

RapidFire AI로 20배 빨라진 AI 파인튜닝: 단일 GPU로 집단 실험 시대 연다
AI 모델의 성능을 끌어올리는 '파인튜닝'—하지만 여러 실험을 돌려보고 싶어도 시간, 비용, 하드웨어에 늘 발목이 잡혔던 게 현실이었습니다. 그런데 Hugging Face의 TRL 라이브러리와 RapidFire AI가 만나면서 이 문제를 아주 근본적으로 뒤집었습니다. 이제 단일 GPU에서도 집단 실험이 가능하고, 그 속도도 기존보다 최대 20배까지 빨라집니다. 도입부에서 핵심 기술의 개념과 혁신의 요점을 먼저 짚고, RapidFire AI가 어떻게 인공지능 파인튜닝 환경을 판 바꿨는지 차근차근 정리해봅니다.
기존 파인튜닝의 한계와 RapidFire AI가 해결한 문제
인공지능 개발 현장에서 파인튜닝이나 후속 훈련은 필수 작업이지만, 현실은 녹록지 않았습니다. 모델 구성별로 하이퍼파라미터를 비교해보고 싶어도, 많은 개발자들은 시간과 GPU 자원 부족 때문에 값비싼 '하나씩 돌려보기'에 의존해왔죠. 예를 들어 러닝레이트, LoRA Rank, 배치 사이즈, 옵티마이저 등 여러 가지 변수들을 하나하나 조합하며 실험하려면 하루에 2~3가지 설정보다 더 해보기 힘들었습니다. 직관에 의존하거나 커뮤니티에서 유행하는 설정을 그대로 사용하는 악순환이 이어졌던 겁니다.
RapidFire AI의 등장으로 이런 틀을 완전히 깼습니다. TRL과 공식적으로 통합되면서, 이제 단일 GPU에서도 여러 실험을 동시에 실행하고 실시간으로 성능을 비교할 수 있습니다. 대규모 하이퍼파라미터 탐색이 집단 실험 형태로 손쉽게 가능해진 것입니다.
RapidFire AI의 핵심 기술: 데이터 청크 분할과 동시 실험
RapidFire AI의 최대 강점은 'Adaptive Chunk-based Scheduling'입니다. 데이터셋을 여러 조각(청크)으로 나누고, 각 모델 설정(예: SFT, DPO, GRPO 등)을 한 청크 단위로 돌아가며 병렬로 학습시킵니다. 전통적 방식이 전체 데이터셋을 한 설정으로 다 돌린 뒤에야 다음 설정을 시도했다면, RapidFire AI는 각각의 설정을 한 조각씩 처리하며 일찍 비교가 가능합니다.
예를 들어 4개의 하이퍼파라미터 조합을 실험한다면, RapidFire AI는 데이터 첫 청크만 처리해도 모든 조합의 성능 변화(예: 손실 값)를 동시에 비교할 수 있습니다. 만약 특정 설정이 나쁘면 그 즉시 중단하고, 좋은 설정에는 리소스를 더 집중하죠. 이 early stopping과 실시간 리얼타임 관리는 특히 소규모 GPU 환경에서 실험 속도를 비약적으로 높여줍니다.
 이미지 출처: huggingface
이미지 출처: huggingface
{kind=link}
RapidFire AI의 공유 메모리 전략 덕에, PEFT(파라미터 효율적 파인튜닝) 실험에서는 '기본 모델'을 한 번만 띄우고 LoRA와 기타 설정만 빠르게 바꿔가며 병렬 처리합니다. 덕분에 60% 수준이었던 GPU 사용률이 95% 이상까지 올라가며 시간과 비용을 획기적으로 줄이고, 데이터 I/O 병목 현상을 해소합니다.
실시간 대시보드와 대화형 실험 제어 기능
RapidFire AI는 MLflow 기반의 실시간 대시보드를 제공합니다. 모든 실험의 손실 곡선, 평가 지표, 로그를 한눈에 볼 수 있고, 실행 중인 실험을 대시보드에서 즉시 중단, 복제, 설정 변경, Warm Start 실행까지 세밀하게 제어할 수 있습니다. 만약 한 설정의 손실 곡선이 예쁘게 내려간다면 'Clone-Modify' 기능으로 바로 복제하여 하이퍼파라미터만 살짝 바꿔 추가 실험도 할 수 있습니다.
