
LLM 에이전트(Agent)란? 실전에서 성공하는 AI 에이전트 구축 노하우

AI 산업 전반에서 크게 화두가 되고 있는 'LLM 에이전트'. 많은 개발팀이 도입하고 있지만, 복잡한 프레임워크나 특수 라이브러리를 쓰는 팀보다, 단순하고 조합 가능한 패턴으로 실용적으로 접근하는 팀이 더 뛰어난 성과를 거두는 것이 현실입니다. 이번 글에서는 Anthropic의 실제 고객 경험과 직접 개발한 사례를 바탕으로, LLM 에이전트 시스템을 똑똑하게 만드는 핵심 원리와 실용 팁을 쉽게 풀어드립니다.
LLM 에이전트와 워크플로우의 차이
'에이전트(Agent)'란 용어만큼 정의가 다양한 것도 드물죠! 어떤 기업은 에이전트를 "장시간 독립적으로 동작하며 다양한 툴로 복잡한 업무를 해결하는 완전자동 시스템"으로 보고, 또 어떤 곳은 "정해진 워크플로우를 따르는 특정 규칙 기반 구현체"라 칭합니다. Anthropic에서는 이 모두를 '에이전틱 시스템'으로 분류하지만, 구조상 큰 차이가 있습니다.
워크플로우(Workflow): LLM과 각종 도구가 미리 정해진 코드 흐름대로 orchestrated(조율)됩니다.
에이전트(Agent): LLM이 실시간으로 자신의 작업 플랜과 도구 사용법을 스스로 결정하며, 전체 과정을 직접 통제합니다.
즉, 워크플로우는 예측 가능한 일에 강하고, 에이전트는 복잡하거나 변동성이 큰 업무에 유연하게 대응합니다.
만약 당신의 일에서 LLM 증강을 사용하라.
언제 에이전트를 써야 할까? 업무에 맞는 시스템 선택법
LLM 기반 서비스를 설계할 때는 늘 '가능한 한 단순하게' 출발하는 것이 좋습니다. 에이전틱 시스템은 빠른 처리 속도나 비용 최적화 대신, 더 복잡한 일상적/비정형 업무에서 성능 향상을 가져옵니다. 꼭 필요하지 않다면 굳이 모든 문제에 에이전트 구조를 적용할 필요는 없습니다.
잘 정의된 반복 업무: 간단한 LLM 호출과 예시(example) 또는 리트리벌(retrieval) 기법만으로 충분
유연성과 문제 해결력이 중요한 대규모 작업: 에이전트가 진가를 발휘
예측 가능하고 일정한 결과가 필요한 경우: 워크플로우 구조가 적합
에이전트 구조 도입은 충분히 숙고한 뒤 업무 성격에 맞게 선택해야 합니다.
에이전트 프레임워크 활용 가이드
에이전트를 쉽게 만들 수 있는 다양한 프레임워크가 존재합니다. 대표적으로 LangGraph(LangChain), Amazon Bedrock AI Agent Framework, Rivet, Vellum 등이 있죠. 이들 프레임워크는 LLM 호출, 도구 연결, 작업 연결 등 반복적인 저수준 문제를 덜어주지만, 지나치게 많은 추상화 계층을 도입해 디버깅을 어렵게 만들 수도 있습니다.
초기 개발에는 프레임워크가 도움이 되지만, 본격 생산 환경에선 최대한 직접 LLM API로 구현해 구조를 정확히 이해하는 것이 중요합니다. 복잡한 시스템일수록 프레임워크의 내부 동작을 제대로 파악하는 것이 필수입니다.
