
Z-Image: 고품질 초고속 AI 이미지 생성기 특징과 사용법 총정리
핵심 요약
Z-Image는 6B 파라미터의 단일 스트림 Diffusion Transformer 기반 이미지 생성 모델로, 소수 스텝만으로도 고품질 이미지를 빠르게 생성하는 것이 특징입니다. Turbo·Base·Edit 세 가지 변형과 Decoupled-DMD·DMDR 같은 독자적인 고속화·고성능 알고리즘이 핵심 기술입니다.
Z-Image 프로젝트 한눈에 보기
Z-Image는 알리바바 Tongyi Lab이 공개한 대규모 이미지 생성 기초 모델입니다. 텍스트 프롬프트를 입력하면 고해상도 이미지를 생성하며, 사람 사진, 풍경, 일러스트 등 다양한 스타일을 다룹니다.
이 프로젝트의 목표는 단순히 이미지를 잘 만드는 것을 넘어서, 적은 계산량으로 빠른 응답을 제공하면서도 상용 서비스에 바로 쓸 수 있을 수준의 품질과 안정성을 확보하는 것입니다. 이를 위해 모델 아키텍처, 학습 방법, 추론 가속까지 전 과정을 함께 설계했습니다.
라이선스는 Apache-2.0으로, 연구와 상업적 활용 모두에 유리한 오픈소스 정책을 따릅니다.
세 가지 주요 변형: Turbo · Base · Edit
Z-Image는 용도에 따라 세 가지 변형으로 나뉩니다.
Turbo 버전은 실사용에 초점이 맞춰진 증류 모델입니다. 약 8번 정도의 모델 호출(NFE)만으로 고품질 이미지를 내기 때문에, 서버용 H800 GPU에서는 거의 실시간에 가까운 응답 속도를 제공합니다. 또한 16GB VRAM 소비자용 GPU에서도 동작하도록 설계되어 개인 개발 환경에서도 활용이 가능합니다.
Base 버전은 아직 공개 예정이지만, 증류 전의 풀 사이즈 기반 모델로, 커뮤니티가 이를 바탕으로 추가 파인튜닝이나 특화 모델을 만들 수 있도록 하기 위한 목적입니다.
Edit 버전은 이미지 편집에 특화된 변형입니다. 기존 이미지를 입력하고, 자연어로 "배경을 밤하늘로 바꿔줘", "문구를 중국어로 교체해줘" 같은 지시를 내리면, 지시에 맞춰 이미지를 수정합니다. 특히 영어와 중국어를 모두 잘 이해하는 편집 능력을 목표로 합니다.
단일 스트림 Diffusion Transformer 아키텍처
Z-Image는 S3-DiT(Scalable Single-Stream Diffusion Transformer)라는 구조를 사용합니다. 이 구조의 핵심은 텍스트 토큰, 시각적 의미 토큰, VAE 이미지 토큰을 따로 처리하지 않고 하나의 긴 시퀀스로 이어 붙여 Transformer에 넣는다는 점입니다.
기존에는 텍스트와 이미지를 별도의 스트림(dual-stream)으로 처리한 뒤 결합하는 방식이 많았습니다. 단일 스트림 방식은 모든 정보가 같은 Transformer 층을 공유하므로, 파라미터를 더 효율적으로 활용할 수 있고, 텍스트와 이미지 사이의 상호작용도 자연스럽게 일어납니다.
이를 도식화한 구조는 다음 그림처럼 텍스트 임베딩, 이미지 토큰, 편집 조건 등이 하나의 타임라인 상에서 쭉 이어져서 처리된다고 생각하면 이해하기 쉽습니다.
