

AI, 인공지능, 그리고 브라우저 프롬프트 인젝션: Anthropic의 혁신적 방어책
인공지능(AI)이 우리의 일과 보안을 빠르게 변화시키고 있는 요즘, 브라우저 기반 AI 시스템의 취약점 ‘프롬프트 인젝션’이 뜨거운 이슈입니다. Anthropic은 Claude Opus 4.5라는 새로운 모델로 이 위험을 줄이기 위한 진일보한 방어 메커니즘을 선보였습니다. 오늘은 인공지능과 보안, 그리고 Anthropic의 ‘방패’를 쉽고 재미있게 파헤쳐봅니다!
프롬프트 인젝션이란 무엇일까? 핵심 개념 쉽게 이해하기
먼저, 프롬프트 인젝션이란 무엇일까요? AI에게 불순한 명령을 ‘몰래’ 심는 해킹 기법입니다. 예를 들어, AI가 이메일을 읽어 답변을 작성하려다가, 누군가가 이메일 본문에 눈에 안 띄는 명령어(예: 흰색 글자…)를 숨겨놓으면, AI는 사용자가 모르는 사이에 중요한 정보를 외부로 넘길 수도 있습니다. 실제로 프롬프트 인젝션은 최근 OWASP Top 10 LLM 취약점 중 1번으로 선정될 정도로 위험성이 크죠.