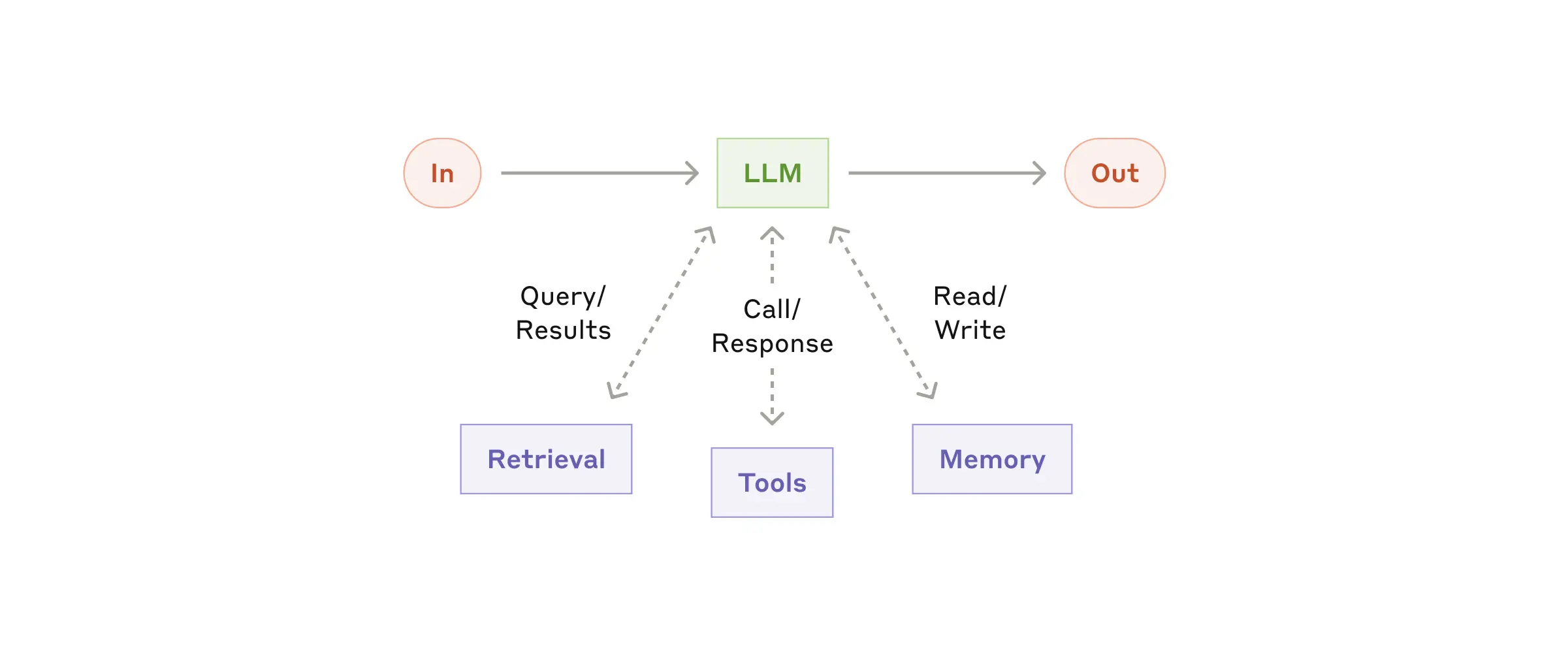
에이전트 구축의 기본: '확장된 LLM' 설계
에이전트 시스템의 출발점은 LLM을 '리트리벌(검색)', 툴 사용, 메모리 등으로 확장하는 것에서 시작합니다. 현 최신 LLM은 검색 쿼리 생성, 적절한 도구 선택, 정보 보관 등 능동적으로 추가 능력을 활용할 수 있습니다.
핵심은 당신의 서비스 목적에 맞게 커스터마이즈하고, 누구나 쉽게 활용할 수 있도록 명확하고 친절한 인터페이스를 만드는 것입니다. 최근 공개된 Model Context Protocol처럼 써드파티 도구가 손쉽게 연동되는 표준도 활용할 수 있습니다.
단계별 워크플로우 패턴: 프롬프트 체이닝부터 최적화까지
복잡한 시스템을 만드는 데 있어 흔히 활용되는 에이전트 패턴은 아래와 같습니다.
