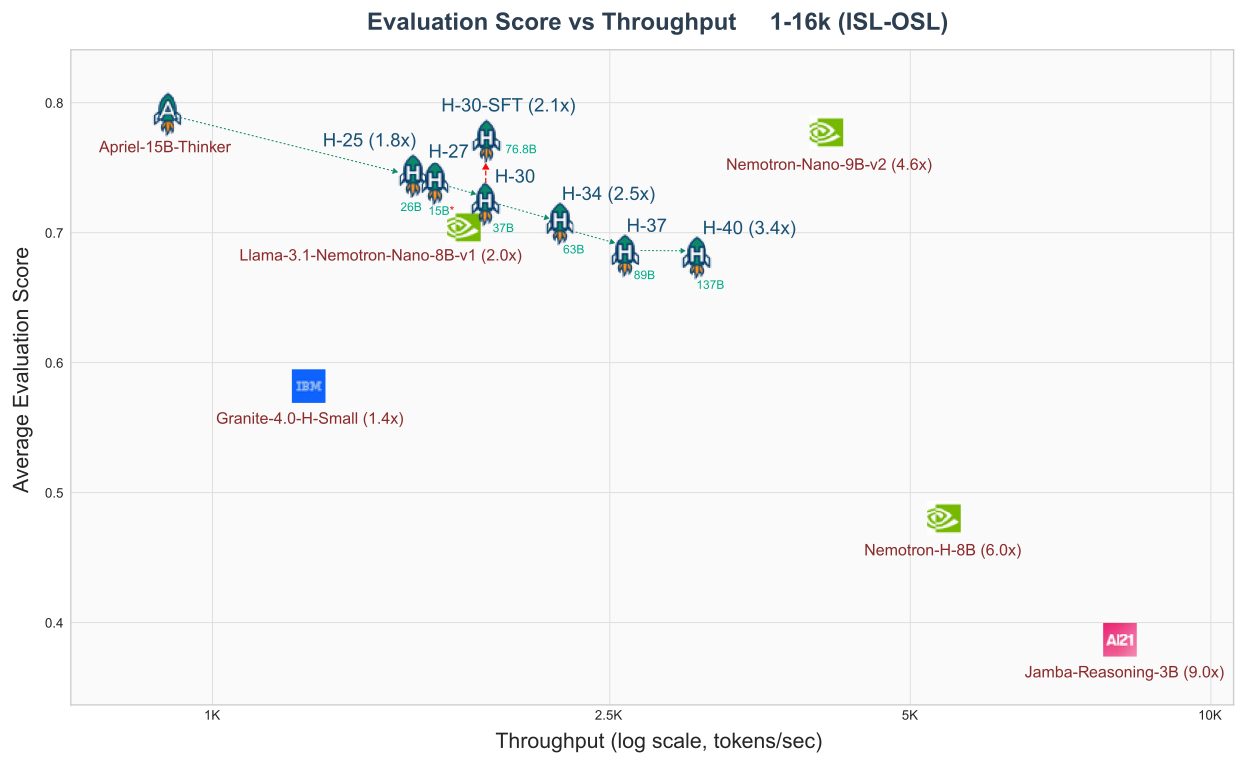
그 결과, 처리 속도가 최대 2.1배(최적 설정에 따라 3배 이상까지) 향상!
눈여겨볼 점: 품질 저하는 거의 없고, 심지어 일부 테스트(수학 문제, 코드 추론 등)에서는 오히려 성능이 향상되는 경우도 있었다는 점입니다.
 이미지 출처: huggingface
이미지 출처: huggingface
{kind=link}
데이터만 바꿨는데… 직관을 뒤집은 증류 방식의 반전
보통은 모델 증류(원래 모델의 ‘지식’을 새 모델에 전달)는 사전훈련(pretraining) 데이터를 크게 사용합니다. 그런데 Apriel-H1 연구진은 ‘직관’을 과감하게 버렸습니다.
실전에서 놀랍게도, ‘일반적인 대용량 텍스트’ 말고 ‘고품질 추론 트레이스(정교하게 정답에 도달한 과정, 예: 수학 풀이, 논리 단계, 코드 동작 등)만 집중해서 사용’하는 것이 훨씬 효율적임을 발견했습니다.
왜 그럴까요?
기존 사전훈련 데이터는 너무 방대하고 흩어진 잡음이 많아 추론 능력이 희석됨.
모델이 실제로 보존해야 할 것은 ‘여러 단계의 논리적 추론 패턴’. 이걸 담은 데이터만 증류하면, 마치 수학 문제 풀이 과정을 반복 학습하는 것처럼 ‘추론 체력’이 직접적으로 전달되어 효율과 품질을 모두 잡게 된 것입니다.