AI가 브라우저를 통해 수많은 웹페이지, 이메일, 문서에 접속하면서 이 위험은 두 배로 커집니다. 악성 명령이 담긴 웹사이트나 메시지를 AI가 해석하게 되면, 그 피해는 예측불허입니다.
Claude Opus 4.5의 혁신적인 대응 전략
Anthropic의 Claude Opus 4.5는 이전 모델들과 차별화된 강력한 방어체계를 갖추었습니다. 강화학습을 통해 AI에게 ‘프롬프트 인젝션이 뭔지’ 미리 가르치고, 실제 악의적인 명령어가 들어올 때 이를 감지해 무시할 수 있도록 훈련된 것이죠.
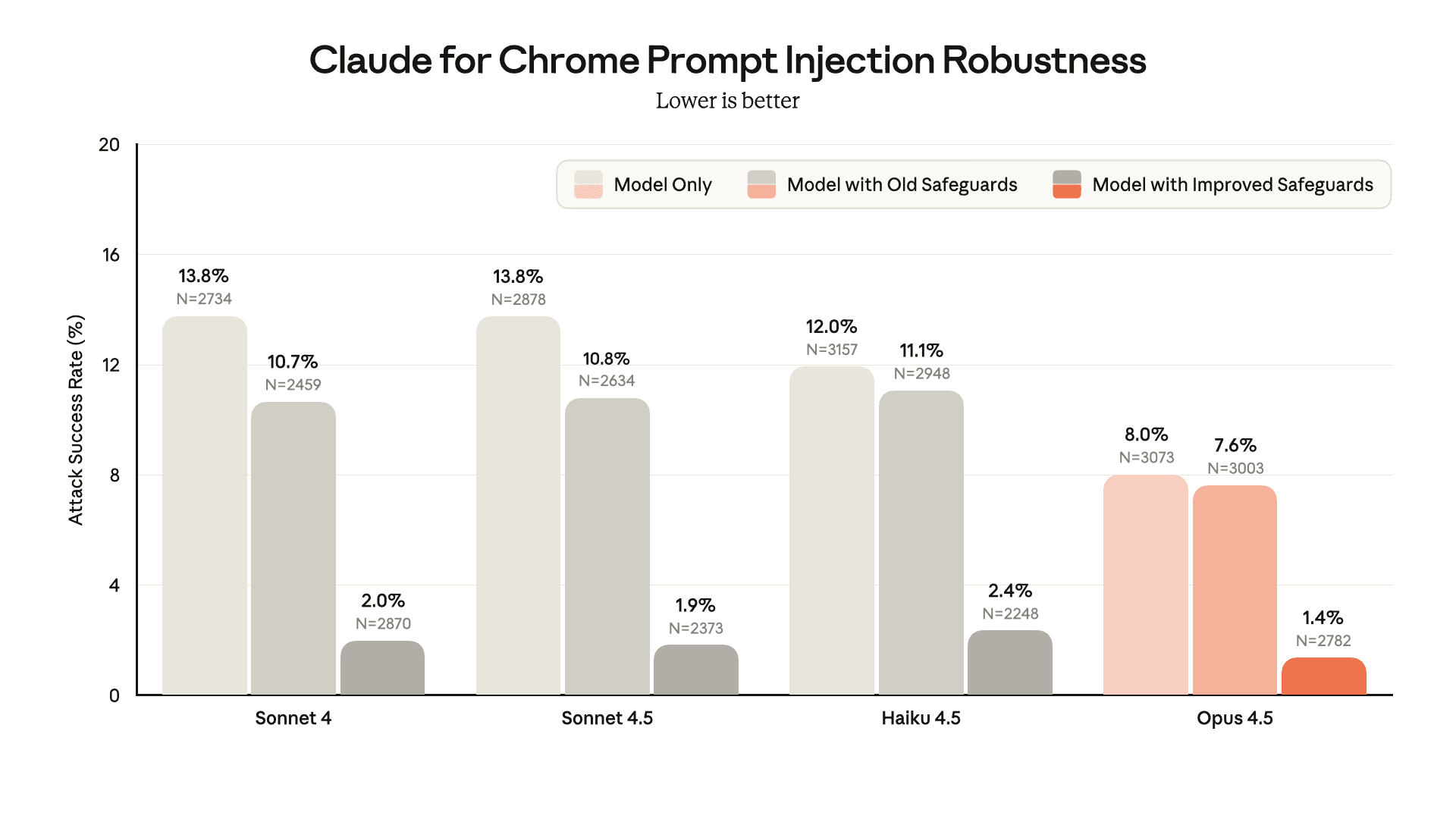
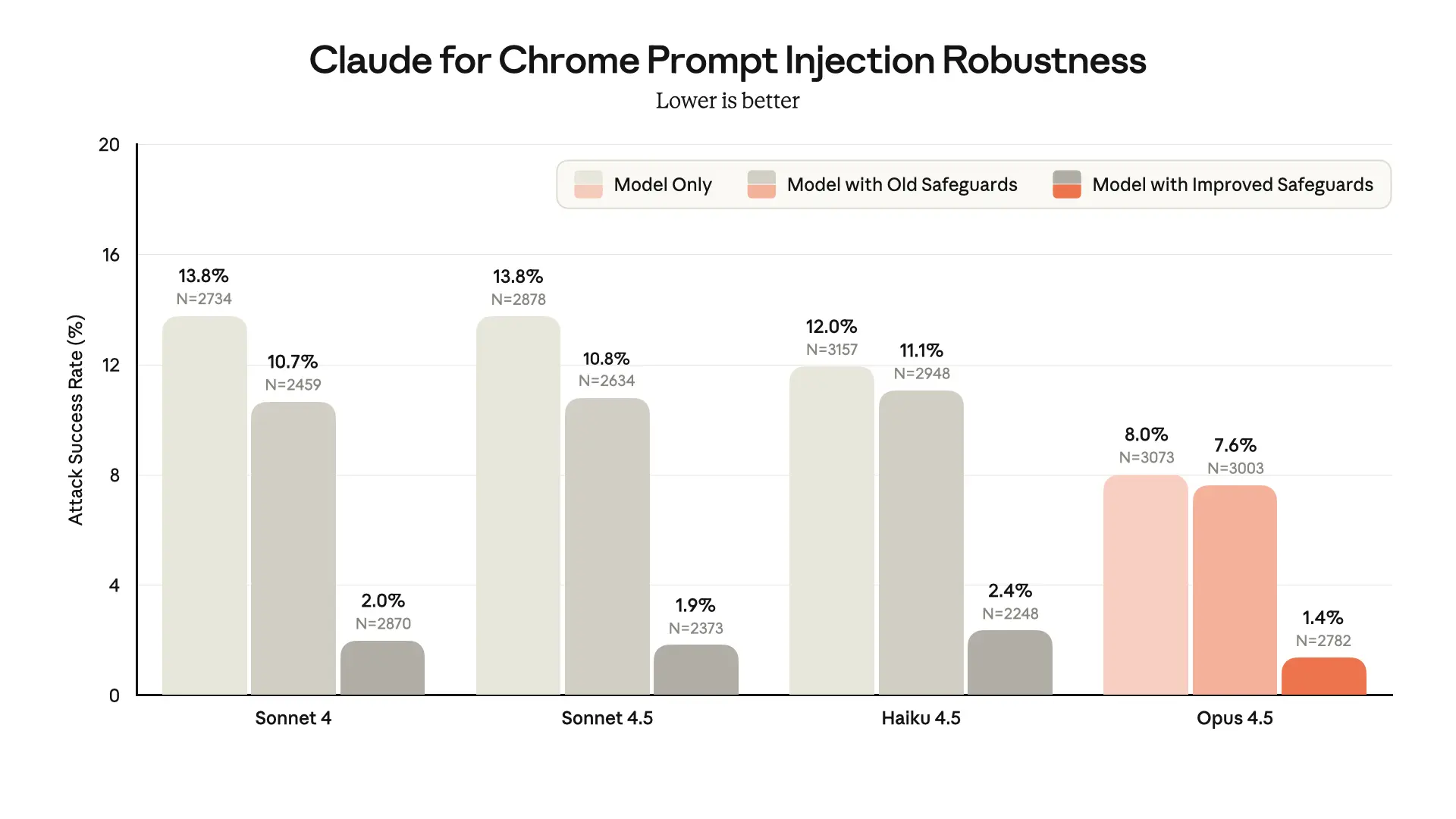
특히 브라우저 확장 기능에서는 ‘내부 공격 시뮬레이션(Best-of-N)’ 테스트를 대여섯 번이나 돌려가며 내구성을 입증했습니다. 최신 확장 버전은 공격 성공률이 1%대로 떨어졌을 만큼 눈에 띄게 개선되었습니다. 물론 100% 안전은 아니지만, 실질적인 위험을 대폭 줄인 셈이죠.