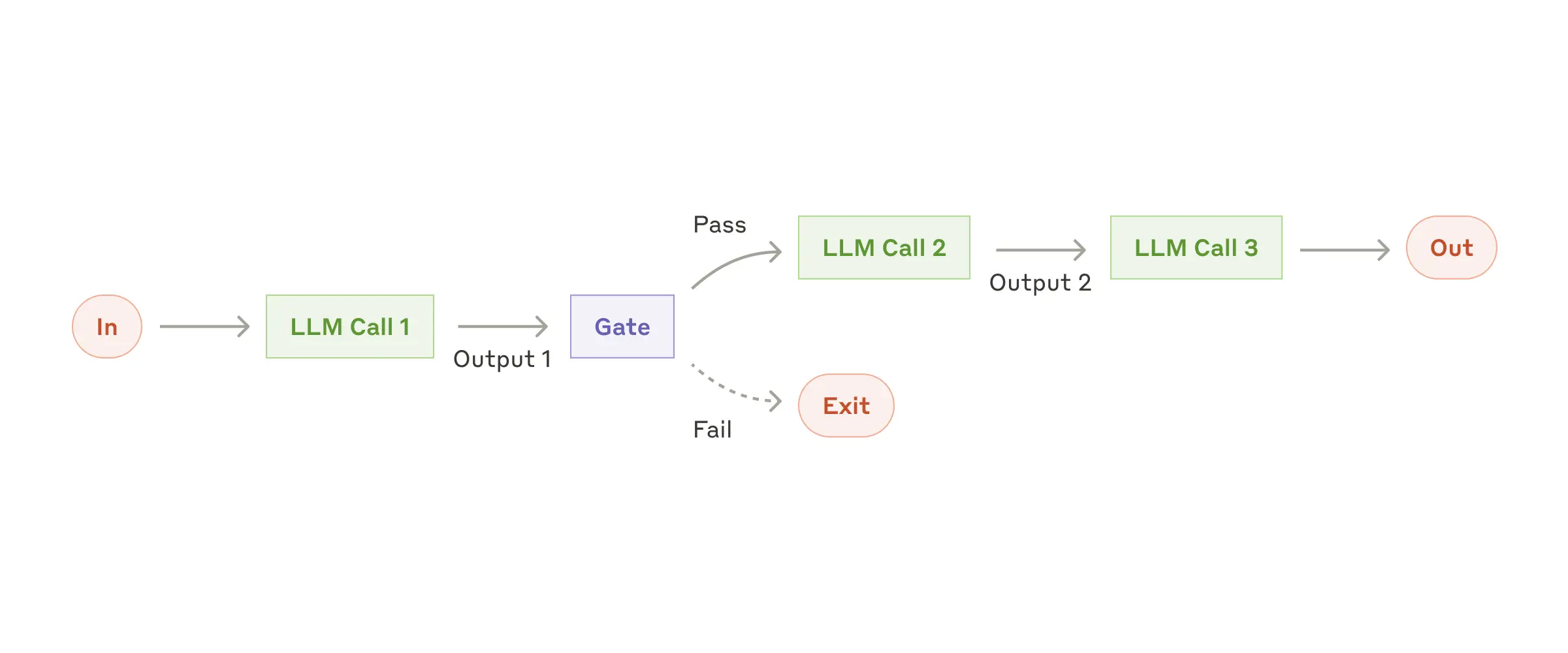
프롬프트 체인(Prompt Chaining)
작업을 작은 단계로 쪼개 LLM이 순차적으로 문제를 해결합니다. 각 단계마다 검사(gate)를 넣어 정확도를 높이지요.
활용예: 마케팅 문구 생성 후, 다른 언어로 번역 / 문서 개요 작성 + 검토 후 완성
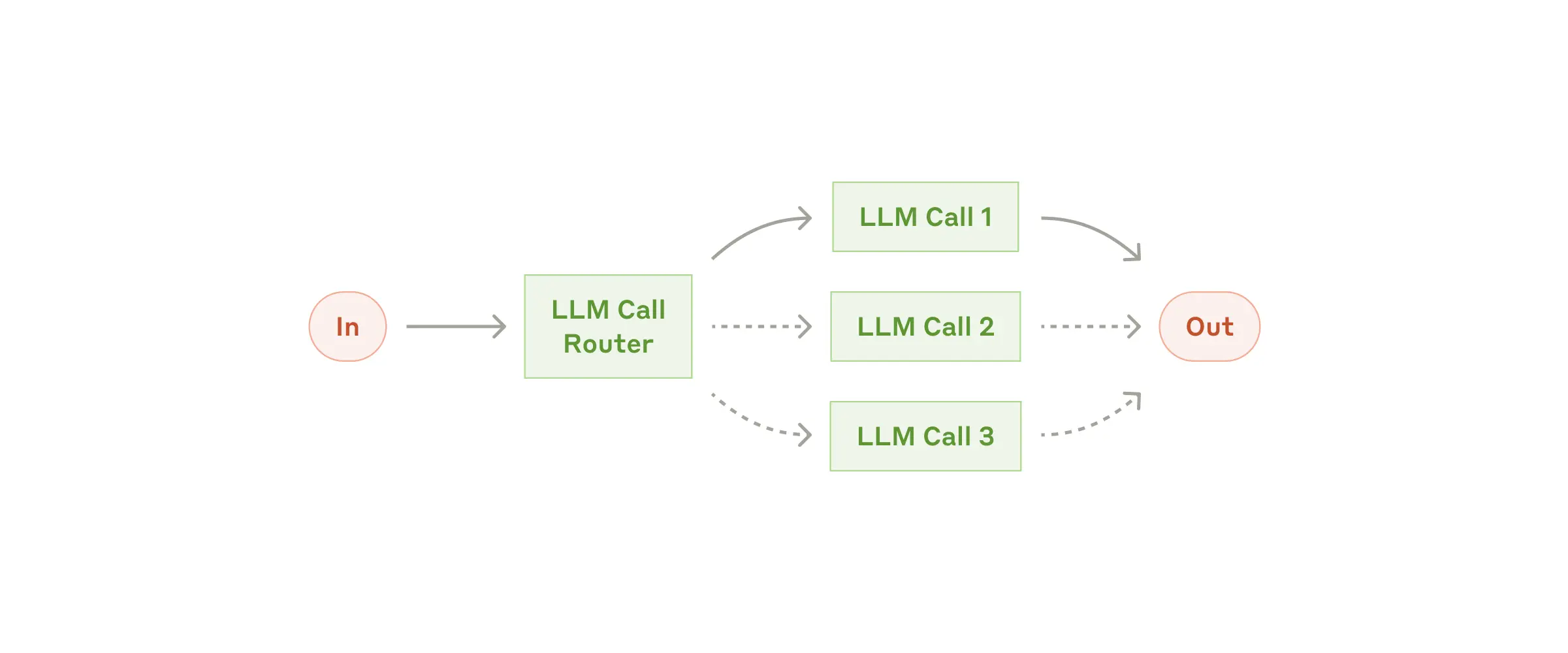