이 과정에서 ‘reverse KL divergence’라는 방식(=정답에 더 확신하는 쪽으로 학습을 유도함)이 효율에 결정적 역할을 했다고 하네요.
단계별 레이어 교체: 효율화에는 전략이 필요하다!
모든 ‘어텐션’ 레이어를 한 번에 바꿔치기 하면 모델이 무너집니다. 실제로 Apriel-H1 프로젝트도 신중한 ‘단계별 전략’을 썼습니다.
먼저 중요도가 가장 낮은 레이어 25개를 교체(LOO 분석으로 선정).
그 다음, 남은 각 레이어들이 실제로 바뀌었을 때 손실이 얼마나 줄어드나 동적으로 평가(MMR 기법)해서 가장 바꾸기 쉬운 것부터 차례로 교체.
마지막에는 전체 모델을 다시 한 번 정교하게 SFT(정제된 데이터로 추가 학습)해 품질을 확실히 고정.
이런 식으로 단계적으로 하이브리드 구조를 만들면, 기존 지능과 효율 모두를 지키면서 확실한 처리량 증가를 달성할 수 있습니다.
 이미지 출처: huggingface
이미지 출처: huggingface
{kind=link}
Fast-LLM: 누구나 재현 가능한 AI 모델 증류
Apriel-H1의 또 다른 강점은 누구든 실험해볼 수 있는 ‘오픈소스 프레임워크’를 제공한다는 점입니다.
Fast-LLM이라는 툴은 모델 구조를 블록 단위로 자유롭게 바꿀 수 있고, Mamba와 어텐션을 조합하는 패턴까지 설정 파일로 손쉽게 지정 가능합니다.
대형 모델의 분산 처리, 병렬 학습, 체계적인 체크포인트 관리… 실험하고자 하는 연구자, 개발자라면 누구든 직접 효율화 실험을 시도할 수 있어 AI 분야의 ‘실용적 혁신’으로 주목받고 있습니다.
효율적 AI 추론, 현장에선 왜 더 중요해졌을까?
최근 연구에 따르면 LLM 추론은 AI 서비스 전체 에너지의 90% 이상을 차지하고, 기업의 운영비용도 폭증 중입니다.
AI를 사용하는 모든 현장(챗봇, 서비스 자동화, 로봇 제어, 대규모 데이터 처리 등)에서는 기존의 ‘큰 모델=좋은 성능’ 공식이 ‘빠르고, 저렴하고, 정확해야 실전에서 살아남는다’로 바뀌고 있습니다.
Apriel-H1은 대규모 계산 자원이 없는 대부분의 팀들에게도 ‘현실적으로 유용한 효율 증대 방법’을 공개한 셈이죠.
게다가, Mamba 기반 하이브리드 구조는 자연어 처리 뿐만 아니라 의학 이미지 분할, 지리 공간 데이터 분석, 3D 포인트 클라우드까지 다양한 AI 분야에서 이미 활용되고 있습니다. 효율과 유연성 측면에서 신기술의 가능성을 넓혔죠.
요약 및 실무 조언: “똑같이 따라하지 말고, 작업 목표에 맞는 데이터와 구조를 선택하세요!”
Apriel-H1의 사례에서 우리가 얻을 교훈은 뚜렷합니다.
모델 효율화를 고민할 때, 반드시 ‘보존하고 싶은 기능(예: 추론력, 창의적 풀이, 논리적 구조 등)’에 맞는 데이터만 골라서 증류하라!
레이어 교체는 단계별로, 구조적 중요도가 낮은 부분부터 시작하며 천천히 발전을 누적하라!
오픈소스 프레임워크 활용하면 어렵지 않게 증류 실험을 재현해볼 수 있다.
미래 AI 응용 현장에서는 효율과 품질의 균형이 필수입니다.
만약 여러분이 이미 탄탄한 AI 모델을 갖고 있고, 처리 속도와 현실적인 비용이 고민이라면 — Apriel-H1의 방식을 시도해보세요.
“많이 배운 AI가 똑똑하면서도 빨라지려면, 똑똑해진 방식을 중심으로 집중해서 가르쳐라!”
이것이 효율적 인공지능 시대의 새로운 정답입니다.
참고
[1] Apriel-H1: The Surprising Key to Distilling Efficient Reasoning Models - Hugging Face
[2] TokenPowerBench: Benchmarking the Power Consumption of LLM Inference - arXiv
[4] Towards Robust Medical Image Segmentation with Hybrid CNN–Linear Mamba - MDPI
[5] DM3D: Deformable Mamba via Offset-Guided Gaussian Sequencing for Point Cloud Understanding - arXiv
[6] List of large language models - Wikipedia
[7] Large Language Models for Robotics: A survey - arXiv