
SAM 3D와 3D 객체 인식 AI 모델 개요
개요
SAM 3D는 Meta가 공개한 단일 2D 이미지로부터 사물과 사람의 3D 형상과 텍스처, 자세를 추정하는 AI 모델로, 자연스러운 실제 환경 이미지에서 동작하는 3D 재구성(generative 3D reconstruction)에 초점을 맞춘 것이 특징이다12. 기존 3D 모델들이 주로 깨끗한 스튜디오 샷이나 합성 데이터에 의존했다면, SAM 3D는 복잡한 실세계 장면에서 가려짐과 잡동사니가 많은 상황까지 다루도록 설계되었다12.

SAM 3D는 크게 물체·장면 재구성을 담당하는 "SAM 3D Objects"와 사람의 포즈와 체형을 복원하는 "SAM 3D Body" 두 모델로 구성된다12. 이 모델들은 "Segment Anything" 계열의 이미지 분할·인식 능력을 바탕으로, 선택한 객체를 3D 메쉬(mesh)로 변환해 AR/VR, 게임, 로보틱스 등 다양한 응용에서 바로 사용할 수 있는 수준의 결과물을 생성하는 것을 목표로 한다134.
3D 객체 인식·재구성의 기본 개념
3D 객체 인식·재구성 모델은 2D 이미지나 비디오를 입력으로 받아, 장면 속 개별 물체의 3차원 형상(기하), 표면 질감(텍스처), 그리고 공간 배치(레이아웃)를 추정한다2. 여기서 "인식"은 어떤 물체인지를 구분하고 위치와 범위를 파악하는 과정이고, "재구성"은 인식된 물체를 3D 모델 형태로 만들어 다양한 시점에서 볼 수 있게 하는 과정이다.
실세계 이미지는 조명, 가려짐, 저해상도, 복잡한 배경 등으로 인해 동일한 물체라도 매우 다양한 모습으로 나타나기 때문에, 단순한 기하학 규칙만으로는 복원이 어렵다. SAM 3D 류의 모델은 대규모 데이터와 학습된 시각·맥락 이해 능력을 이용해, 보이지 않는 부분의 형태까지 "상식에 맞게" 보완하는 방식을 취한다12. 덕분에 사용자는 한 장의 사진에서 물체를 클릭해 선택만 하면, 나머지는 모델이 알아서 3D로 "채워 넣는" 사용 경험을 제공할 수 있다1.
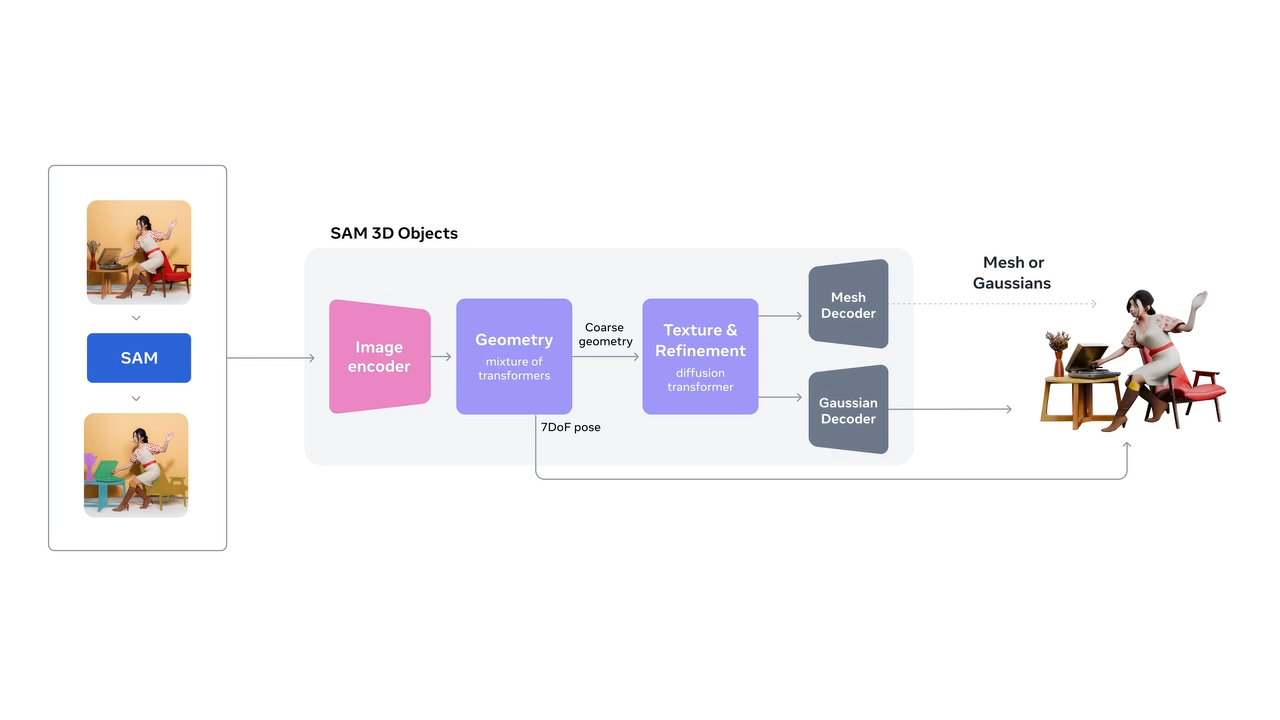
SAM 3D의 위치와 특징
