
Google AI의 진화: Gemini 2.5 Flash 및 Flash-Lite, 품질과 효율성이 한 단계 업그레이드!
인공지능(AI)은 매년 고속 성장 중이며, 특히 구글(Google)의 Gemini 모델은 최신 업데이트를 통해 그 진가를 더욱 높이고 있습니다. 이번에 공개된 ‘Gemini 2.5 Flash’와 ‘Flash-Lite’는 품질, 속도, 비용 효율성을 동시에 잡았다는 평을 받고 있습니다. 이 글에서는 무엇이 어떻게, 왜 달라졌는지 쉽고 흥미롭게 알려드릴게요!
Gemini 2.5 Flash와 Flash-Lite란?
Gemini 2.5 Flash와 Flash-Lite는 구글 AI의 경량 고성능 모델로, 대량의 데이터를 빠르게 처리하고 다양한 업무에 효과적으로 활용할 수 있는 인공지능입니다.
새롭게 업데이트된 2.5 버전은 품질을 업그레이드하면서도 운영 비용을 크게 줄이는 데 성공했습니다.
 이미지 출처: storage
이미지 출처: storage
{kind=link}
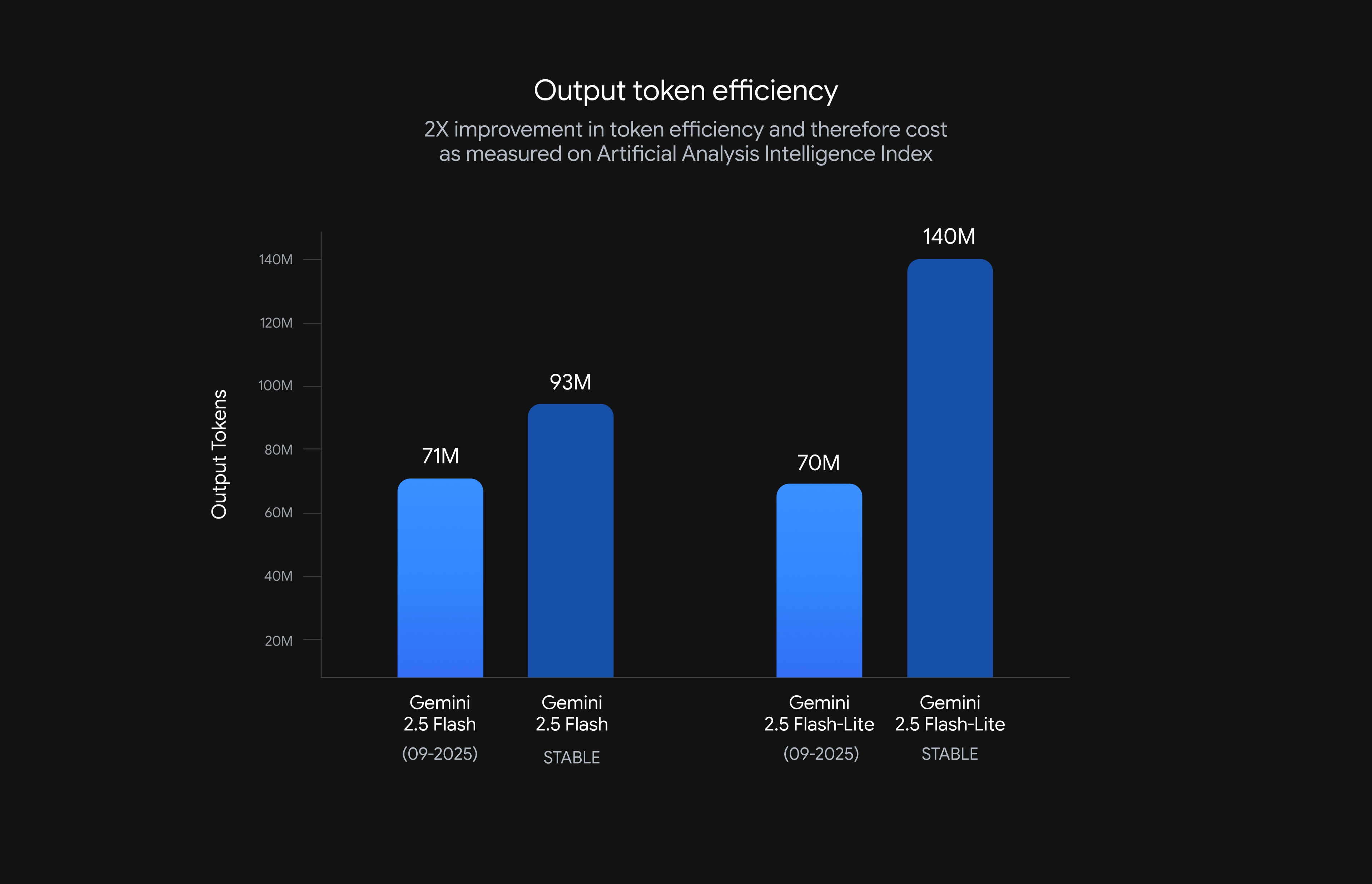
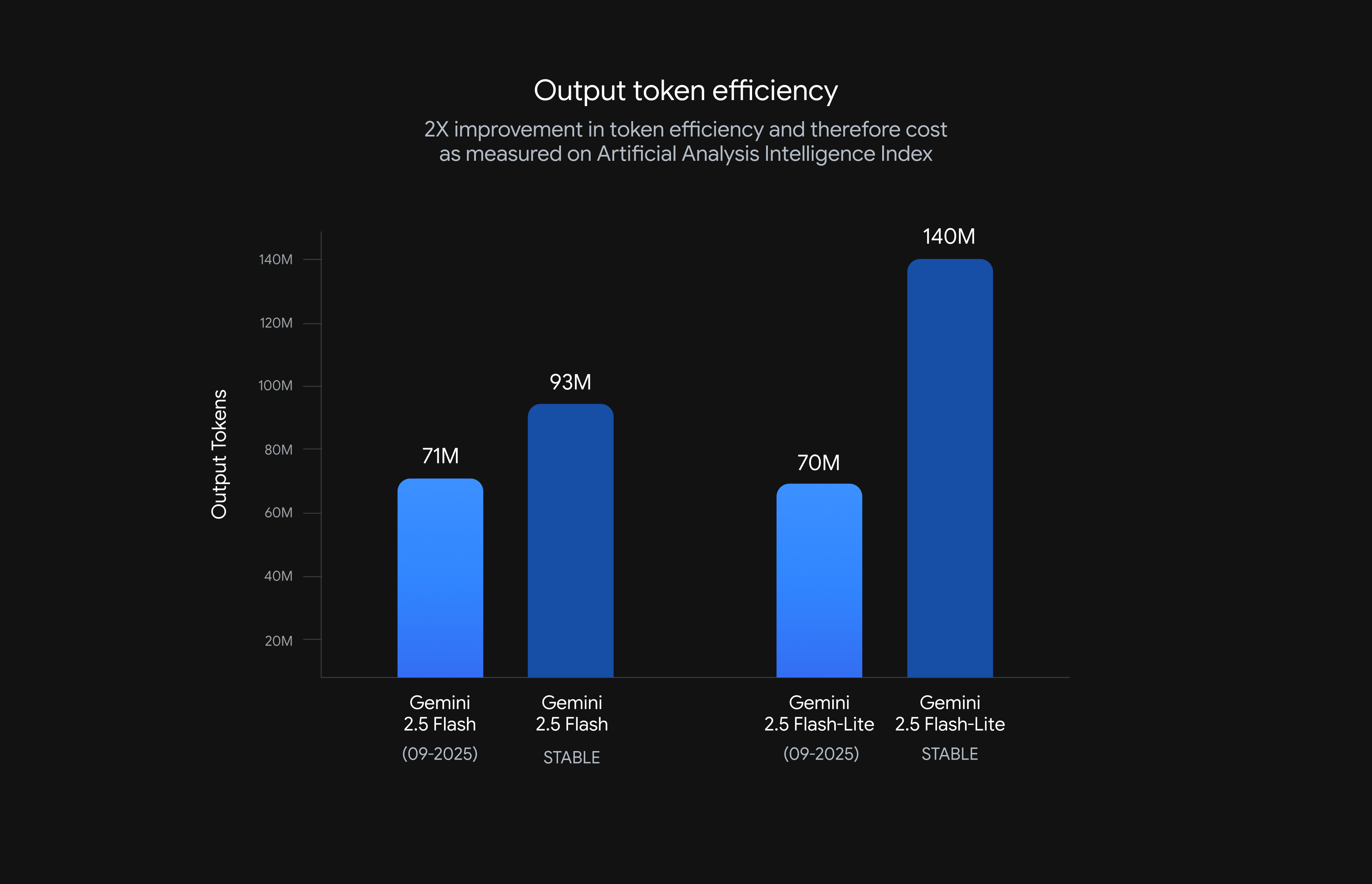
출력 토큰 최적화로 비용 절감
가장 눈에 띄는 변화는 ‘출력 토큰’ 감소입니다. 출력 토큰이란 AI가 문장이나 답변을 만들 때 사용하는 데이터 단위인데,
Flash-Lite는 출력 토큰을 무려 50%나 줄였습니다!
