

인공지능 음성 인식의 최신 트렌드: Open ASR Leaderboard와 다국어·장문 전사 혁명
인공지능(AI) 음성 인식 기술이 나날이 똑똑해지고 있습니다. 영어 뿐만 아니라 다양한 언어, 긴 오디오 파일까지 척척 처리하는 최신 모델들의 경합장, Open ASR Leaderboard에 대해 알아봅니다. 이 글에서는 인공지능 음성 인식(ASR)이 어떻게 발전해왔는지, 트랙별 최신 트렌드와 실제 활용 팁까지 모두 쉽게 정리해 드립니다.
ASR 모델의 구조와 진화: Conformer + LLM의 승리
음성 인식 모델의 핵심은 바로 ‘듣고, 이해하고, 쓰는’ 능력입니다. 최근 최고 성능을 자랑하는 ASR 모델은 보통 Conformer 인코더(음성 파형에서 의미를 뽑아내는 똑똑한 귀)와 대형 언어 모델(LLM) 디코더(문맥을 이해하여 자연스러운 문장 뽑는 뇌)를 결합한 구조로 설계됩니다.
이 방식은 복잡한 발음이나 문맥 흐름도 정확하게 잡아낼 수 있어, 영어 기준 Word Error Rate(WER)가 눈에 띄게 낮습니다. 예를 들어, NVIDIA의 Canary-Qwen-2.5B, IBM의 Granite-Speech-3.3-8B, Microsoft의 Phi-4-Multimodal-Instruct 등은 최신 Leaderboard에서 최상위권을 차지하고 있습니다.
관련 개념이 궁금하다면?
인코더-디코더 모델은 한쪽에서 정보를 요약해 벡터로 만들고, 다른 쪽에서 그 정보를 바탕으로 출력(예를 들어, 텍스트)을 생성하는 구조입니다. 특히 영어에서 문장 구조가 자유롭기 때문에, 이런 모델이 섬세한 문맥 파악에 강점을 갖죠.
(자세히 보기)
속도 대 정확성: 실제 업무에 꼭 맞는 모델 선택법
하지만 아무리 정확해도 너무 느리면 실전에서는 곤란하겠죠? 최신 LLM 디코더를 쓴 모델이 정확도 1등인 반면, 처리 속도에서는 CTC(Time Delay Neural Network)나 TDT(Timed Data Transformer) 디코더가 압도적으로 빠릅니다. 실시간 회의 전사, 팟캐스트 대량 처리 등 시간 제약이 큰 작업에는 이쪽이 훨씬 효율적입니다.
'실제 시간 요소(RTFx)'란, 오디오 1초 처리에 모델이 얼마나 빨리 결과를 내는지 보여주는 지표인데, CTC 기반 모델은 LLM 기반보다 10~100배 더 빠릅니다. 물론 약간의 오류율 증가가 있을 수 있으니, 목적에 따라 최적의 균형점을 찾는 게 중요합니다.