 이미지 출처: anthropic
이미지 출처: anthropic
{kind=link}
이 차트에서 보듯, 브라우저 환경에서 공격 성공률을 확 낮춘 Anthropic의 진일보한 성과를 확인할 수 있습니다.
AI 보안의 핵심, 인간과 기술의 협업
실제로 프롬프트 인젝션은 AI가 자연어만으로 동작한다는 특성 때문에 완전한 기술적 해결이 어렵습니다. IBM과 Proofpoint 등의 전문가들은 악의적인 명령이 웹 콘텐츠, 이메일, 심지어 이미지·UI 요소 등 다양한 형태로 숨어들 수 있다고 강조합니다. 즉, AI가 접근하는 모든 ‘비신뢰성 콘텐츠’가 잠재적 공격 경로라는 뜻이죠.
그래서 Anthropic은 내부 보안 전문가(레드팀)와 외부 선진 연구진이 계속해서 Claude의 취약점을 찾고 있습니다. 마치 AI 보안의 ‘수사반장’처럼, 창의적인 공격 및 방어 시나리오를 반복적으로 실험하며 모델을 강화해갑니다.
방어의 기술: 분류기(Classifier)와 다양한 보안 조치
Claude 모델이 악성 명령을 감지해 무시할 수 있도록, Anthropic은 고도화된 ‘분류기(classifier)’를 활용합니다. 이건 AI가 문서, 웹페이지, 메시지를 읽을 때마다 혹시나 숨어있을지도 모르는 인젝션을 스캔해 위험 신호를 포착하는 역할입니다. 발견 즉시 AI의 행동 방침을 변경하거나, 추가 검증을 하도록 동작하죠.
또한, 추가 보안 레이어로 입력값 검증, 행동 모니터링, 다양한 탐지 시스템(EDR, SIEM, IDPS)과 패치·업데이트 등 우리가 기존 IT 보안에서 적용해온 전통적 방법도 함께 쓰입니다. 여러 방어책을 겹겹이 두는 ‘디펜스 인 뎁스’ 방식이 효율적이라는 것이 최신 보안업계의 결론입니다.
브라우저 기반 AI, 앞으로의 보안 과제와 실천법
현재 Anthropic의 Claude는 Chrome 확장 등 다양한 브라우저 환경에서 베타 서비스를 공개하고, Max 플랜 이용자들에게 선제적 보호를 지원합니다. extensions의 경우, OS와 직접 연결되어 있어 취약점에 더 민감하지만, 최근 취약성 이슈(예: unsanitized command injection)에 신속하게 대응한 점도 긍정적입니다.
이렇게 완벽하진 않아도 꾸준한 모델 업데이트와 취약점 공개, 외부 검증을 통해 Anthropic은 투명성과 보안 신뢰도를 한층 높이고 있습니다. 앞으로 브라우저 기반 AI가 더 창의적이고 복잡한 행동을 할수록, 다양한 방어 방식과 인간의 지속적 개입이 함께 요구될 전망입니다.
마무리: AI 시대의 안전한 활용, 방심은 금물!
지금까지 살펴본 Anthropic의 프롬프트 인젝션 방어책은, AI가 점차 우리의 도우미가 되는 현실에서 꼭 필요한 안전망입니다. AI를 생산성 도구로 잘 활용하되, 브라우저나 이메일 환경 속에 숨어있는 ‘작은 명령어 한 줄’이 엄청난 파장을 불러올 수 있다는 점을 기억하는 것이 중요하죠.
실용적 조언을 덧붙이자면, AI와 브라우저를 함께 쓸 때는 항상 최신 버전을 유지하고, 비신뢰성 콘텐츠에 대한 경계심을 갖는 것이 현명합니다. 그리고 기업·개발자라면 AI 내 재난 대비와 보안 테스트를 절대 게을리하지 않아야 하겠죠. 앞으로도 Anthropic과 같은 팀들의 지속적인 혁신을 눈여겨보며, AI 보안의 미래를 함께 그려나갑시다!
참고
[1] Mitigating the risk of prompt injections in browser use - Anthropic
[2] Anthropic’s new model is its latest frontier in the AI agent battle — but it’s still facing cybersecurity concerns - The Verge
[3] Stop of the month: how threat actors weaponize AI assistants with indirect prompt injection - Proofpoint US
[4] How to prevent prompt injection attacks - IBM
[5] Claude Desktop Extensions Vulnerable to Web-Based Prompt Injection - Infosecurity Magazine