라우팅(Routing)
입력값을 분류/판별해, 각각의 전문적인 라벨이나 프롬프트, 도구로 전달합니다.
활용예: 고객 문의별로 일반 질의-환불 요청-기술 지원 등별로 분리 / 쉬운 질문은 소형 모델, 어려운 질문은 대형 모델로 배분
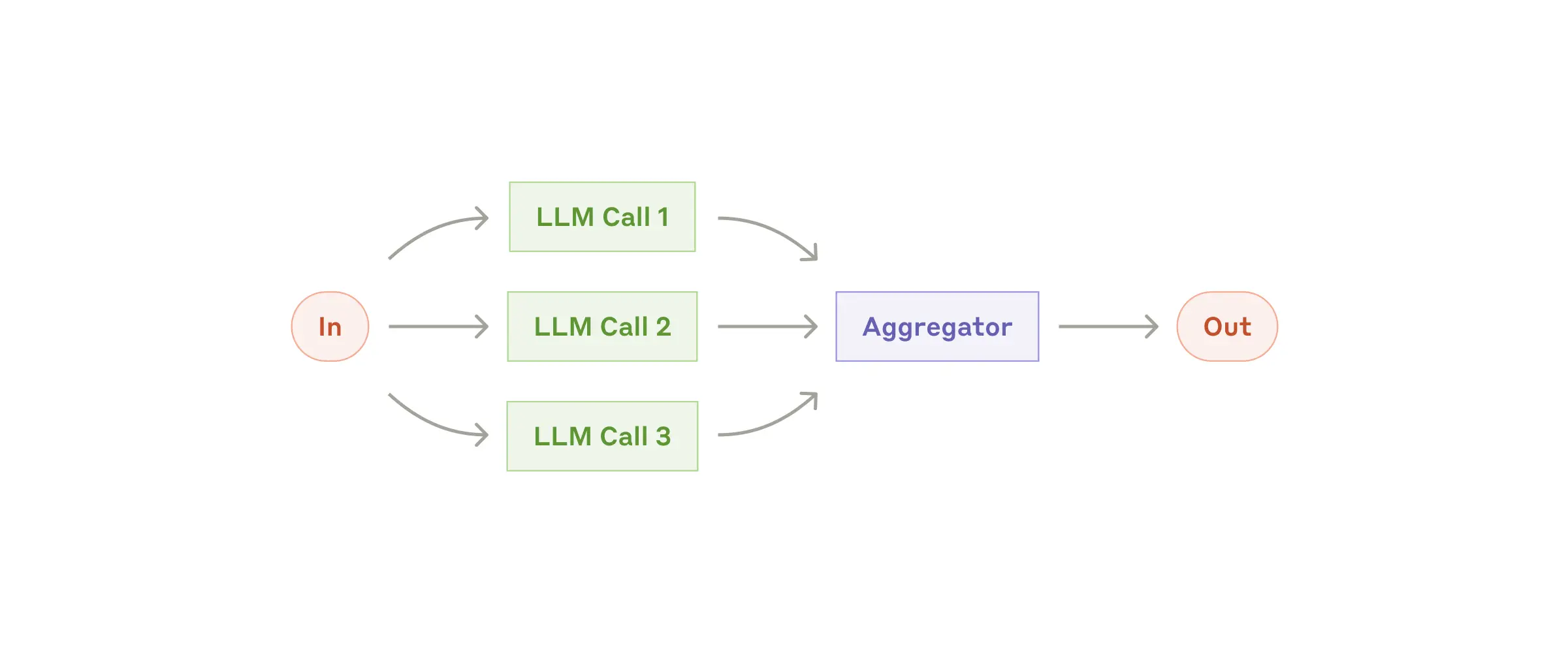
병렬화(Parallelization)
동일/비슷한 작업을 여러 LLM 인스턴스가 동시에 처리한 뒤, 결과를 모아 평가합니다.
