
AI 시대, 가장 신뢰할 수 있는 문서 파싱 API는 무엇일까? – 성능/가격 비교와 실전 분석
문서 파싱(Document Parsing)은 AI 시대 데이터 분석과 업무 자동화의 핵심입니다. 이제 단순히 PDF나 스캔 이미지를 텍스트로 변환하는 데 그치지 않고, 테이블·레이아웃·키-값 정보까지 똑똑하게 구조화해서 실제 비즈니스 시스템이 바로 활용할 수 있는 형태로 바꾸는 게 당연해졌죠. 하지만 수많은 API와 플랫폼 중 어떤 문서 파싱 솔루션이 ‘정말’ 신뢰할 수 있을까요? 성능, 가격, 실제 현장에서의 안정성까지 냉정하게 비교한 최신 벤치마크 결과와 핵심 원리를 재미있게 풀어봅니다.
 이미지 출처: tensorlake
이미지 출처: tensorlake
{kind=link}
문서 파싱, AI의 첫 관문: 단순 텍스트 추출이 아니다!
몇 년 전만 해도 문서 파싱은 변환 품질보다 "텍스트가 잘 뜨는가?"가 중요했습니다. 하지만 2025년 현재, AI와 연계되는 문서 파싱은 완전히 다른 차원을 요구합니다. PDF나 스캔 이미지에 섞인 테이블, 여러 단락, 주소·전화번호·이메일 같은 중요 필드, 심지어 복잡한 레이아웃이나 수식·각주·서명까지—이 모든 정보를 논리적 순서와 구조로 살려야 진짜 ‘기계가 읽을 수 있는’ 데이터가 탄생합니다.
이런 구조화가 중요한 이유는, 결국 RAG(retrieval augmented generation) 파이프라인, 보험청구 자동화, 재무 데이터 분석, 고객정보 추출 등 핵심 AI 업무가 ‘구조적 데이터’ 없이는 시작도 못하기 때문입니다.
무엇이 문서 파싱의 품질을 결정하는가? – 구조 보존, 실제 사용성까지!
전통적인 문서 파싱 평가법은 ‘텍스트 유사도’에만 초점을 뒀습니다. 즉, OCR 결과가 정답에 얼추 비슷하면 만점. 하지만 실제 업무 시스템에서 가장 중요한 건 "구조가 똑바로 살아 있느냐?", "추출된 필드를 자동화가 문제없이 쓸 수 있느냐?"입니다.
Tensorlake 등 최신 AI 파싱 모델의 평가는 이러한 현실적 기준을 철저히 반영합니다.
TEDS(Tree Edit Distance Similarity): 실문서의 HTML/Markdown 트리와 결과물을 비교해, 내용뿐 아니라 테이블·머지셀·읽는 순서·레이아웃까지 상세하게 보존됐는지를 측정합니다.
JSON F1(정밀도+재현율): 추출된 JSON 데이터를 기준으로, 핵심 필드가 정확히 파악됐는지(정밀도), 빠짐없이 잡았는지(재현율)를 균형있게 평가합니다. 실제 다운스트림 자동화 시스템이 ‘잘 쓸 수 있는 데이터’가 만들어졌는지 판가름하는 지표죠.
이 두 지표를 동시에 만족시키는 모델만이 실제 AI 파이프라인에서 높은 신뢰성과 효율을 구현합니다.