다국어 ASR: 한계와 도약, 그리고 로컬 언어의 미래
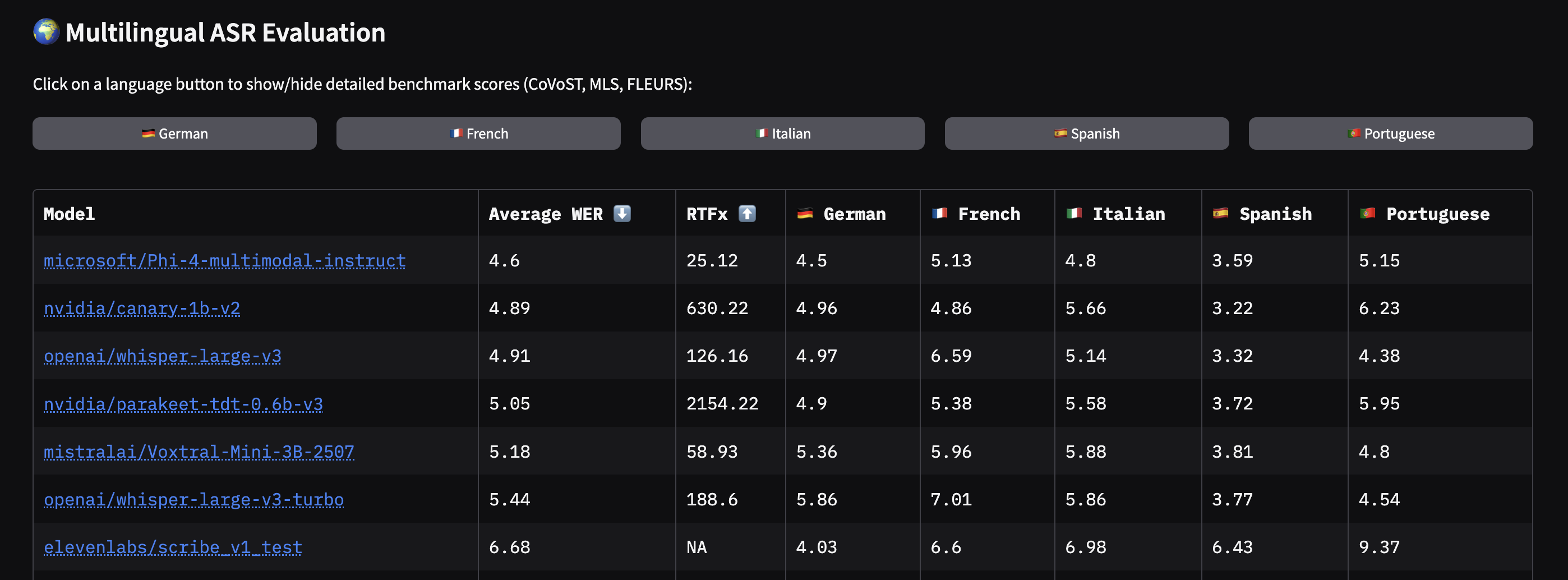
음성 인식 시장은 이제 영어뿐 아니라 수십~수백 개의 언어를 동시에 지원하는 모델이 부상 중입니다. OpenAI의 Whisper Large v3는 99개 언어를 지원해 업계의 '다국어 표준'처럼 여겨집니다. 실제로 FFmpeg 8.0부터 Whisper가 기본 통합되어, 누구나 손쉽게 다국어 오디오를 실시간으로 전사할 수 있게 되었어요.
 이미지 출처: huggingface
이미지 출처: huggingface
{kind=link}
Whisper Large v3과 같은 대형 모델은 폭넓은 언어 커버리지를 제공하지만, 특정 언어(예: 영어)로만 특화해 미세 조정(fine-tuning)한 Distil-Whisper, CrisperWhisper 등의 변형 모델이 훨씬 더 정교한 결과를 낼 수 있습니다. 여러 언어를 한 번에 잘하려면 약간 보편적 성능이 희생되는 것이 현실입니다.
재미있는 점은, 인도처럼 언어와 방언이 수십 개에 달하는 환경에서는 공통 음소 체계(Common Label Set)를 도입하는 등, 언어적 특징을 적극 활용해 ASR 정확도를 높이고 있다는 점입니다. 국·내외 각 언어별 Leaderboard의 발전은 앞으로 로컬 언어의 AI 음성 처리 수준을 크게 높일 전망입니다.