SAM 3D는 "Segment Anything Model(SAM)" 계열의 확장판으로, 2D 분할에서 3D 재구성까지 범위를 넓힌 모델이다12. SAM 3가 텍스트·이미지 프롬프트로 이미지·비디오 내 개념 기반 객체를 탐지·분할·추적하는 데 집중한다면, SAM 3D는 이렇게 찾은 객체를 실제로 3D 메쉬 형태로 만들어 주는 역할을 한다25.
Meta는 SAM 3D를 위해 모델 체크포인트, 추론 코드, 그리고 평가를 위한 벤치마크와 데이터셋을 공개하거나 공개 예정이라고 밝히고 있다123. 특히 SAM 3D Objects의 GitHub 저장소와 논문은 오픈소스 커뮤니티에서 높은 관심을 받고 있으며, Hugging Face의 트렌딩 논문 목록에서도 상위권에 오를 정도로 활발히 인용되고 있다3.
또한 Meta는 일반 사용자가 웹에서 이미지를 업로드하고 사람이나 물체를 선택해 바로 3D 재구성을 체험해 볼 수 있는 "Segment Anything Playground"를 제공해, 연구자뿐 아니라 크리에이터와 일반 사용자까지 활용 범위를 넓히고 있다1. 이처럼 SAM 3D는 연구 모델이면서 동시에 실제 제품 기능(예: Facebook Marketplace의 "View in Room" 기능)을 뒷받침하는 실용 기술로도 쓰이고 있다14.
공식 홈페이지에서 3D 모델을 다운로드 받거나 플레이그라운드를 돌려볼 수 있음.
SAM 3D Objects: 물체·장면 3D 재구성
SAM 3D Objects는 한 장의 자연 이미지에서 개별 물체를 선택하면, 그 물체의 3D 형상, 텍스처, 포즈(자세)와 장면 내 배치까지 추정해 주는 모델이다12. 사용자는 사진 속에서 테이블, 의자, 장난감 같은 물체를 하나씩 지정하고, 각각에 대해 별도의 3D 모델을 얻을 수 있으며, 이렇게 얻은 모델은 회전하거나 다른 카메라 시점으로 옮겨보는 등 다양한 뷰에서 시각화할 수 있다1.
이 모델은 특히 "실세계" 이미지를 노린 설계라는 점이 중요하다. 기존 3D 모델은 뒷배경이 단순하고 물체가 화면을 크게 차지하는 합성·스튜디오 이미지에 최적화된 경우가 많았지만, SAM 3D Objects는 작은 물체, 부분 가려짐, 복잡한 배경이 있는 일상 사진에서도 의미 있는 3D 재구성을 수행하도록 학습되었다12. 이를 위해 모델은 픽셀 정보만이 아니라 주변 맥락과 인식된 객체 유형 등의 정보를 활용해, 안 보이는 뒷면이나 가려진 부분을 일관성 있게 채운다1.