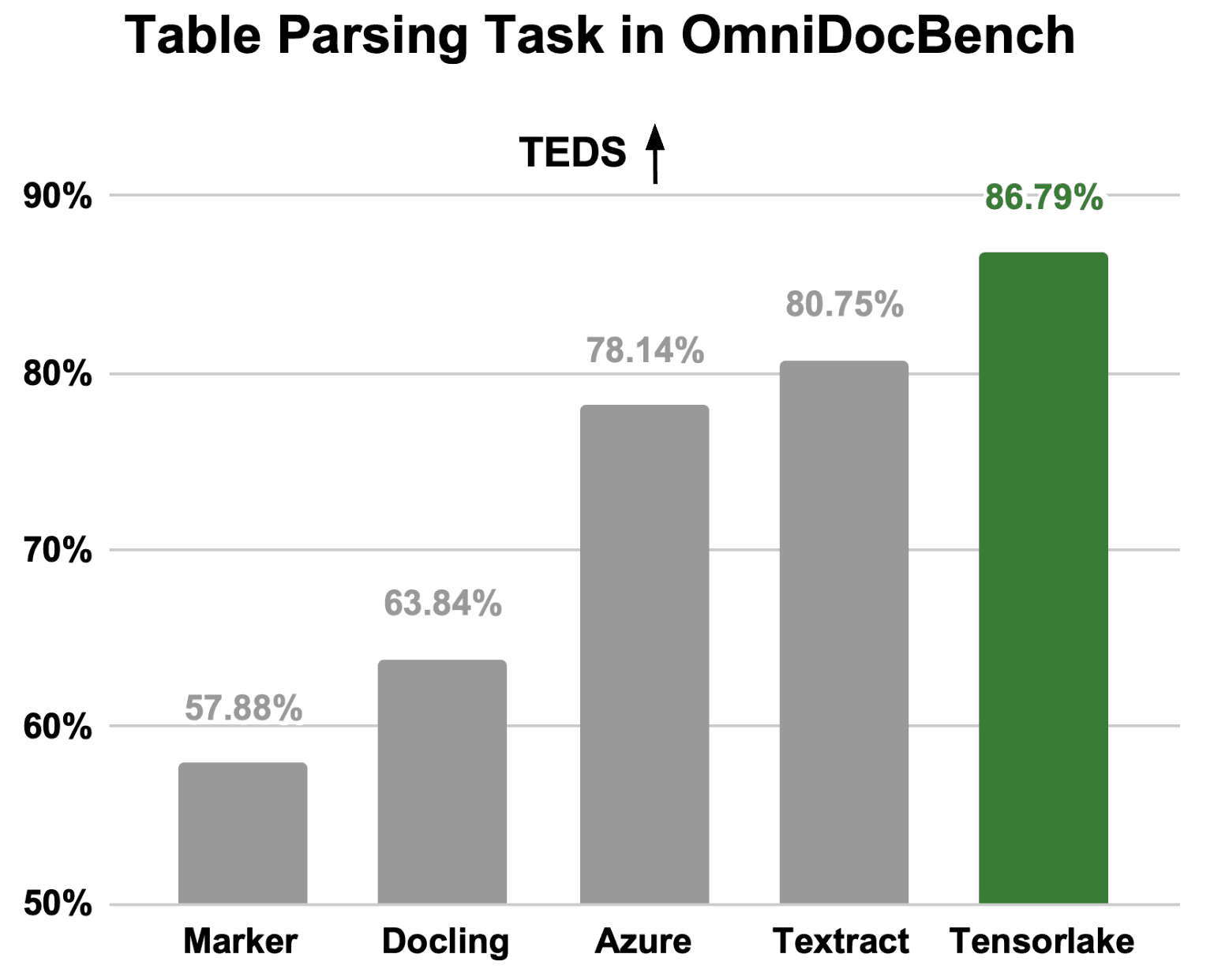
테이블 파싱에서 드러난 리더 – Tensorlake, 집요한 구조 보존력
문서 중 가장 까다로운 케이스 중 하나가 바로 테이블, 그중에서도 머지셀·멀티헤더·칸이 꼬인 복합 테이블입니다. 최신 벤치마크(OmniDocBench)에서는 Tensorlake가 경쟁자(아마존 Textract, MS Azure, 오픈소스 Docling, Marker 등)를 크게 앞섰습니다.
