
AI와 개인정보 보호의 미래, VaultGemma가 여는 새로운 길
‘AI가 내 개인정보를 기억한다면?’ 이 질문에서 시작된 고민은 인공지능 연구의 가장 뜨거운 화두가 되었습니다. 이제 구글 DeepMind의 차세대 인공지능, VaultGemma가 그 답을 제시합니다. VaultGemma는 ‘차등 비공개’라는 수학적 마법으로, 데이터의 비밀을 지키면서도 똑똑한 언어 모델을 만든 혁신의 산물입니다. 이 글에서는 VaultGemma가 어떻게 작동하는지, 왜 중요한지, 그리고 AI와 개인정보 보호가 어떻게 공존할 수 있는지 쉽게 풀어보겠습니다.
VaultGemma란? – 개인정보를 지키는 차등 비공개 인공지능
VaultGemma는 구글 DeepMind가 개발한 세계 최대 규모의 ‘차등 비공개’(Differential Privacy) 대형 언어 모델입니다. 차등 비공개란, AI가 학습하는 데이터에 ‘조정된 노이즈’를 살짝 끼얹어서, 특정 개인에 대한 정보나 흔적을 모델이 기억하지 못하게 만드는 기술입니다. 덕분에 VaultGemma는 기존 AI처럼 ‘누구의 정보였더라?’ 하고 몰래 기억하는 일이 크게 줄어듭니다.
이 모델은 무려 1억 개(1B)의 파라미터를 갖추고, 모든 학습 과정에서 강력한 개인정보 보호 기준(ε ≤ 2.0, δ ≤ 1.1e-10)을 적용했습니다.
왜 개인정보 보호가 중요한가? – AI의 ‘기억하기’ 문제
대형언어모델(LLM)은 엄청난 양의 텍스트와 데이터를 학습하면서 때로는 본인의 임무를 넘어 ‘훈련 데이터’를 그대로 외워버릴 수 있습니다. 이런 현상은 마치 친구에게 비밀을 이야기했다가, 그 친구가 모두에게 퍼트리는 것과 같습니다.
하지만 VaultGemma에 적용된 ‘차등 비공개’는 이런 위험을 수학적으로 원천 차단합니다. 아무리 파라미터가 많아도, 특정 훈련 데이터나 개인을 모델이 알아낼 수 없도록, 데이터에 체계적으로 무작위성을 주입합니다.
차등 비공개의 원리 – 노이즈와 데이터, 최고의 균형 찾기
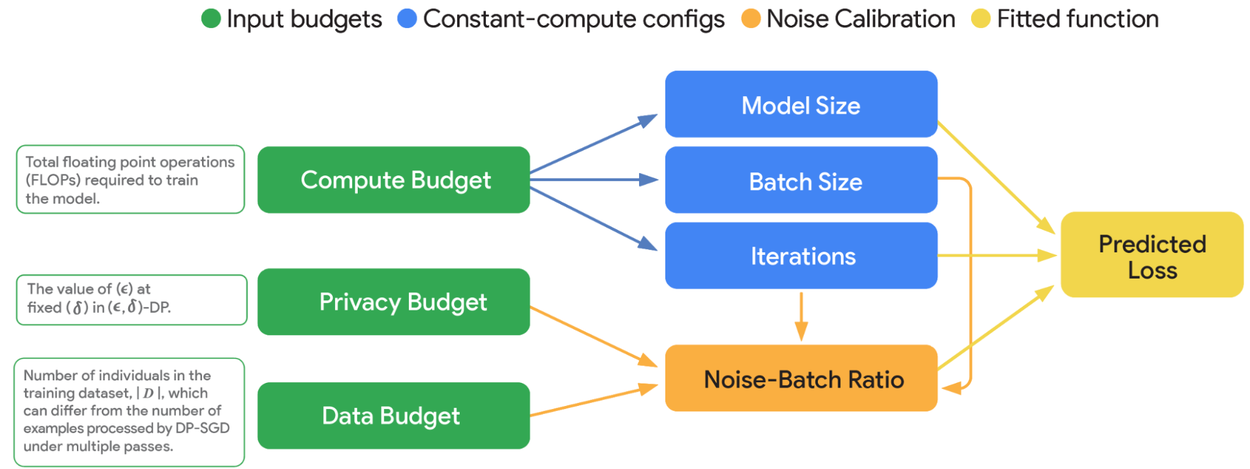
차등 비공개(즉, Differential Privacy)의 핵심은 ‘노이즈-배치 비율’입니다. 쉽게 말해, 훈련할 때 데이터 각각에 아주 작은 랜덤한 흔적을 남기면서, 모델이 개별 정보를 영원히 기억하지 못하게 만듭니다.
하지만 노이즈를 많이 주면 모델의 학습 효율이 떨어지죠. 그래서 VaultGemma의 연구진은 모델의 크기, 배치 사이즈, 전체 훈련 횟수 등 여러 요소의 황금 비율을 찾기 위해 수백 가지 실험을 했습니다. 그 결과, ‘작은 모델을 큰 배치로 훈련하는 방식’이 차등 비공개 AI에는 효과적이라는 사실을 밝혀냈습니다.
 이미지 출처: storage
이미지 출처: storage
{kind=link}
VaultGemma의 기술적 혁신 – 최적화된 훈련 방식과 알고리즘
구글은 오픈소스 모델 Gemma를 바탕으로, 차등 비공개 학습을 위한 최적의 알고리즘을 개발했습니다. 특히 데이터 배치를 불규칙하게 샘플링하는 ‘Poisson 샘플링’과 배치 크기 패딩 기술 등으로 프라이버시 보장은 강화하면서도 성능 손실을 최소화했습니다.