Meta의 설명에 따르면, SAM 3D Objects는 "시각적으로 근거 있는(grounded)" 재구성에 중점을 둔다. 이는 결과 3D 모델이 임의로 생성된 것이 아니라 실제 이미지의 관측 정보와 최대한 맞아떨어지면서도, 사람의 직관에 어긋나지 않는 형태를 가지도록 한다는 뜻이다12. 사람 평가에서 최근 모델들보다 최소 5:1 비율로 선호된다는 결과도 보고되었다고 한다23.
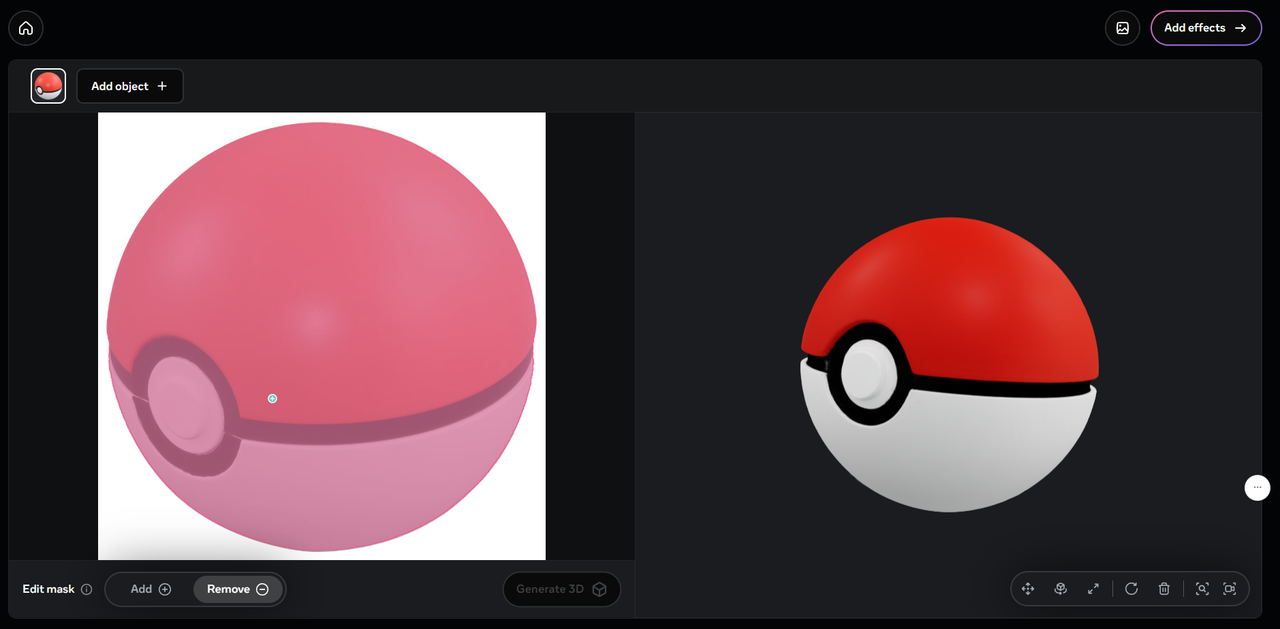
이런식으로 3D 물체로 바꿔준다. 너무 복잡한 사물일 경우는 잘 못하는 경우가 있었다.
SAM 3D Body: 전신 3D 인체 메쉬 복원
SAM 3D Body는 사람의 전신 포즈와 체형을 하나의 이미지로부터 3D 메쉬로 복원하는 모델이다2. 단순히 신체의 2D 관절 위치를 추정하는 수준을 넘어, 몸 전체·발·손까지 포함한 고해상도 3D 메쉬를 예측해 다양한 자세와 의상, 촬영 조건에서도 일관된 정확도를 유지하는 것을 목표로 한다2.
