

AI와 인공지능이 만난 비전 혁명: Meta의 SAM 3와 언어-비전의 새로운 경계
AI의 눈과 귀가 어느 때보다 똑똑해졌다! 이미지를 한 번에 이해하고, 명령대로 쏙쏙 찾아내며, 2D 사진 한 장에서 3D 세상을 만들어내는 마법까지. 이 모든 일의 중심에 Meta의 'Segment Anything Model 3(SAM 3)'와 SAM 3D가 있습니다. 이번 글에서는 언어와 비전의 경계를 허문 SAM 3의 최신 기술과 활용법, 그리고 현실을 3D로 재창조하는 미래까지 한눈에 살펴봅니다.
SAM 3: 이미지를 언어로 쪼개는 AI 시대
“노란색 학교버스를 찾아줘”, “빨간 야구 모자를 쓰고 있지 않은 사람은?” 이제 AI에게 이렇게 말하면, SAM 3는 텍스트 프롬프트를 이해해 원하는 대상을 이미지를 분석해 정확히 찾아냅니다. 기존 AI는 ‘자동차’처럼 범주가 정해진 물체만 알아봤지만, SAM 3는 열린 어휘(Open Vocabulary)로 세밀하고 복잡한 개념까지 인식합니다.
SAM 3는 텍스트는 물론, 예시 이미지나 직접 클릭(시각적 프롬프트)을 조합해 원하는 대상을 지정할 수 있습니다. 예를 들어, 하나의 창고 사진을 띄워놓고 “박스”라고 입력하면 수십 개의 박스 위치를 순식간에 분리해줍니다. 영상 영역까지 확대되어, “움직이는 자동차”와 같은 개념도 실시간에 가까운 속도로 추적할 수 있습니다.
SAM 3의 이 ‘프롬프트 가능 개념 세분화(PCS, Promptable Concept Segmentation)’ 방식 덕에 이미지 내부의 세부 영역 탐색과 추적이 한층 쉽고 정교해졌습니다. 특히 복잡한 영상 편집, 자동 라벨링, AR 쇼핑, 창작 도구 등 다양한 분야에서 혁신적인 효과를 기대할 수 있죠.
SAM 3의 훈련: 인간과 AI가 만나 만든 거대 데이터셋
일반적으로 AI 모델을 훈련시키려면 방대한 이미지와 그 안의 객체 정보를 사람이 일일이 나누어 표시(주석)해야 했습니다. SAM 3에서는 이 훈련 작업이 인간과 AI가 번갈아가며, 협업하는 '하이브리드 데이터 엔진' 방식으로 이루어집니다. AI가 먼저 분할 후보를 제안하면, 인간과 또 다른 AI가 이를 검증·수정하여 빠르게 정답에 가까운 마스크를 만들죠.
이 덕분에 약 400만 개가 넘는 다양한 개념(객체, 상태 등)이 포함된 초대형 데이터셋이 만들어졌고, 기존 모델 대비 두 배 이상의 성능 향상을 달성했습니다. SAM 3의 이 방식은 학습효율성은 물론 데이터 다양성 측면에서도 획기적인 진전이라 할 수 있습니다.
영상과 실제 서비스에서의 활용: 메타 생태계에 스며드는 AI
SAM 3는 그저 실험용 기술이 아닙니다. 이미 Facebook Marketplace의 'View in Room' 기능에서는 가구나 소품을 집 안에 가상으로 배치할 수 있게 하며, Instagram의 Edits 앱에서도 특정 인물이나 객체에만 효과를 지정할 수 있는 고급 영상편집 기능이 곧 도입될 예정입니다.
엔터테인먼트, 전자상거래, 콘텐츠 서비스 등 사람이 직접 선택하지 않아도 AI가 사용자 요청에 따라 원하는 부분만 골라내어 편집하거나 비교 대상으로 선정하는 일이 이제 일상이 되고 있습니다.