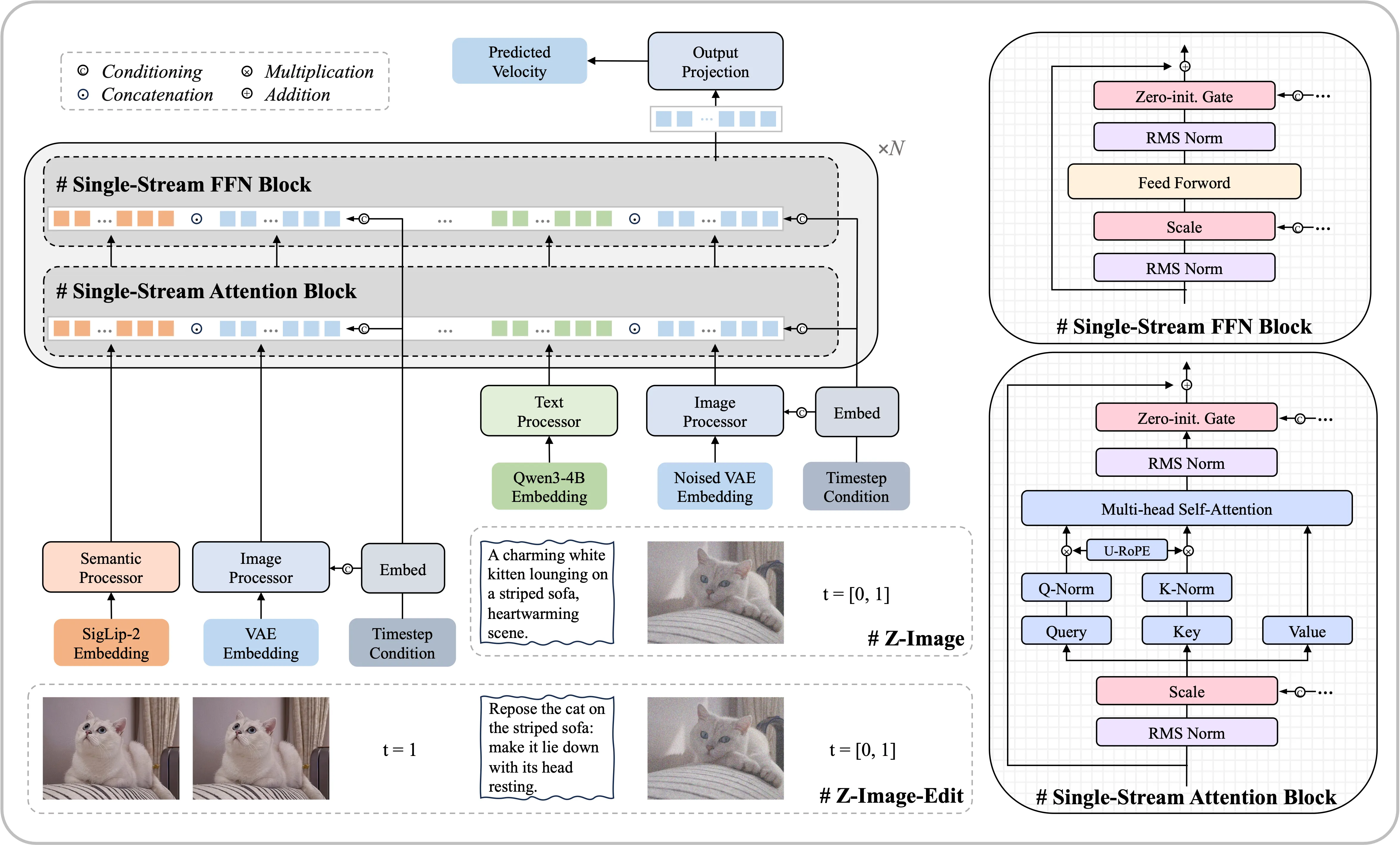
성능 특징: 포토리얼, 텍스트 렌더링, 추론 속도
Z-Image-Turbo는 사람 얼굴·실사 사진과 같은 포토리얼 이미지에서 강한 성능을 보이며, 동시에 예술적·미학적 품질도 유지하도록 튜닝되어 있습니다. 홍보 이미지들을 보면 피부, 머리카락, 조명 표현 등이 자연스럽고, 배경 디테일도 풍부한 편입니다.
또 하나의 강점은 텍스트 렌더링입니다. 영어뿐 아니라 중국어 텍스트를 이미지 속에 정확히 그려 넣는 능력이 좋습니다. 간판, 포스터, 손글씨 스타일 글자 등을 프롬프트대로 꽤 정확히 구현할 수 있도록 설계되었습니다.