이 모델은 "Momentum Human Rig(MHR)"라는 새로운 파라메트릭 인체 표현을 사용하는데, 이는 골격 구조와 표면 형상을 분리해 표현함으로써, 다양한 체형과 포즈를 유연하게 다룰 수 있도록 설계되었다2. SAM 3D Body는 인코더-디코더 구조를 기반으로 하며, 기존 SAM 가족 모델처럼 2D 키포인트나 마스크 등 보조 프롬프트를 입력해 사용자 지정을 반영한 추론도 지원한다2.
데이터 측면에서는 수작업 키포인트 라벨링, 미분 가능한 최적화, 다중 뷰 기하학, 고밀도 키포인트 검출 등을 조합한 다단계 파이프라인으로 다양한 자세와 촬영 조건의 인체 데이터를 구축했다2. 이를 통해 특이한 포즈나 희귀한 촬영 환경까지 포함하는 데이터 분포를 확보해, 모델의 일반화 능력을 강화하는 것이 목표로 제시된다2.
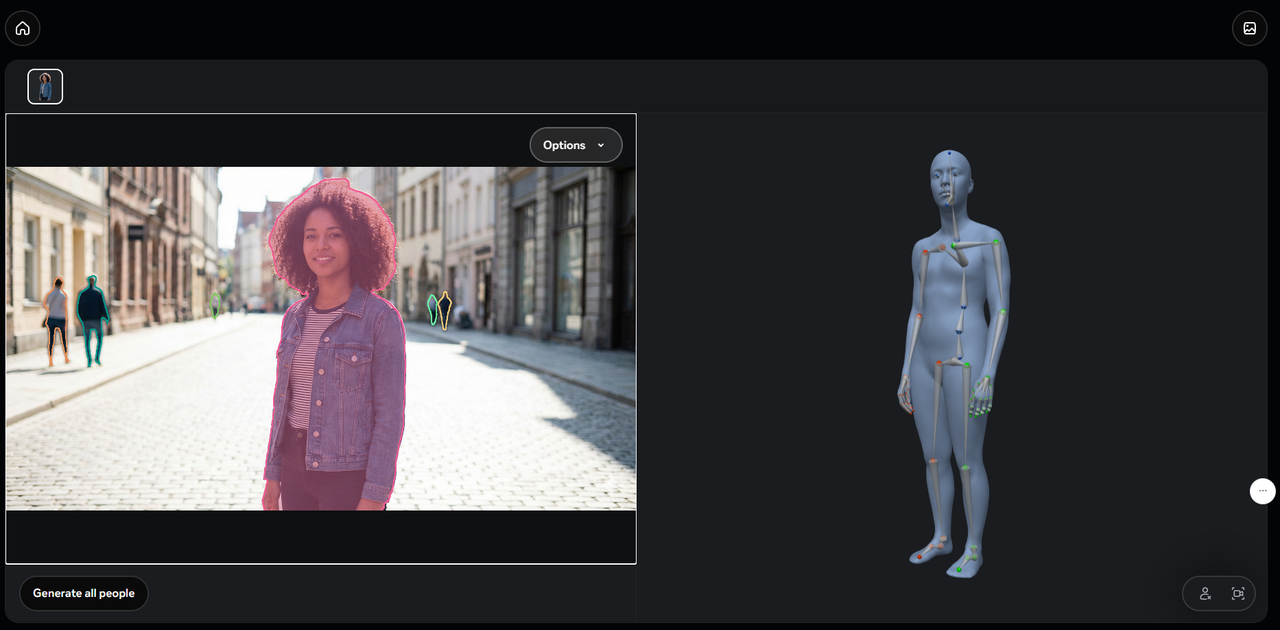
인체 모델은 오른쪽과 같이 3D 메시 형태로 만든다. 포즈 등을 바꿔서 이미지 생성 등에 유용할 듯 하다.