실시간 처리와 한계: AI의 약점과 미래 방향
SAM 3는 단일 이미지에서 100개가 넘는 객체를 단 30밀리초 만에 분할할 수 있을 만큼 빠릅니다. 하지만 기술적 한계도 분명 존재합니다. 의료 영상 등 아주 전문화된 용어나 논리적 설명("맨 윗칸 오른쪽에서 두 번째 책 같은…")이 필요할 때는 잘 작동하지 않습니다. 이에 Meta는 언어·비전 이중모달 모델(Gemini, Llama 등)과 SAM 3를 결합한 ‘SAM 3 Agent’로 이런 고난도 작업까지 대응하도록 하고 있습니다.
SAM 3D: 2D 이미지를 3D 세계로 변환하는 차세대 생성 AI
이제 평면 이미지만 보고도 3D 오브젝트와 공간까지 복원할 수 있는 시대! SAM 3D는 텍스트나 이미지 프롬프트와 연동해 단 한 장의 사진에서 현실감 넘치는 3D 모델을 생성합니다. 가구, 건물, 인체 등 다양한 대상을 실제와 비슷하게 재창조하며, 복잡한 공간 구성과 텍스처까지 충실하게 반영합니다.
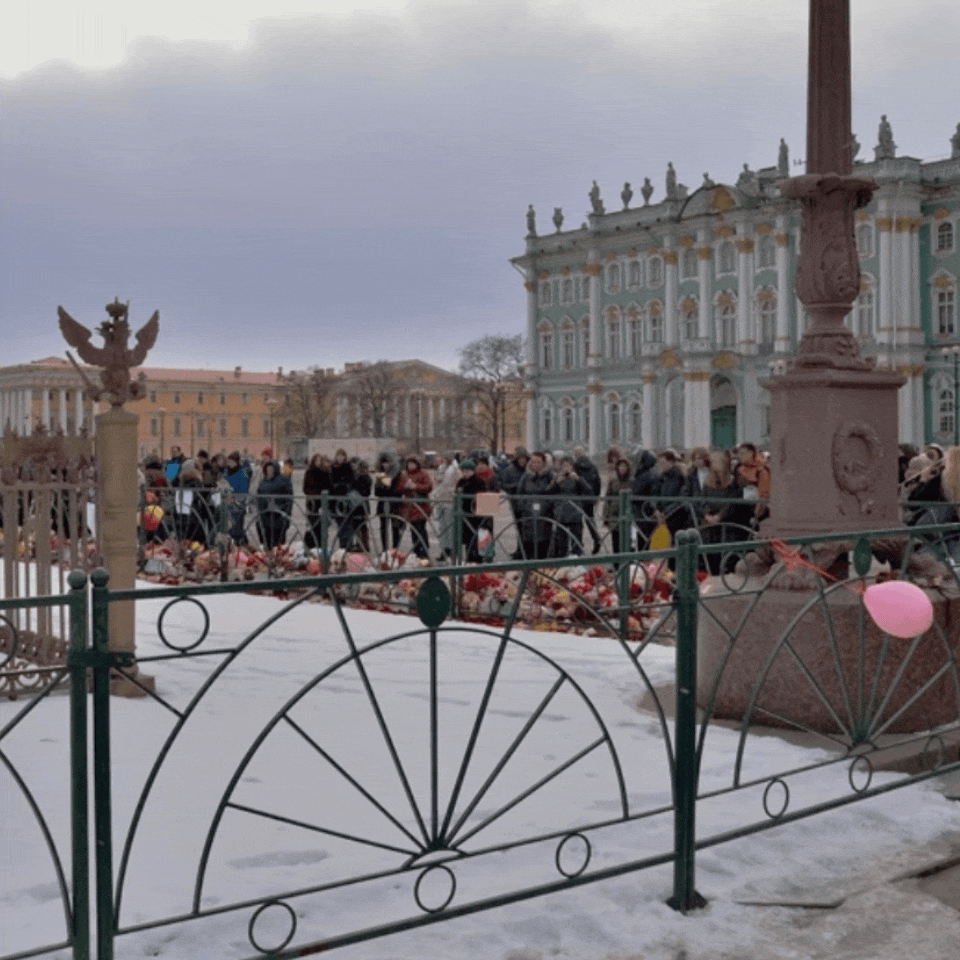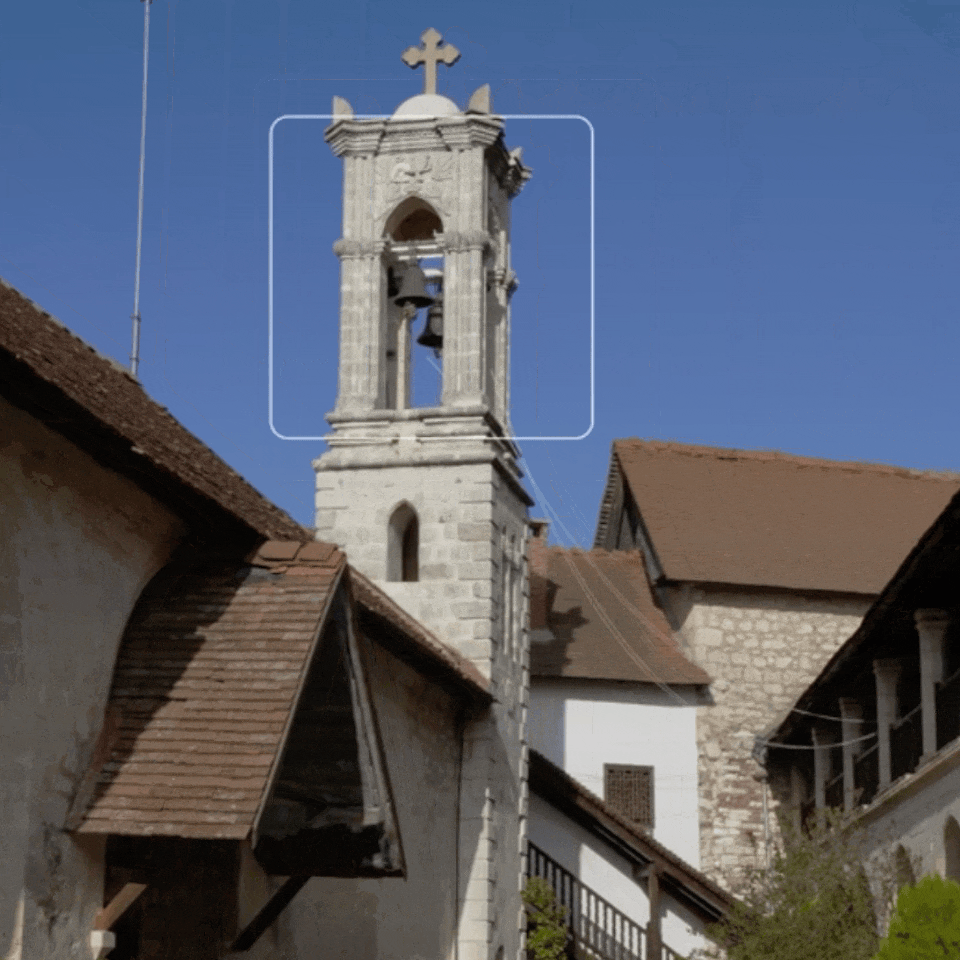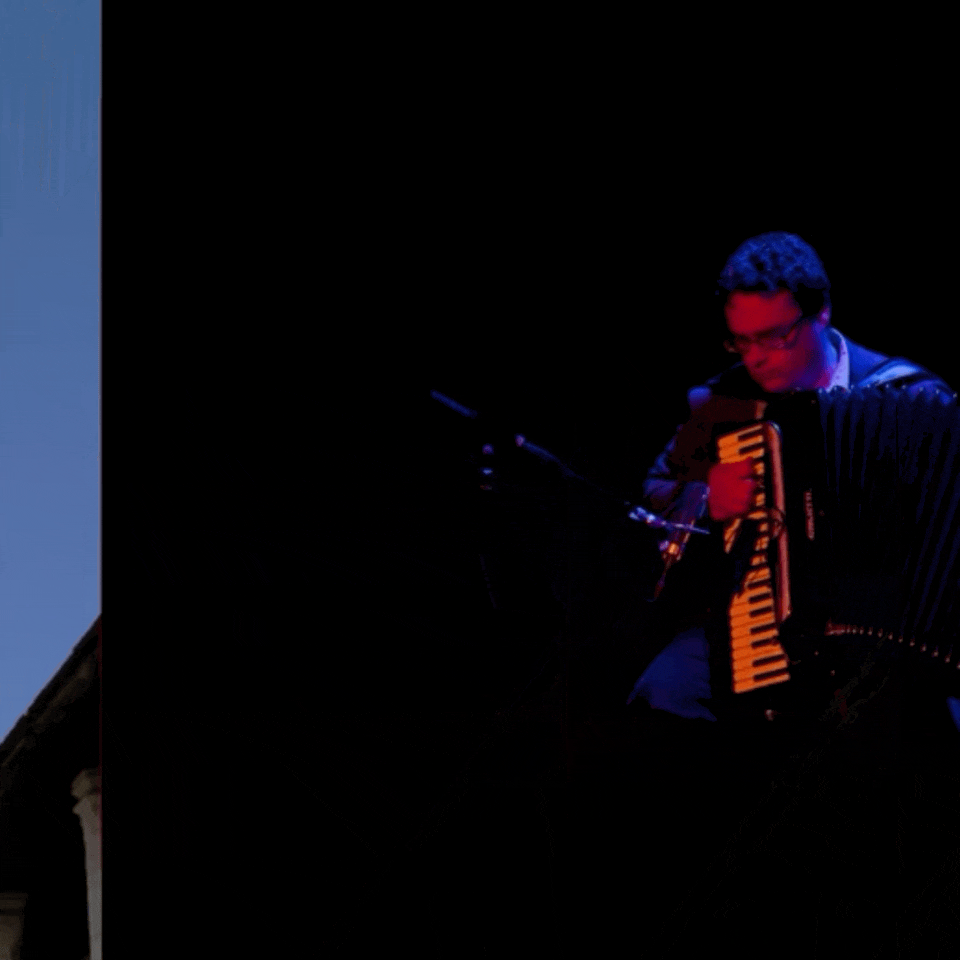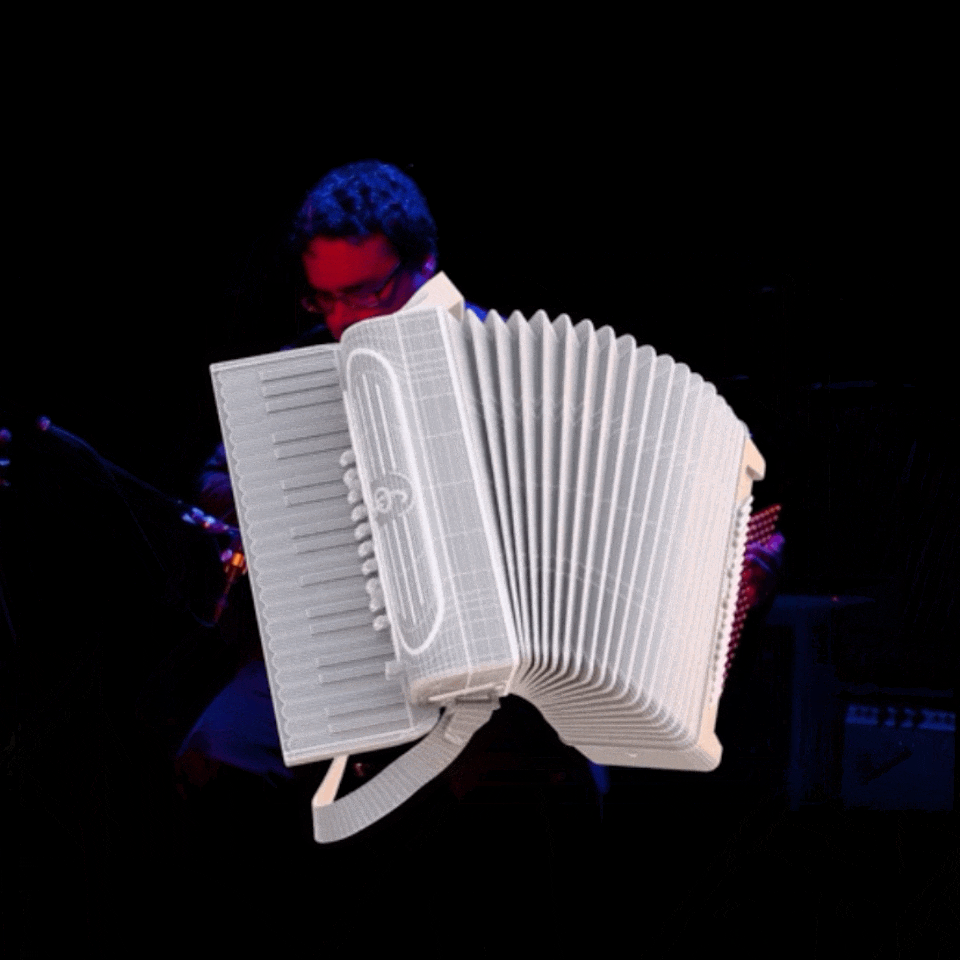 이미지 출처: fb