추론 속도 측면에서는 8 NFE 정도의 소수 스텝만으로도 고품질을 내기 때문에, 일반적인 다단계 확산 모델보다 훨씬 빠르게 결과를 얻을 수 있습니다. 이 덕분에 웹 서비스, 실시간 디자인 도구 등에 넣어도 사용자 경험이 좋아질 수 있습니다.
Z-Image 사용 방법: diffusers 파이프라인
Z-Image-Turbo는 Hugging Face diffusers에 통합되어 있어, 파이썬 코드 몇 줄로 바로 사용할 수 있습니다. 단, 최신 기능 지원을 위해 diffusers를 GitHub 소스에서 설치해야 한다는 점이 중요합니다.
설치 명령은 다음과 같습니다.
pip install git+https://github.com/huggingface/diffusers추론 코드는 다음과 같은 흐름입니다.
ZImagePipeline을 bfloat16 타입으로 GPU에 로드합니다.
필요하다면 Flash Attention, 모델 컴파일, CPU offload 등을 설정해 메모리와 속도를 튜닝합니다.
prompt, 높이·너비, num_inference_steps, guidance_scale(터보는 0 사용), 시드 등을 지정해 이미지를 생성합니다.
import torch
from diffusers import ZImagePipeline
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=False,
)
pipe.to("cuda")
prompt = "Young Chinese woman in red Hanfu, ..."
image = pipe(
prompt=prompt,
height=1024,
width=1024,
num_inference_steps=9, # 실제로는 8번 DiT 호출
guidance_scale=0.0, # Turbo는 0으로 사용