데이터 엔진과 학습 전략: 3D 데이터 장벽 돌파
3D 모델 연구에서 가장 큰 제약은 "데이터"다. 텍스트나 이미지와 달리, 고품질 3D 정답 데이터를 만드는 일은 전문 3D 아티스트의 작업이 필요하고 시간이 오래 걸린다. SAM 3D는 이 문제를 풀기 위해 "사람·모델-인-더-루프" 데이터 엔진을 도입해, 3D 데이터 수집을 대규모로 확장하는 방식을 제안한다12.
핵심 아이디어는 "처음부터 완벽한 3D를 만드는 것"이 아니라 "여러 후보 메쉬 중 더 나은 것을 평가·순위 매기기"라는 상대적으로 쉬운 작업으로 사람의 역할을 재정의하는 것이다1. 여러 3D 모델이 생성한 후보 메쉬들을 제시하고, 비전문가도 수행할 수 있는 품질 평가를 통해 가장 적합한 결과를 선택하거나 랭킹을 매기게 한다. 어려운 사례는 전문 아티스트에게 넘겨 데이터의 빈 구석을 채우는 식으로, 효율적인 데이터 수집을 구현한다12.
학습 전략 측면에서는, 대규모 합성 3D 자산으로 먼저 "사전학습(pre-training)"을 하고, 이후 실세계 이미지와 앞서 구축한 데이터 엔진을 활용한 "사후학습(post-training)"으로 정렬(alignment)을 수행하는, 자연어·LLM 분야에서 쓰이는 다단계 학습 레시피를 3D에 도입했다12. 즉, 합성 데이터로 기본 능력을 익히고, 실세계 데이터와 사람의 피드백으로 모델을 실제 환경에 맞게 조정한다. 이 반복 과정에서 모델이 좋아질수록 더 나은 후보 메쉬를 만들고, 그 결과 데이터 엔진도 더 양질의 레이블을 생산하는 "선순환 루프"를 형성하게 된다1.
Meta는 이러한 방법으로 약 100만 장에 가까운 실세계 이미지를 3D 형상·텍스처·레이아웃 정보와 함께 주석 처리하고, 300만 개가 넘는 모델-인-더-루프 메쉬를 생성했다고 밝힌다1. 또한 실세계 이미지 기반 3D 재구성의 난도를 제대로 반영하기 위해, 아티스트와 협업해 "SAM 3D Artist Objects(SA-3DAO)"라는 새로운 평가용 데이터셋도 구축했다1.
SAM 3 및 기타 모델과의 관계
SAM 3D는 SAM 3와 밀접한 관계를 가진 동시대 모델이다. SAM 3는 텍스트나 이미지 예시 등 "개념 프롬프트"로 이미지·비디오 속 특정 개념에 해당하는 객체를 탐지·분할·추적하는 모델로, 기존 SAM의 기능을 확장한 버전이다5. "노란 스쿨버스"나 "빨간 야구 모자"처럼 복잡한 언어 기술도 이해해 해당하는 객체들을 찾아내고 마스크를 생성할 수 있는 것이 특징이다45.
이와 달리 SAM 3D는 분할·인식 이후 단계인 3D 재구성을 담당하며, 둘은 Meta의 제품, 예를 들어 Facebook Marketplace의 "View in Room" 기능에서 함께 활용된다14. SAM 3가 사진 속에서 판매 물품을 정확히 분리하면, SAM 3D가 그 물체를 3D 모델로 만들어 사용자의 실제 방 안에 배치해보는 식의 기능이 가능해진다14. 이런 조합은 향후 AR 글라스, 가상 피팅, 실시간 장면 이해 등 다양한 분야에서 활용될 수 있는 기반 기술로 평가된다.
동시대 다른 3D 관련 모델들(예: Depth Anything 3와 같이 깊이·카메라 포즈·시점 변환에 강점을 가진 모델들)과 비교하면, SAM 3D는 특히 "단일 이미지 기반 객체 메쉬 생성"과 "실세계 장면에서의 시각적 정합성"에 집중한다는 점에서 차별화된다3. 즉, 3D 포인트 클라우드나 볼류메트릭 표현보다 메쉬 기반 결과물(게임·렌더링에 바로 쓰기 좋은 형식)에 강점을 둔 구성이라고 볼 수 있다23.