이미지 출처: fb
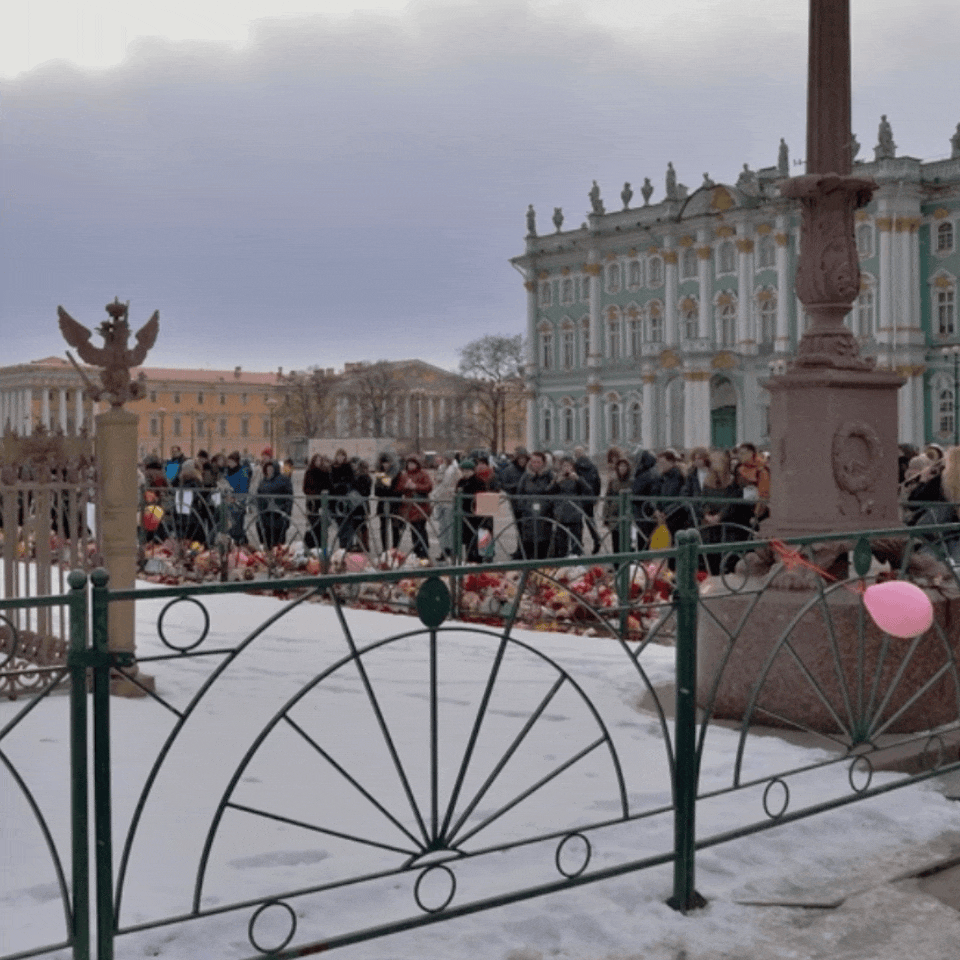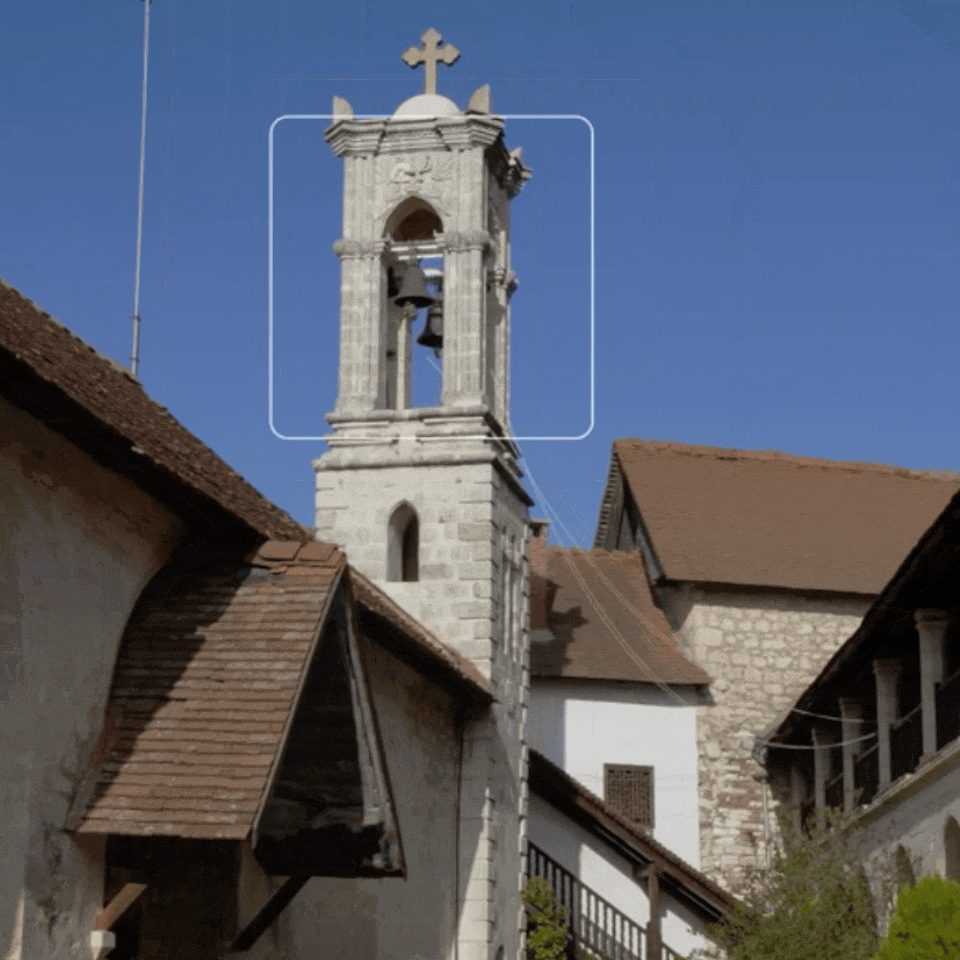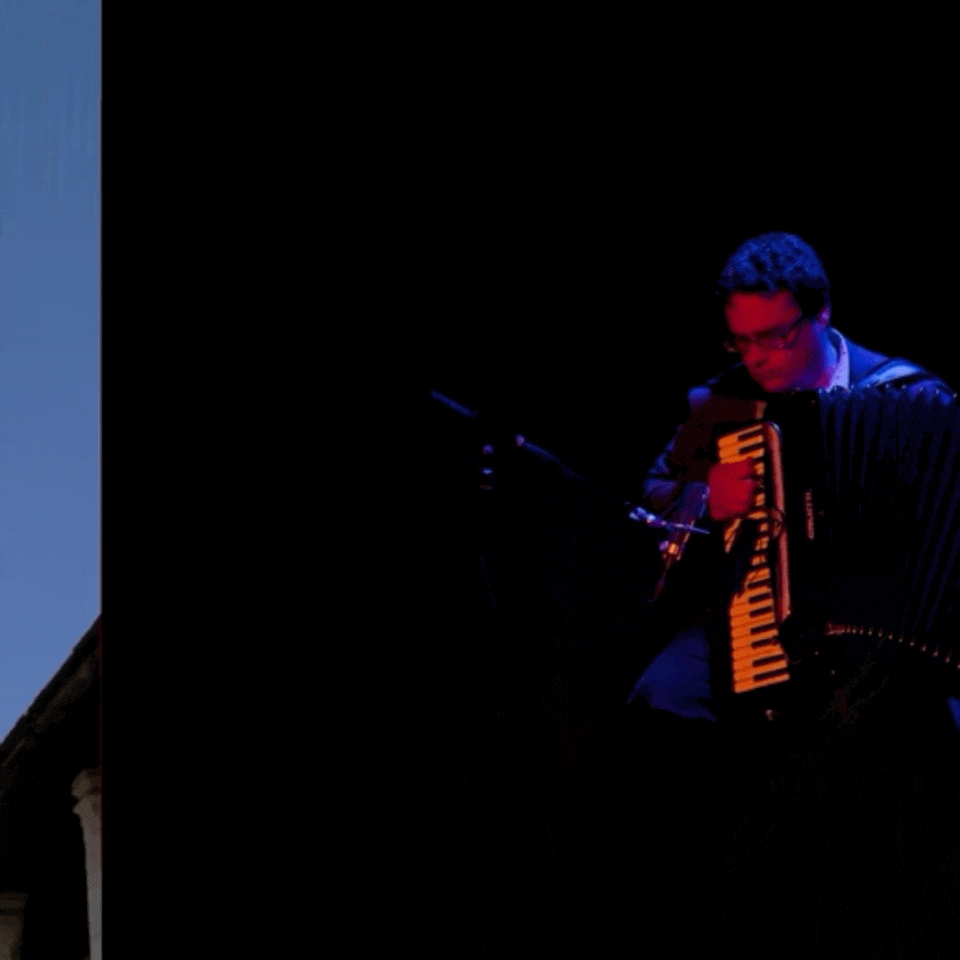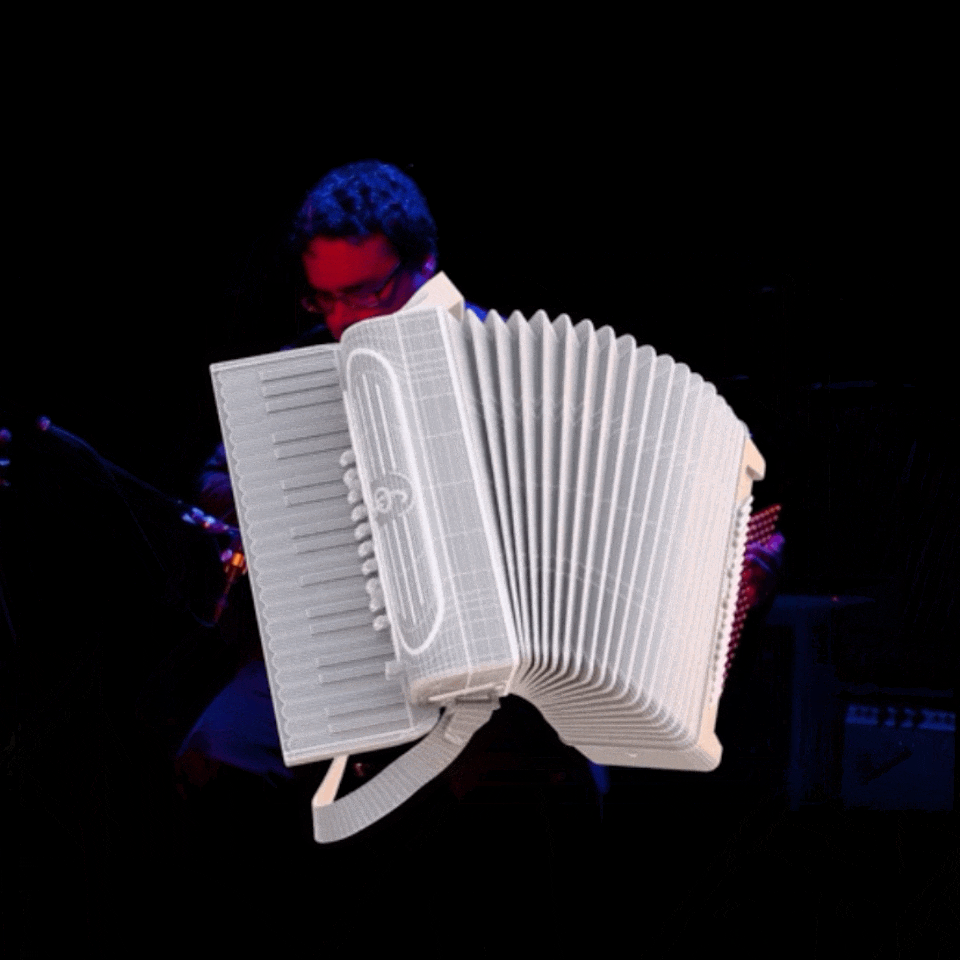{kind=link}
예를 들어 “책상 위 램프”라고 입력하면, SAM 3가 램프를 정확히 분할해서 SAM 3D에게 전달, 곧바로 3D 공간상에 배치가 