장시간 오디오 전사: 오픈소스와 상용의 접전 구도
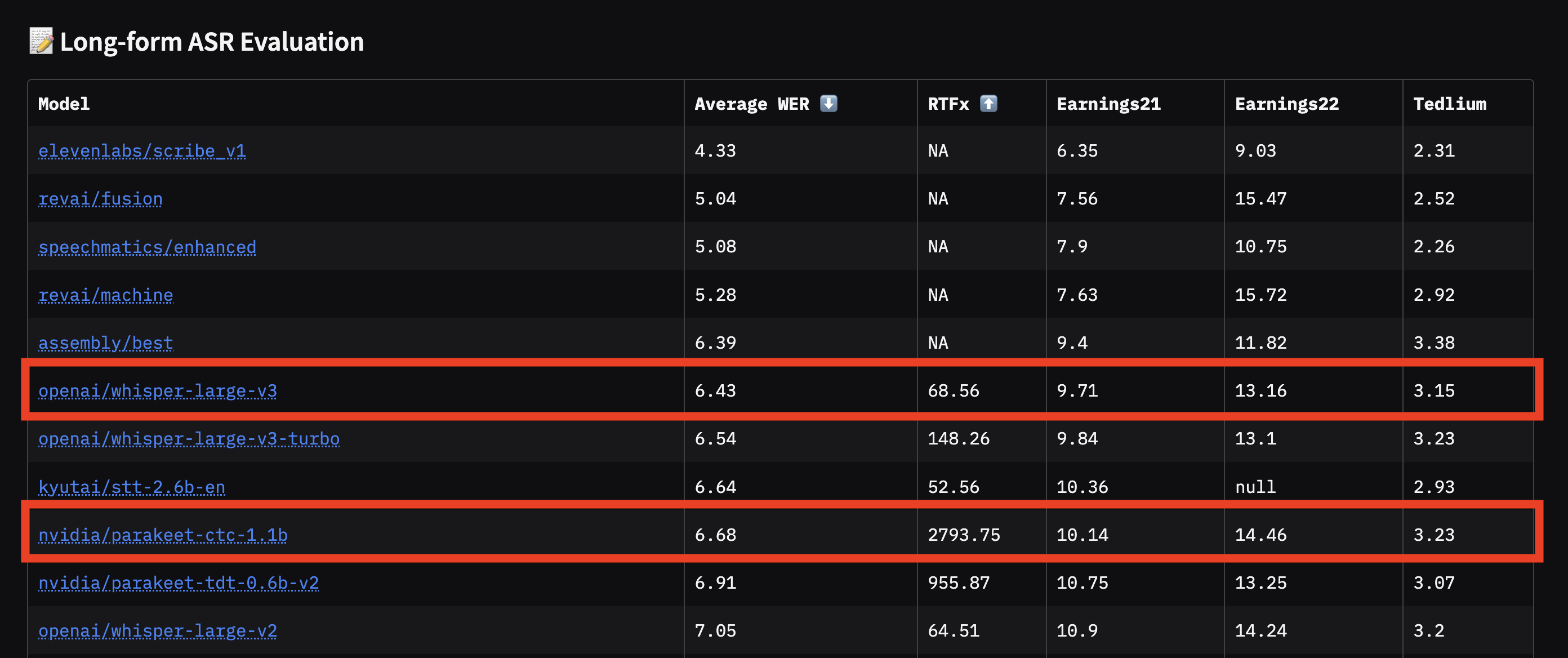
긴 오디오 파일(예: 2시간짜리 회의, 1시간짜리 팟캐스트)은 처리 시간이 길고, 다양한 화자와 잡음, 문맥 단절 등 난이도가 높습니다. 지금까지는 커스터마이즈가 자유로운 비공개 상용 모델이 성능에서 앞서 있지만, 오픈소스 진영도 빠르게 따라잡고 있습니다.
실제 OpenAI의 Whisper Large v3는 장시간 오디오에서도 안정적인 결과를 내며, NVIDIA의 Parakeet CTC 모델처럼 속도를 극대화하고도 오류율을 경쟁적으로 유지하는 모델이 등장했습니다. 팟캐스트, 강의, 회의 등 대량·장시간 오디오 자동화가 필요한 기업이나 연구자에겐 이러한 모델들의 발전이 큰 도움이 됩니다.