응용 분야와 활용 가능성
실용 관점에서 SAM 3D와 유사한 3D 객체 인식·재구성 모델은 다양한 산업에서 잠재력을 가진다. 전자상거래에서는 사용자가 올린 제품 사진만으로 자동 3D 모델을 생성해 "집에서 미리 배치해 보기"와 같은 AR 경험을 제공할 수 있고, 실제로 Meta는 Marketplace에서 가구·인테리어 제품의 3D 배치를 지원하는 기능에 SAM 3D와 SAM 3를 활용하고 있다14.
콘텐츠 제작 측면에서는 게임, 영화, 메타버스 환경에서 필요한 3D 자산을 보다 빠르게 만드는 도구로 활용될 수 있다. 크리에이터는 기존에 찍어 놓은 사진을 활용해 간단히 3D 오브젝트를 생성하고, 이를 편집해 새로운 장면을 구성할 수 있다1. 로보틱스와 자율주행 분야에서는 일상 환경에서 카메라로 관찰되는 물체의 3D 형상을 빠르게 이해함으로써, 물체 조작, 경로 계획, 충돌 회피 등에 활용할 수 있는 풍부한 장면 표현을 제공할 수 있다12.
연구와 교육에서도 복잡한 3D 데이터 수집 없이, 일반 이미지 데이터셋에서 3D 정보를 추정해 다양한 실험을 진행하는 데 도움이 될 수 있다. 예를 들어 생체역학·스포츠 의학에서는 SAM 3D Body를 활용해 운동 영상에서 선수의 3D 포즈와 관절 움직임을 분석하는 응용이 가능하다12.
한계와 향후 과제
SAM 3D는 3D 데이터 부족 문제와 실세계 장면의 복잡성을 상당 부분 완화했지만, 근본적인 한계가 사라진 것은 아니다. 단일 2D 이미지에서 3D를 복원하는 문제는 본질적으로 정보가 부족한 역문제이기 때문에, 모델은 항상 어느 정도의 "추측"을 할 수밖에 없고, 이는 때때로 실제 물체와 다른 형태를 낳을 수 있다2. 특히 완전히 가려진 뒷면이나 매우 얇고 복잡한 구조는 여전히 어려운 영역이다.
또한 사람이 평가·선호하는 메쉬가 반드시 물리적으로 정확한 메쉬와 일치하는 것은 아니기 때문에, "시각적으로 그럴듯함"과 "정확한 기하학" 사이의 균형 설계도 중요한 과제다2. 데이터 엔진이 사람 선호에 맞게 모델을 정렬시킬수록, 특정한 스타일이나 편향이 강화될 가능성도 있기 때문에, 데이터 다양성과 품질 관리가 계속해서 요구된다12.
마지막으로, 이런 모델의 출력이 실제 설계·제조·의료 등 안전·정밀성이 핵심인 분야에 직접 쓰이려면, 정량적인 신뢰도 평가와 불확실성 추정, 그리고 규제·윤리적 고려가 필요하다. SAM 3D와 같은 모델은 현재로서는 "강력한 시각적 도우미"에 가까우며, 사람이 결과를 검토·보정하는 과정과 함께 사용할 때 가장 효과적일 것으로 보는 시각이 많다24.
참고
1Introducing SAM 3D: Powerful 3D Reconstruction for Physical World Images - https://ai.meta.com/blog/sam-3d/
2SAM 3D: 3Dfy Anything in Images | Research - AI at Meta - https://ai.meta.com/research/publications/sam-3d-3dfy-anything-in-images/
3SAM 3D: 3Dfy Anything in Images - Trending Papers, Hugging Face - https://huggingface.co/papers/2511.16624
4Meta's new image segmentation models can identify objects and people and reconstruct them in 3D - SiliconANGLE - https://siliconangle.com/2025/11/19/metas-new-image-segmentation-models-can-identify-objects-people-reconstruct-3d/
5SAM 3: Segment Anything with Concepts | Research - AI at Meta - https://ai.meta.com/research/publications/sam-3-segment-anything-with-concepts/