가능합니다. E-commerce(전자상거래)에서 “내 방에 미리 배치해보기”처럼 쓸 수 있고, 창작이나 로봇 비전, 과학 시각화 등 다양한 분야에 폭넓게 활용됩니다.
SAM 3D의 실제 적용과 주의점
SAM 3D의 강점은 한 번의 촬영만으로 복잡한 3D 데이터를 만들 수 있다는 점입니다. 전통적인 수십 장의 사진이나 3D 센서가 필요했던 방식과 비교하면, 시간과 비용에서 큰 절약을 이룰 수 있죠. 다만, 저화질 사진이나 복잡한 장면, 매우 희귀한 객체, 인체의 정밀한 손동작과 같은 영역에서는 아직 한계가 분명합니다. 미래에는 해상도 개선과 다양한 오브젝트, 동적 사람 표현에 더욱 강력해질 것으로 보입니다.
 이미지 출처: fb
이미지 출처: fb
{kind=link}
실용적 조언: 누구나 경험할 수 있는 AI 도구의 새로운 활용법
SAM 3와 SAM 3D는 전문 연구뿐 아니라, 누구나 직접 써보고 체험할 수 있도록 공식 온라인 플레이그라운드가 제공됩니다. 텍스트로 명령하고, 예시 이미지를 띄워 직접 원하는 물체를 추적·분리 또는 3D로 만들어보는 체험이 가능합니다. 콘텐츠 제작자, 소상공인, 연구자, 개발자 모두 AI의 힘을 쉽고 빠르게 활용할 수 있는 시대가 다가오는 것입니다.
정리
Meta의 SAM 3와 SAM 3D는 단순한 이미지 분류를 넘어서 언어와 영상의 벽을 허물고, 한 장의 사진에서 입체 세계를 가까이에 가져다주는 시대를 열었습니다. 앞으로 이 기술들이 콘텐츠 제작, 쇼핑, AR/VR, 로봇 비전 등 다양한 분야를 어떻게 변화시킬지 기대해봐도 좋겠습니다. AI와 함께하는 비주의 혁신, 지금 경험해보세요!
참고
[1] Meta's SAM 3 segmentation model blurs the boundary between language and vision - THE DECODER
[2] New Segment Anything Models Make it Easier to Detect Objects and Create 3D Reconstructions - Meta
[3] What is Segment Anything 3 (SAM 3)? Segment Anything with Concepts - Roboflow
[4] sam3d | 3D World Image - sam3d.world
[5] SAM 3D Objects Tutorial: Meta AI Single-Image 3D Reconstruction | Photo to 3D Model - Tech Explorer