 이미지 출처: huggingface
이미지 출처: huggingface
{kind=link}
음성 인식의 활용 팁: 자동 화자 인식과 실전 응용
최근에는 한 오디오 파일에 여러 사람이 이야기하는 경우 '누가 무엇을 말했는지'(Speaker Diarization)까지 자동으로 분리해주는 기술이 대세입니다. Whisper Large v3 같은 모델과 Pyannote 같은 AI 기술을 결합해, 회의·인터뷰·방송 등에서 "화자 1: 안녕하세요, 오늘 회의 시작합니다.", "화자 2: 이번 분기 실적을 보고드리겠습니다."처럼 자동으로 화자별로 정리된 문서를 즉시 받을 수 있게 되었습니다.
비즈니스 미팅, 연구 인터뷰, 팟캐스트 등 말이 오가는 모든 현장에서 매우 유용하며, 기록·요약·분석까지 모두 손쉽게 자동화할 수 있습니다.
커뮤니티 리더보드와 오픈소스 혁신의 미래
Open ASR Leaderboard는 이제 단순한 랭킹 표가 아니라, 모델 개발자와 사용자 모두가 참여하는 커뮤니티형 벤치마크로 자리잡고 있습니다. 더 많은 언어, 데이터셋, 모델이 지속적으로 등록되고 있으며, GitHub 등에서 자신만의 모델·데이터셋·튜닝 결과를 바로바로 공유하고 비교할 수 있습니다.
‘공개 모델과 데이터셋이 부족한 언어에는 로컬 Leaderboard와 커뮤니티의 활발한 정보 교류가 대세’라는 점은 앞으로 글로벌 AI 음성 인식 발전 속도를 더욱 높여줄 것입니다.
정리: ASR 트렌드를 읽고, 내게 딱 맞는 솔루션 선택하기
요약하면,
‘Conformer + LLM’ 조합은 오늘날 음성 인식 정확도의 왕좌를 차지하고 있습니다.
실시간 처리·속도가 중요하다면 CTC/TDT 기반 모델을 활용하세요.
다국어 전사, 다중 화자 분리 등 활용폭이 넓어졌으며, Whisper Large v3가 표준으로 자리매김 중입니다.
팟캐스트 등 장시간 오디오 전사에는 최신 오픈소스·상용 모델이 꾸준히 발전하고 있습니다.
오픈 커뮤니티와 리더보드는 시장, 학계, 개발생태계 모두에 혁신을 불러오고 있습니다.
내가 실제로 사용할 ASR 모델을 고를 때는,
어느 언어/방언이 필요한지
처리 속도 vs. 정확성 어느 쪽이 더 중요한지
화자 분리 등 추가 기능이 필요한지
예산과 기술 지원 환경은 어떻게 되는지
꼼꼼히 따져보고 작업에 맞는 모델을 고르는 것이 가장 현명합니다.
AI 음성 인식은 지금도 빠르게 진화 중입니다. 응용 범위와 정확도, 효율성에서 고르는 재미도 쏠쏠하니, 자신의 업무나 콘텐츠에 맞는 최적의 솔루션을 직접 찾고 실전에서 적극 활용해 보세요!
참고
[1] Open ASR Leaderboard: Trends and Insights with New Multilingual & Long-Form Tracks - Hugging Face
[2] What is an encoder-decoder model? - IBM
[3] What is ASR and How Does It Actually Work? - MeowTXT Blog
[4] Building Robust and Scalable Multilingual ASR for Indian Languages - arXiv
[5] BrassTranscripts Launches WhisperX Large-v3 with Automatic Speaker Identification - BrassTranscripts Blog
[6] Using Whisper for Native Video Transcription in FFmpeg 8.0 - Rendi.dev
[7] Train Short, Infer Long: Speech-LLM Enables Zero-Shot Streamable Joint ASR and Diarization on Long Audio - arXiv
[8] Speech recognition - Wikipedia