 이미지 출처: tensorlake
이미지 출처: tensorlake
{kind=link}
Tensorlake 모델: TEDS 86.79%
Textract: 80.75%
Azure: 78.14%
오픈소스 Docling: 63.84%, Marker: 57.88%
특히 20% 이상 벌어지는 점수 차이는 복잡한 테이블이나 여러 페이지가 이어진 문서에서도 구조를 거의 원본 그대로 가져오는 기술력 덕분입니다.
실전 기업문서에서 진짜 승자는? – JSON F1 점수 91.7%, 의미하는 것
테스트 셋만 좋은 게 아니라, 실제 기업 환경(은행, 리테일, 보험 등)의 100개 이상 ‘실전 문서’에서도 Tensorlake가 뚜렷하게 앞섰습니다.
 이미지 출처: tensorlake
이미지 출처: tensorlake
{kind=link}
Tensorlake: F1 91.7
Gemini: F1 89.0
Textract: F1 88.4
Azure: F1 88.1
Marker: F1 83.3
Docling: F1 68.9
차이가 작아 보이지만, 91.7%와 68.9%의 차이는 20개 문서 중 ‘정확하게 추출된 필드가 5개 더 많다’는 의미입니다. 수천 장 실전 문서를 자동화하는 기업 현장에서는 오류율이 체감적으로 확 줄어듭니다.
복잡한 레이아웃 보존은? – 예시 비교로 보는 구조적 똑똑함
단순 숫자 추출이 아니라, ‘주소 부분은 한 덩어리, 이메일/전화번호/이름이 칸칸이 나뉘는 계약서’에서 경쟁 모델들은 종종 읽는 순서가 꼬이거나 핵심 필드가 누락됩니다. 아래 예시를 보면,
 이미지 출처: tensorlake
이미지 출처: tensorlake
{kind=link}
Tensorlake만이 ‘읽는 순서’와 ‘데이터의 뭉치’를 제대로 보존하여, 다운스트림 자동화(예: 보험금 청구, 고객정보 추출)에 바로 써먹을 수 있게 출력합니다.
가격까지 현실적으로 따져보면? – 최고의 성능/가격비
마지막으로 실제 ‘비용’을 따졌을 때도 Tensorlake는 탁월합니다.
Tensorlake: 1,000페이지당 $10 (TEDS 86.79, F1 91.7)
Azure: 1,000페이지당 $10 (TEDS 78.14, F1 88.1)
AWS Textract: 1,000페이지당 $15 (TEDS 80.75, F1 88.4)
즉, Azure와 같은 가격에 성능은 훨씬 높고, AWS Textract 대비 50% 저렴하면서도 품질도 앞서는 셈입니다.
마무리 – 똑똑하고 경제적인 문서 파싱, AI 실전의 절대 조건
AI와 문서 파싱의 만남은 단순 ‘스캔→텍스트’ 시대에서 완전히 벗어났습니다. 구조 정보, 실전 추출 정확도, 그리고 가격까지 모두 챙겨야 하는 시대죠. 최근 평가에서는 Tensorlake가 구조 보존력, 실제 업무 데이터 품질, 그리고 비용 측면까지 ‘실전용 문서 파싱 API’로서 두각을 보였습니다.
기업이나 개발자가 문서 자동화를 고민한다면, 단순 OCR이 아니라 “내 downstream 시스템이 바로 쓸 수 있는 데이터가 만들어지는가?”를 가장 먼저 점검하세요. 그리고 여러 모델의 벤치마크 결과와 실제 현업 활용 경험을 함께 따져보면, 성공적인 AI 도입의 문이 넓게 열릴 수 있습니다.
참고문헌
[1] Benchmarking the Most Reliable Document Parsing API | Tensorlake - Tensorlake
[2] Document Intelligence in 2025: OCR Platforms Compared for IDP - Windows Forum
[3] PDF Parser: Extract Data from Documents Online - GroupDocs
[4] Comparing the Top 6 OCR Models in 2025 - MarkTechPost
이미지 출처
AI-generated image