generator=torch.Generator("cuda").manual_seed(42),
).images[0]
image.save("example.png")실전에서 쓸 때는 해상도·스텝 수를 줄여 초안을 빠르게 보고, 마음에 들면 해상도를 올려 다시 생성하는 방식이 효율적입니다.
Decoupled-DMD: 소수 스텝 증류의 핵심 아이디어
Z-Image의 빠른 추론을 뒷받침하는 핵심 기술 중 하나가 Decoupled-DMD입니다. 이는 기존 Distribution Matching Distillation(DMD) 계열 방법을 분석해, 실제로 성능을 끌어올리는 요소와 품질을 안정시키는 요소를 분리한 알고리즘입니다.
저자들의 관찰에 따르면, 기존 DMD에서 가장 큰 역할을 하는 것은 "CFG(Classifier-Free Guidance)를 활용한 증강 효과"이고, 진짜 분포 매칭 손실은 규제자 역할에 가깝습니다. Decoupled-DMD는 이 둘을 분리해 각각을 최적으로 조정함으로써, 8스텝 같은 소수 스텝 모델에서도 고품질 이미지를 만들 수 있도록 합니다.
쉽게 말해, "엔진 역할을 하는 학습 신호"와 "브레이크 역할을 하는 안정화 신호"를 분리해서 개별 튜닝을 하니, 더 빠르면서도 안전하게 달리는 자동차를 만든 셈입니다.
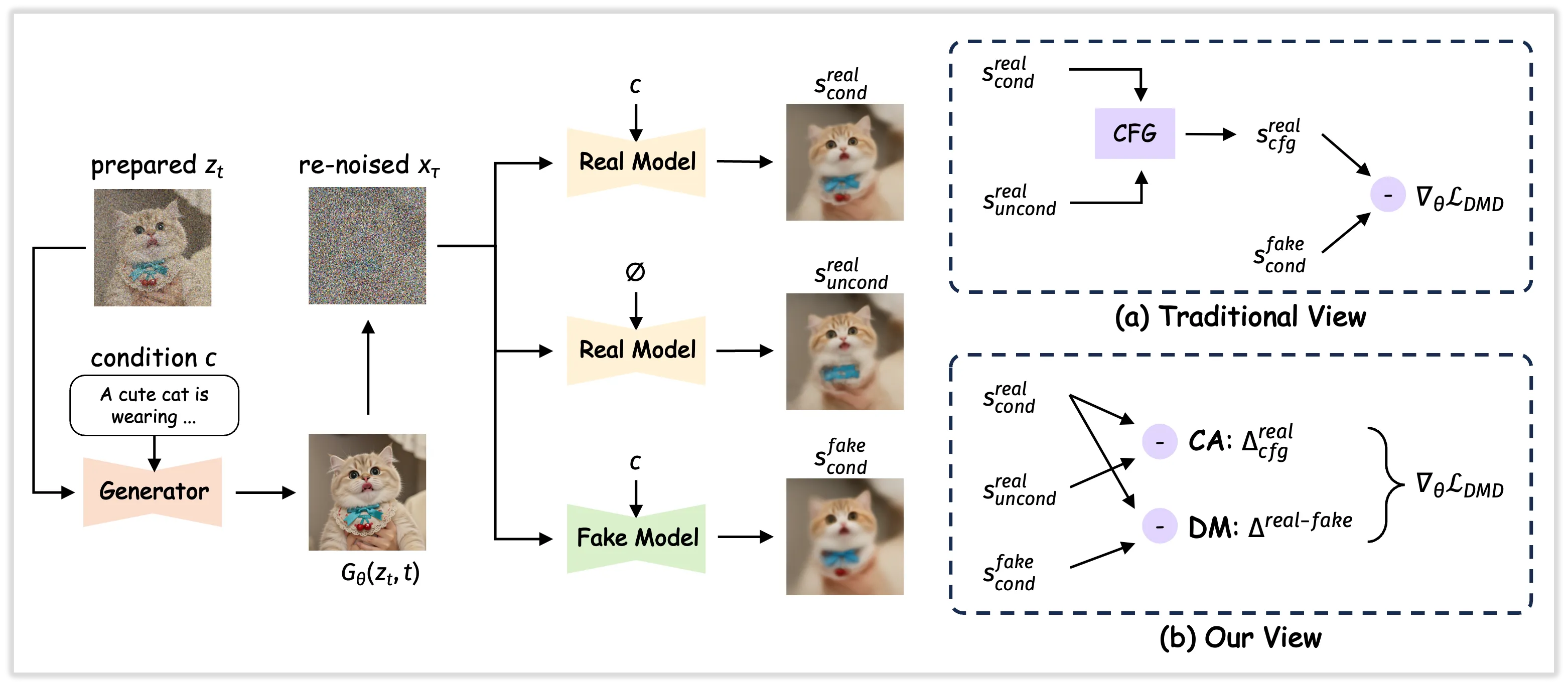
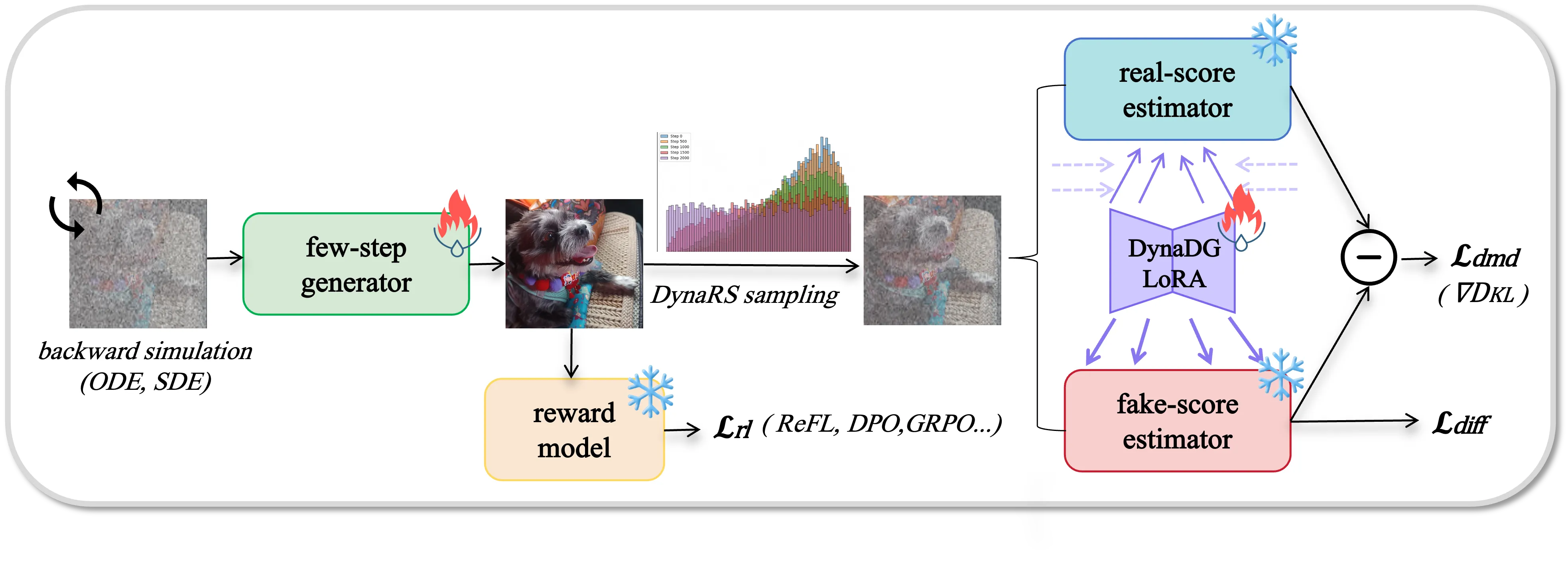
DMDR: Distillation과 강화학습의 결합
DMDR은 Decoupled-DMD 이후 단계에서, 소수 스텝 모델을 더 한 번 끌어올리기 위해 제안된 방법입니다. 여기서는 DMD 기반의 분포 매칭과 강화학습(RL)을 통합해, 사용자가 선호하는 방향으로 이미지를 더 정교하게 개선합니다.