활용예: 코드 보안 리뷰를 여러 각도로 동시에 실행 / 콘텐츠 적합성 판단을 여러 기준으로 동시 평가
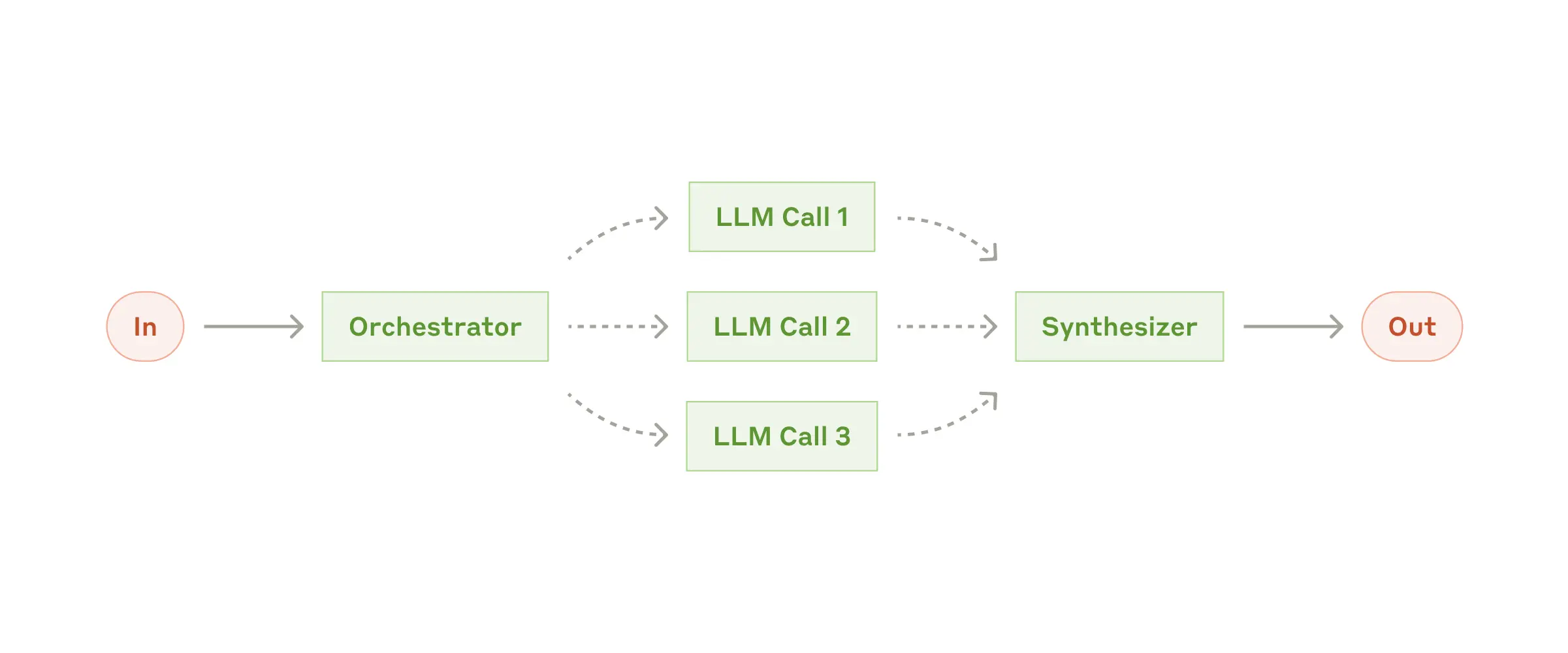
오케스트레이터-워커(Orchestrator-Workers)
중앙 LLM이 문제를 쪼개 워커(다른 LLM)들에게 분배 후, 결과를 합산/검토합니다. 유동적 분업이 필요할 때 특히 유용합니다.