Flash는 24% 줄였습니다.
이를 통해 같은 품질의 결과를 훨씬 저렴하게 제공하며, 지연도 현저히 줄여 이전보다 빠른 처리 속도를 자랑합니다.
 이미지 출처: storage
이미지 출처: storage
{kind=link}
복잡한 지시 사항과 멀티모달 처리 능력 강화
Gemini 2.5 Flash-Lite는 이제 더 복잡한 지시 사항(예: 시스템 프롬프트)도 똑똑하게 이해해서 처리합니다.
또한, 다음과 같은 ‘멀티모달(다중 양식)’ 능력도 대폭 개선됐습니다.
오디오 녹음의 정확한 전사
이미지 내용의 빠른 이해
실시간 번역 품질 향상
이 덕분에 다양한 입력과 요구에도 정확하고 유연한 대응이 가능합니다.
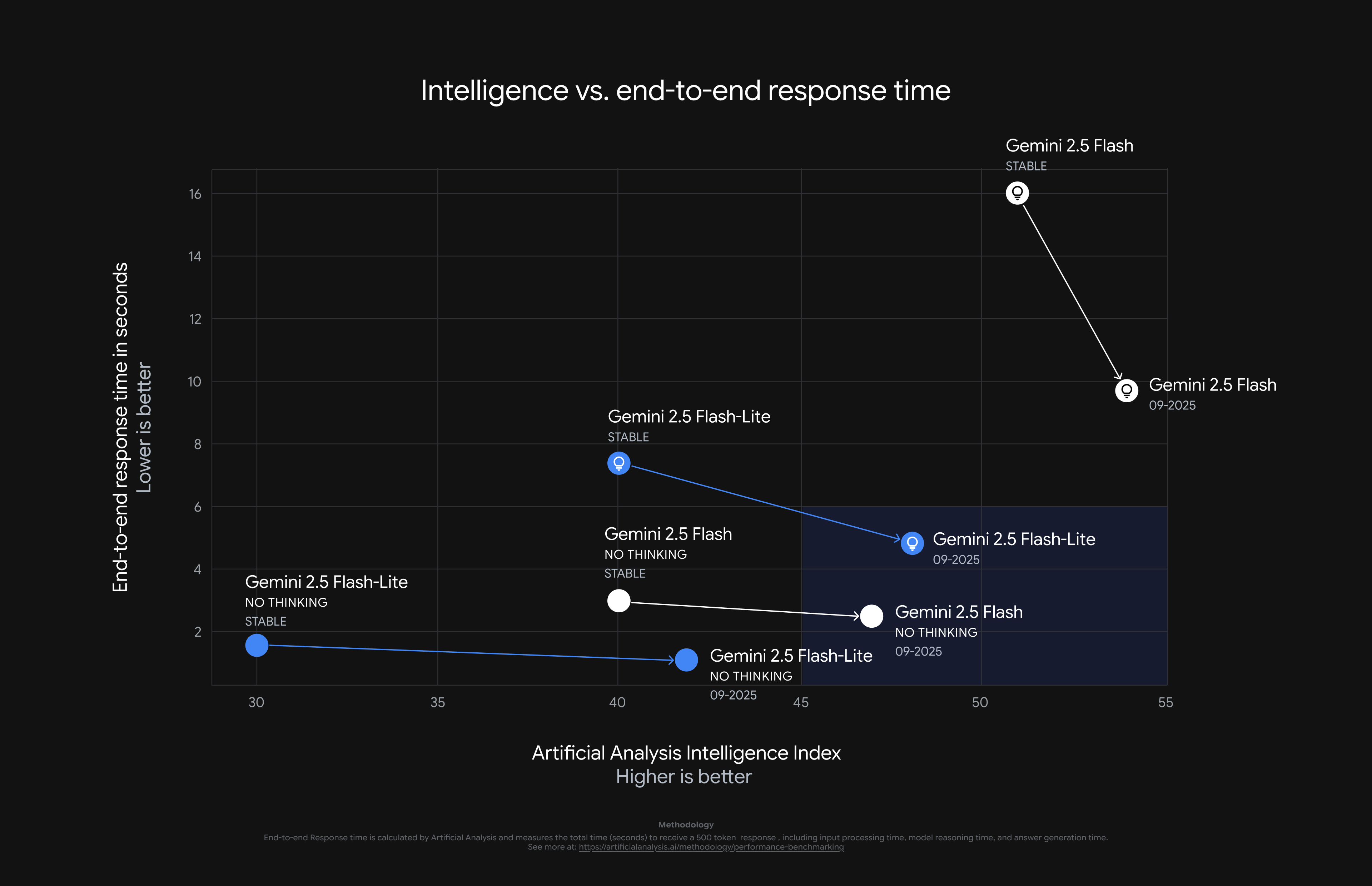
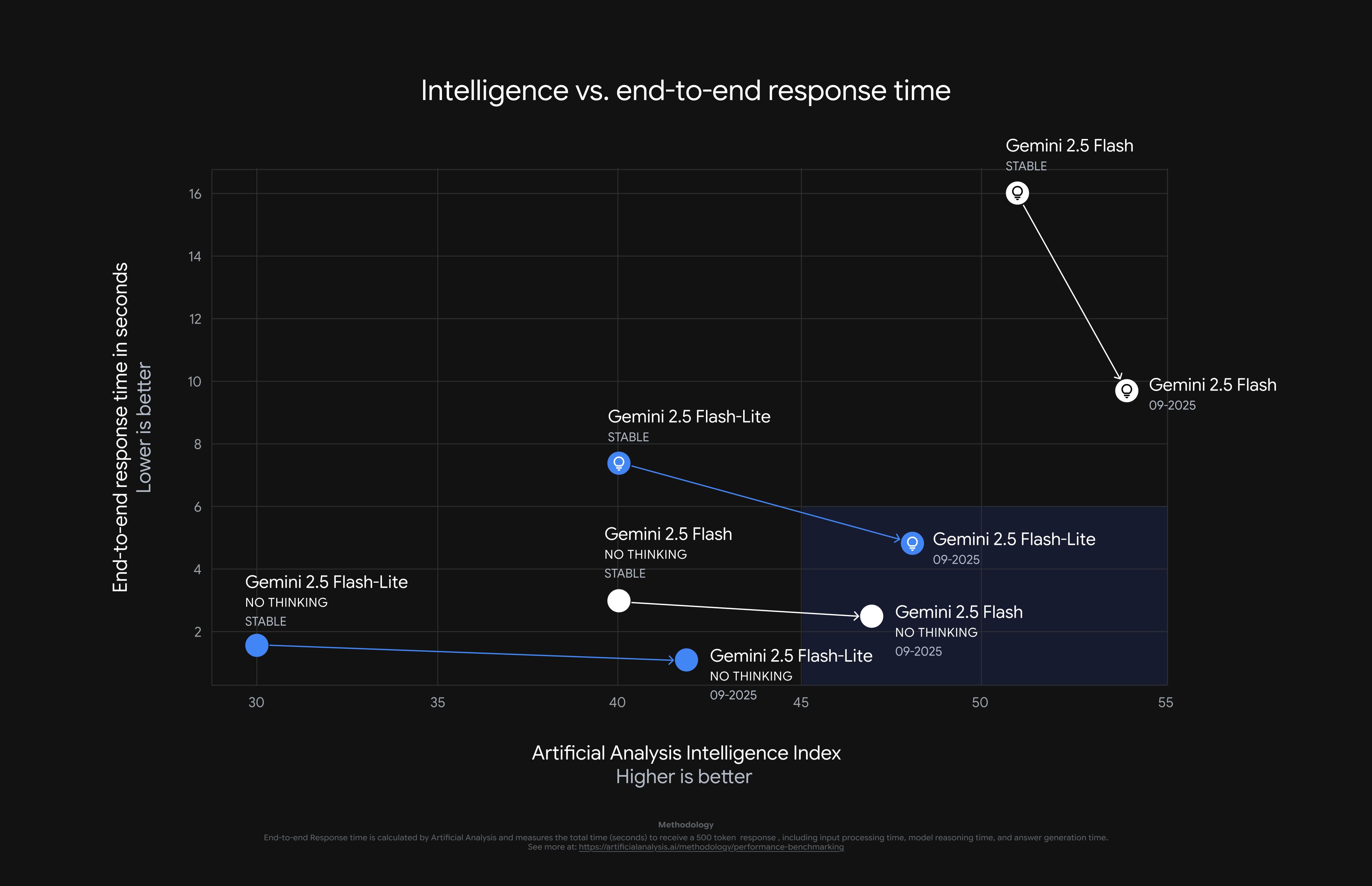
Flash 모델의 다단계 작업 및 도구 사용 능력
Gemini 2.5 Flash 버전은 복잡하고 여러 단계를 거치는 작업(예: 복잡한 워크플로우, 자동화 도구 활용)에서
성능이 눈에 띄게 향상됐습니다.