이 접근의 핵심은 두 가지 상호 보완적 역할입니다. 강화학습은 미학, 내용 일치, 구조적 일관성처럼 주관적이거나 복잡한 목표를 밀어붙여 성능을 강화하는 역할을 합니다. 동시에 DMD는 모델이 지나치게 치우치거나 붕괴되지 않도록 분포를 정규화하는 방패 역할을 합니다.
이 조합을 통해, 단순히 "평균적으로 괜찮은 이미지"를 만드는 수준을 넘어, 고주파 디테일과 구조적 완성도가 높고, 프롬프트와 의미적으로 더 잘 맞는 이미지를 만들도록 조정할 수 있습니다.
커뮤니티 생태계와 경량 추론 활용
Z-Image는 독자 생태계뿐 아니라 외부 프로젝트와의 연동도 활발합니다. 예를 들어 Cache-DiT는 Z-Image를 대상으로 DBCache, 컨텍스트 병렬, 텐서 병렬 등을 활용해 대규모 환경에서의 추론을 가속화하는 예시를 제공합니다.
또한 stable-diffusion.cpp는 순수 C++ 기반의 확산 모델 엔진으로, Vulkan·CUDA 등 다양한 백엔드를 통해 메모리 효율이 높은 추론을 지원합니다. 이를 활용하면 4GB VRAM 정도의 소형 GPU에서도 Z-Image로 이미지를 생성하는 것이 가능해집니다.
이러한 도구들을 활용하면, 클라우드 서버뿐만 아니라 개인 PC, 경량 워크스테이션, 심지어 일부 내장 GPU 환경에서도 Z-Image를 실험해 볼 수 있습니다.
인사이트
Z-Image는 "고품질·고속·실사용 가능성"을 동시에 겨냥한 세대의 이미지 생성 모델로, 단일 스트림 DiT 아키텍처와 Decoupled-DMD·DMDR 같은 학습 기법이 핵심입니다. 실무 관점에서 중요한 포인트는 Turbo 체크포인트와 diffusers 파이프라인을 이용해 손쉽게 통합할 수 있고, Flash Attention·모델 컴파일·CPU offload·C++ 엔진(stable-diffusion.cpp) 등으로 속도와 메모리를 탄력적으로 조절할 수 있다는 점입니다.
연구자 입장에서는 소수 스텝 확산 모델의 증류·강화학습 결합 사례, 단일 스트림 구조 설계, 인간 선호 기반 평가(AI Arena Elo) 등 많은 실험 아이디어를 얻을 수 있습니다. 개발자라면 우선 Z-Image-Turbo를 활용해 작은 해상도에서 빠르게 프로토타입을 만든 뒤, 추론 환경(서버/로컬)에 맞춰 최적화 옵션과 커뮤니티 도구들을 조합해보는 접근을 추천합니다.
출처 및 참고 : Tongyi-MAI/Z-Image
이 노트는 요약·비평·학습 목적으로 작성되었습니다. 저작권 문의가 있으시면 에서 알려주세요.