활용예: 여러 파일을 동시에 수정해야 하는 코드 작업 / 다수 정보원을 조사하는 복합 검색
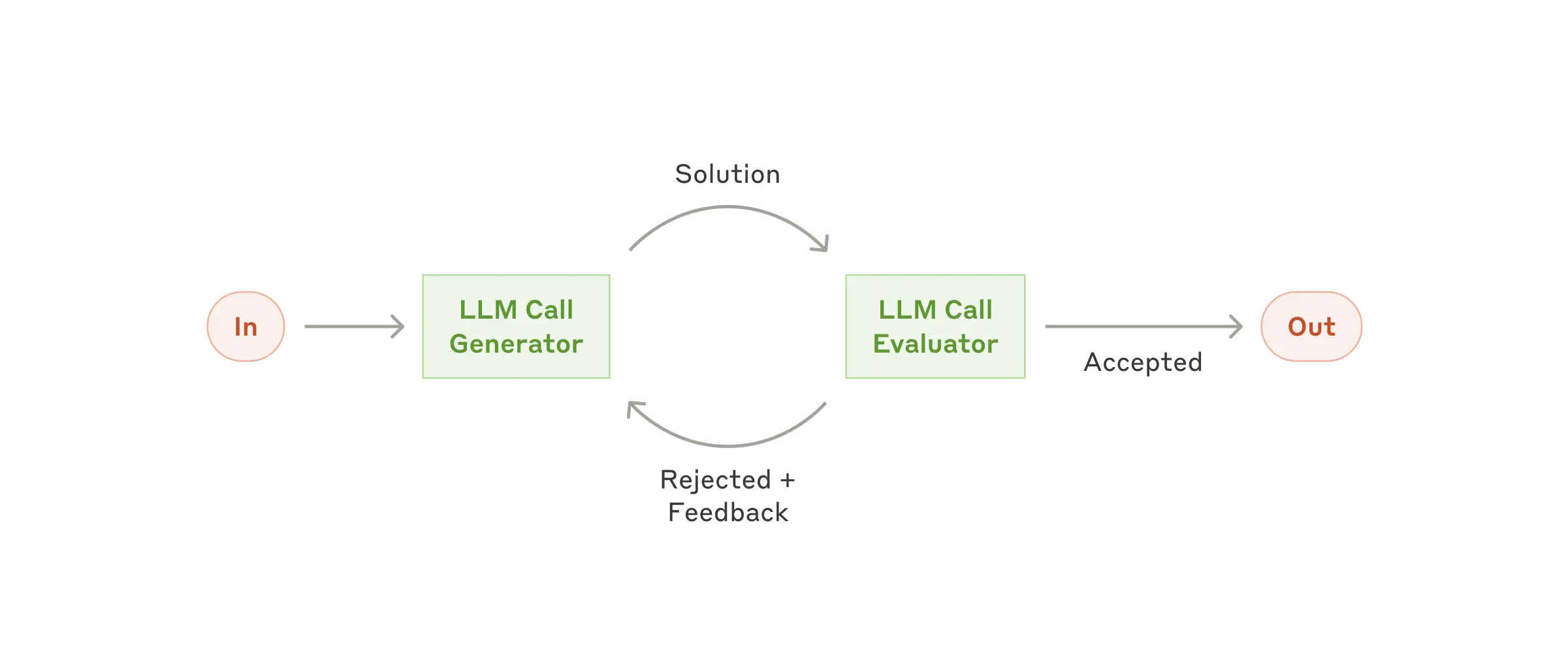
평가자-최적화기(Evaluator-Optimizer)
한 LLM이 해결안을 만들고, 다른 LLM이 평가/피드백을 주는 반복형 구조입니다.