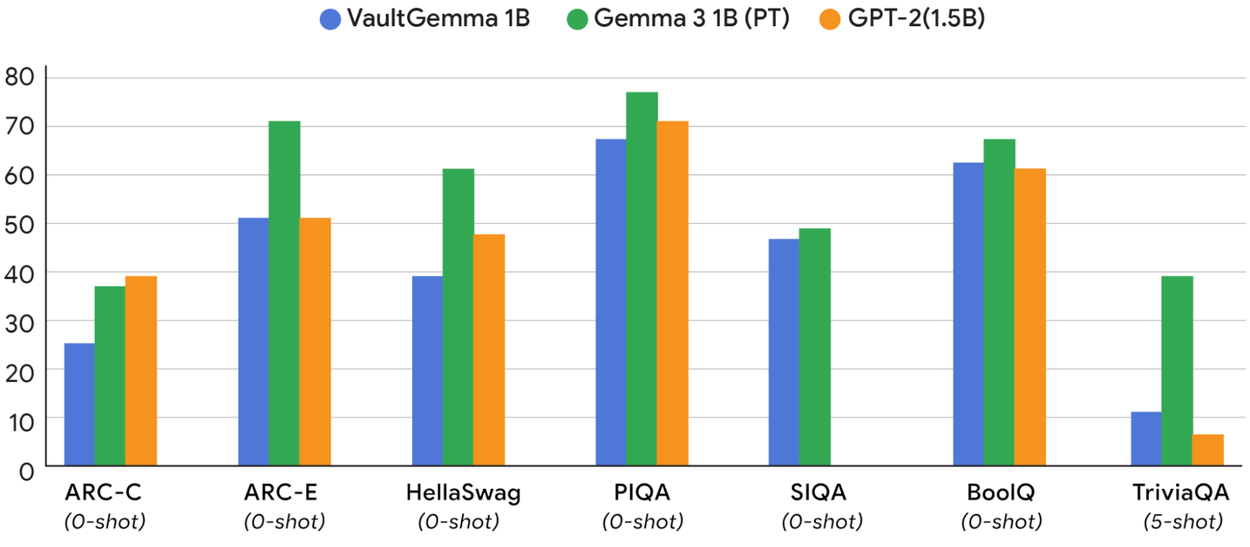
또한, 모델의 훈련 과정과 결과 예측의 ‘스케일링 법칙’을 수립, 실제 VaultGemma의 성능이 이 데이터로 완벽히 예측 가능함을 보여줍니다. 실제로 VaultGemma는 약 5년 전의 대표적 비공개 모델(GPT-2, 1.5B)과 동급의 성능을 기록했고, 그만큼 현 기술로도 실용성을 확보했음을 입증했습니다.
 이미지 출처: storage
이미지 출처: storage
{kind=link}
실제 활용과 가능성 – 안전한 AI, 윤리적 데이터 사용의 길
VaultGemma는 의료, 금융, 법률 등 데이터의 비밀을 꼭 지켜야 하는 분야에서 빛날 수 있습니다. 모델을 오픈소스(Hugging Face, Kaggle 등)로 공개해 누구나 직접 실험, 검증, 응용이 가능하며, 궁극적으로 프라이버시를 우선하는 AI 생태계를 만드는 데 중요한 기초를 제공합니다.
예를 들어 개인 건강 데이터나 민감한 금융정보도 VaultGemma로 학습시키면, AI가 구체적인 정보를 기억하거나 외부로 유출할 위험이 크게 줄어듭니다.
한계와 앞으로의 과제 – ‘기억하지 않는 AI’에서 ‘실용적 AI’까지
현재 VaultGemma는 ‘안전한 AI’라는 목표에 한 걸음 더 다가갔지만, 아직 최신 비공개 모델만큼의 성능과 속도는 구현하지 못했습니다. 차등 비공개의 수학적 원리는 계산 비용과 하드웨어 제약 등 과제를 남기지만, 연구진은 앞으로 더 효율적인 알고리즘과 설계로 실용성과 성능 격차를 좁힐 계획입니다.
결론 – VaultGemma가 보여준 AI와 프라이버시 혁신의 설계도
VaultGemma의 등장은 ‘AI와 개인정보 보호, 양립이 불가능하다’는 오랜 편견을 무너뜨렸습니다. 앞으로의 AI는, 단순히 ‘잘 배우는 AI’가 아니라 ‘안전하고 믿을 만한 AI’로 진화해야 하는 시대—VaultGemma가 그 길을 열고 있습니다.
프라이버시를 보호하면서도 활용도 높은 인공지능이 필요한 분야, 신뢰가 중요한 데이터 비즈니스라면 VaultGemma가 좋은 시작점이 될 수 있습니다. 앞으로 AI와 데이터가 더 안전하게, 윤리적으로, 그리고 믿음직하게 활용되는 미래가 VaultGemma와 함께 한 발 더 가까워질 것입니다.
참고문헌
[1] VaultGemma: The world's most capable differentially private LLM - DeepMind Google Blog
[2] Vaultgemma: il nuovo modello AI di Google che mette la privacy al primo posto - Digitalic
[3] VaultGemma : La révolution de l'IA privée arrive avec le plus puissant modèle de langage au monde - Kodea
[4] AIの記憶問題を解決!GoogleのVaultGemmaが変えるデータ活用 | ARCHETYP Staffing Magazine - ARCHETYP Staffing Magazine
이미지 출처
이미지 출처: Florenz Mendoza on Pexels