특히 다양한 도구와 연계하여 ‘스스로 판단하고 실행하는’ 에이전트(Agentic) 역할 수행이 강화돼,
장시간 학습과 분석이 필요한 과제도 더욱 효과적으로 소화할 수 있게 되었습니다.
 이미지 출처: storage
이미지 출처: storage
{kind=link}
현업 피드백과 테스트 방법
초기 테스트에 참여한 AI 업체들은 ‘속도와 지능의 균형’과 ‘비용 효율성’ 면에서 매우 긍정적인 반응을 보였습니다.
직접 사용해보고 싶다면 Google AI Studio 또는 Vertex AI를 이용해
‘gemini-flash-latest’ 또는
‘gemini-flash-lite-latest’
모델명을 통해 최신 기능을 바로 체험할 수 있습니다.
안정성과 혁신, 두 마리 토끼 잡는 전략
구글은 혁신적인 미리보기 모델로 빠른 업데이트를 제공하면서도, 안정성이 필요한 현업 사용자는 기존 버전(2.5 Flash, 2.5 Flash-Lite)도 계속 사용할 수 있도록 하고 있습니다.
이 전략 덕분에 혁신과 신뢰성을 모두 원하는 개발자와 기업에게 가장 유연한 AI 솔루션이 제공됩니다.
앞으로의 AI 활용 팁
이번 Gemini 2.5 Flash 및 Flash-Lite의 변화는
데이터 처리 비용을 절감하고 싶거나
더 빠르고 똑똑한 AI 서비스를 찾는
모든 개발자와 기업에게 큰 매력이 될 것입니다.
AI 혁신은 속도와 효율성을 동시에 잡아야 진짜 경쟁력이 되므로,
업데이트된 Gemini를 빠르게 체험해보고 미래 서비스에 미리 적용해보는 것이 현명한 전략이 될 수 있습니다.
참고문헌
[1] Continuing to bring you our latest models, with an improved Gemini 2.5 Flash and Flash-Lite release - Google Developers Blog
[2] Gemini 2.5 Flash gets improved homework guidance, image understanding, and organized responses - Fone Arena
이미지 출처
이미지 출처: Clint Maliq 🌎 on Pexels