활용예: 번역 뉘앙스 정확도 잡기 / 복합 검색 반복 수행
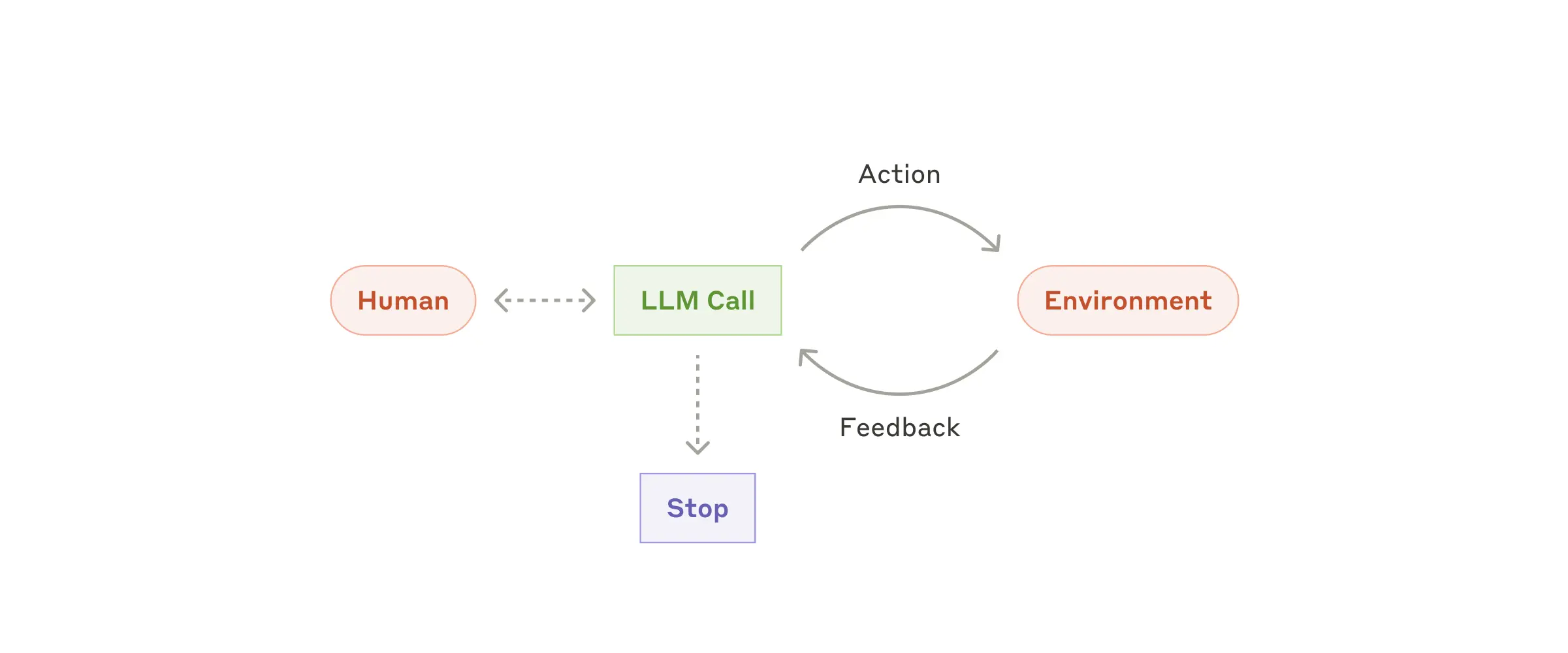
자율 에이전트(Autonomous Agent) 운용법과 주의점
최신 LLM의 성장에 따라 '자율 에이전트'가 현실화되고 있습니다. 사용자가 명령이나 대화로 작업을 요청하면, 에이전트는 직접 계획을 세우고 도구 사용-결과 확인 과정을 반복하며 작업을 완수합니다. 중간중간 사용자의 피드백을 받고, 환경정보(ground truth)를 독립적으로 수집해 자기 판단을 강화하지요.
에이전트는 미리 정의할 수 없는 복잡한, '정답 경로가 없는' 업무에 강합니다. 하지만 처리 횟수가 늘어나면 비용도 높아지고, 작은 오류가 연쇄적으로 커진다는 점도 유의해야 합니다. 반드시 샌드박스 환경에서 충분히 테스트하고, 필요한 안전장치(Guardrail)를 마련해야 안전하게 운영할 수 있습니다.