이 대화형 실험 제어(Interactive Control Ops)는 단순히 결과 기다리던 기존 방식 대비, '실시간 실험 관리'를 가능케 하는 핵심 기능입니다. 결국 모델 개발 과정을 사람의 직관이 아닌 데이터 기반의 빠른 의사결정 시스템으로 업그레이드시키는 셈입니다.
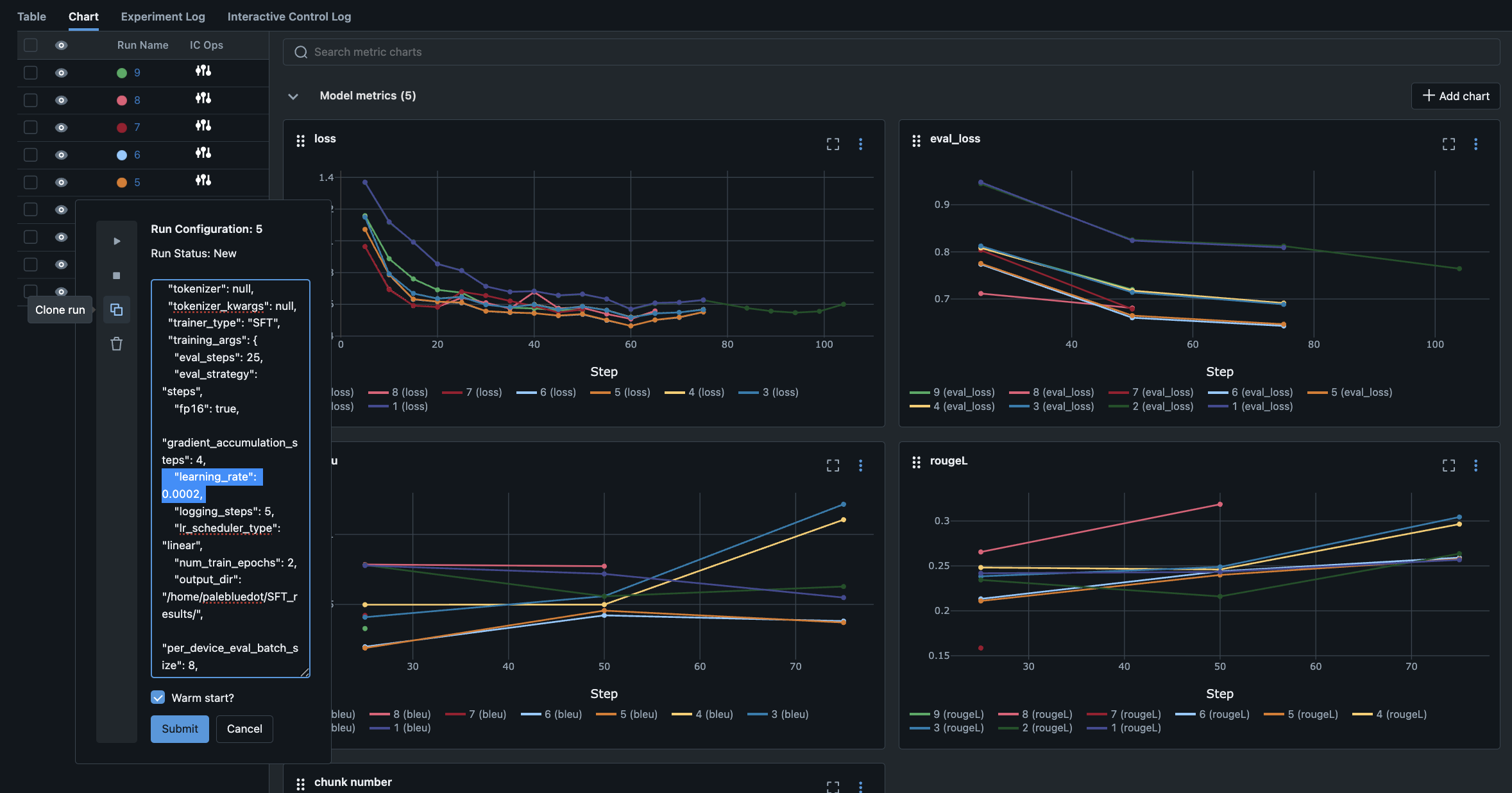 이미지 출처: huggingface
이미지 출처: huggingface
{kind=link}
실제 벤치마크: 20배 빠른 실험, 월등한 GPU 활용률
RapidFire AI가 실전에서 보여준 성능은 매우 인상적입니다. 공식 벤치마크에 따르면, 단일 A100 GPU에서 4~8개 실험 조합을 한꺼번에 비교할 경우, 기존에는 각 실험마다 120~240분이 필요하던 것이 RapidFire AI 방식에서는 7~12분이면 결정적 비교 결과에 도달합니다. 즉, GPU의 계산 자원을 거의 완벽에 가깝게 활용하면서, 하루에 수십 가지 파라미터 조합을 검증할 수 있게 된 것입니다.