활용 예: 여러 파일 동시 수정 자동화, 컴퓨터 전체 제어 도구(Demo 링크 등)
다양한 패턴의 조합과 커스터마이징 전략
지금까지 소개한 패턴들은 절대적인 규칙이 아니라, 각 서비스 목적에 맞게 조합·변형이 가능한 활용법입니다. 핵심은 결과 품질을 지속적으로 측정하고, 실제로 효과가 있을 때만 복잡성을 추가하는 것입니다. 에이전트의 도입은 '더 복잡하게'가 아니라, '더 현명하게'가 목표여야 합니다.
실전에서 빛나는 에이전트 활용 사례
Anthropic이 고객과 함께 구축한 실제 에이전트 서비스에는 두 가지가 대표적입니다.
고객 지원(Chatbot + 도구 통합) 단순 질의응답을 넘어, 주문내역 조회·환불 처리·티켓 업데이트·지식베이스 검색 등 외부 도구 활용이 자유롭고, 문제해결 기준도 명확해 비즈니스적으로 완성도가 높습니다. 기업 입장에서는 실제 고객 해결 횟수에 따라 과금하는 모델도 성공적으로 도입하고 있습니다.
코딩 에이전트(자동 문제 해결) 에이전트가 PR 설명만 보고 자동 테스트를 통해 실질적인 문제 해결을 수행합니다. GitHub 이슈 실전 적용(SWE-bench 등) 덕분에 코드 검증도 자동화되고, 정량적 품질 평가도 손쉽게 이루어집니다. 단, 궁극적 품질 보장은 여전히 사람의 검토가 중요합니다.
에이전트 도구 개발: 프롬프트 엔지니어링 팁
에이전트가 외부 서비스나 API와 잘 소통하려면, '도구 정의'에 공들이는 것이 중요합니다. 몇 가지 실전 팁!
모델이 충분히 고민할 시간(token)을 주자
실제 인터넷 텍스트와 유사한 포맷을 최대한 이용
불필요한 포맷이나 추가 처리(몇천 줄씩 코드 라인 세기 등)는 피하기
Python에서 docstring 쓰듯, 도구 설명을 간단·명확·예시 포함형으로 작성한다
변수명이나 파라미터명을 구체적으로 바꿔 모델이 혼동하지 않게 한다
실제 워크벤치 등에서 다양한 입력 예시로 모델의 사용 오류를 점검하고 반복 개선
실수 유도 위험(Poka-yoke)이 있는 도구 구조는 설계 차원에서 막는다
실제로 SWE-bench 같은 복잡한 에이전트 개발에서는 전체 프롬프트보다 도구 정의에 더 많은 시간과 고민이 들어갑니다. 예를 들어, 파일 경로를 모델이 혼동할 때는, 아예 절대경로만 사용하도록 도구 사양을 바꿔 실수가 0에 가까워진 것도 좋은 사례입니다.
에이전트 설계와 운영, 어떻게 시작할까?
LLM 에이전트 구축의 성공은 '가장 복잡한 시스템'을 만드는 것이 아니라, '업무에 꼭 맞는 최적의 시스템'을 선택하는 데 있습니다.
Anthropic의 경험이 담긴 3대 원칙:
단순함: 시스템 구조는 최대한 간결하게
투명성: 에이전트의 계획과 의사결정 과정을 명확하게
도구 문서화와 테스트: 에이전트-컴퓨터 인터페이스(ACI)는 철저하고 꼼꼼하게
도입 초기엔 프레임워크를 활용해 빠르게 시작하고, 생산 단계에서는 단계적으로 직접 구현(직접 LLM API, 코드 기반)으로 전환하는 것이 결과적으로 신뢰성·유지보수에 유리합니다.
강력하면서도 믿고 쓸 수 있는 에이전트를 만들고 싶다면, 위의 기본 원칙을 꼭 기억해주세요!
고성능 LLM 에이전트, 어렵고 복잡하게 생각할 필요 없습니다. 단순하지만 목적에 맞는 구조—그리고 끊임없는 실측·개선—이 바로 성공의 핵심입니다. 지금 당장 직접 구현해 보고, 작은 목표 달성부터 차근차근 성능을 높여 보세요!
출처 및 참고:
https://www.anthropic.com/engineering/building-effective-agents