| 시나리오 | 기존 방식 시간 | RapidFire AI 시간 | 속도 배율 |
|---|---|---|---|
| 4개 설정, 1 GPU | 120분 | 7.5분 | 16x |
| 8개 설정, 1 GPU | 240분 | 12분 | 20x |
| 4개 설정, 2 GPU | 60분 | 4분 | 15x |
| 학생이나 개인 개발자가 RTX 4090, 혹은 소규모 클라우드 GPU로도 입체적인 모델 비교를 빠르고 저렴하게 할 수 있다는 점에서, AI의 '민주화'가 다시 한 번 현실로 다가온 것입니다. |
TRL과 RapidFire AI 통합 방식: 쉽고 직관적인 진입
RapidFire AI는 Hugging Face의 TRL SFT, DPO, GRPO 트레이너와 완벽히 호환됩니다. 기존 TRL 사용자가 SFTConfig, DPOConfig, GRPOConfig를 RFSFTConfig, RFDPOConfig, RFGRPOConfig로 대체하면, 거의 코드 수정 없이 바로 집단 실험이 가능합니다.
설치 또한 간단합니다. pip install rapidfireai로 패키지 설치 후, Hugging Face 인증만 완료하면 모든 기능을 쓸 수 있습니다.
특히 대시보드에서 여러 실험을 '실시간'으로 감시하고 즉시 수정할 수 있으므로, 하이퍼파라미터 스캔, 튜닝, 빠른 모델 배포까지 일련의 AI 개발 생산성을 근본적으로 끌어올릴 수 있습니다.
단일 GPU도 집단 실험, 모델 최적화의 뉴노멀
RapidFire AI의 끝판왕적 가치는, 더 이상 '리소스가 부족해서 그냥 굴리는' 세상을 만들지 않는다는 데 있습니다. 대규모 설정 비교와 빠른 실험 회전, 그리고 그 결과의 실시간 피드백—이제 AI 개발자는 하나의 실험만 며칠씩 돌릴 필요가 없습니다. 빠른 실험과 데이터 기반 의사결정, 그리고 비용 절감까지 모두 챙길 수 있는 시대가 열린 것이죠.
이러한 새로운 워크플로우는 특히 TRL 기반의 SFT, DPO, GRPO 같은 고급 파인튜닝, 그리고 앞으로 Agent 평가와 RAG(검색 기반 생성) 시스템 실험 등에도 확장될 예정입니다. 이제 AI 실험은 감이 아니라 데이터와 직접 대화하며, 단일 GPU로 집단 연구의 효율을 누릴 수 있습니다.
실용적 조언과 시사점
RapidFire AI의 등장과 TRL의 공식 통합은 단순한 기술 혁신 이상입니다. 파인튜닝의 진입 장벽을 크게 낮추어, 개인 개발자부터 연구소, 기업까지 모두가 과학적이고 체계적으로 모델 최적화에 도전할 수 있게 되었습니다.
만약 당신이 AI 모델 개발 속도를 높이고 싶거나, 다양한 하이퍼파라미터의 성능을 짧은 시간에 비교하고 싶다면 RapidFire AI와 TRL 통합을 적극 활용해 보길 권합니다. 더 똑똑한 실험, 더 빠른 모델 개선—이제 당신의 GPU가 상상 이상으로 일할 준비가 되어 있습니다.
참고
[1] RapidFire AI로 20배 빠른 TRL 파인튜닝 공식 블로그 - Hugging Face
[2] 단일 GPU로 집단 실험, Hugging Face TRL과 RapidFire AI의 초병렬 혁신 - Tencent News
[3] TPU vs GPU: 2025년 AI 하드웨어 전쟁 - Binary Verse AI