
AI와 인공지능 시대, 280코어 인텔 서버에 맞춘 ClickHouse 초고성능 최적화 비법
AI 빅데이터 비즈니스, 실시간 분석이 필수인 시대. 인텔의 280코어 초대형 서버에서 데이터베이스가 얼마나 빠르고 똑똑하게 동작하는지, 그 열쇠는 바로 '병렬 처리와 확장성'입니다. 오늘은 그 최전선에서 ClickHouse가 겪은 심각한 병목들을 어떻게 AI 시대에 맞는 초고코어 환경에 최적화했는지, 재미있게 알려드릴게요. 처음부터 끝까지 읽고 나면, 고성능 데이터베이스 운영의 필수 원리를 한눈에 배울 수 있습니다.
초고코어 서버에서의 ClickHouse: AI와 병렬 처리의 기대와 현실
AI, 인공지능 시스템은 상상할 수 없을 만큼 많은 데이터와 연산을 요구합니다. 인텔 최신 서버 프로세서는 코어 수를 128에서 288, 나아가 400개 이상까지 확장시켰습니다. 더 많은 코어, 즉 더 많은 동시 처리 능력이 생겨나면서 이론적으로 처리량이 폭증해야 하지만 현실은 다릅니다.
정말 많은 코어가 주는 기회는 엄청나지만, 병목 현상 역시 기하급수적으로 늘어났죠. 대표적으로 잠금(Lock) 경쟁, 메모리 대역폭 한계, 캐시 일관성 문제, 쓰레드 동기화 오버헤드, NUMA(비균일 메모리 접근) 등의 덫에 걸리면 시스템 전체가 늦어집니다. ClickHouse의 미션은 이러한 장애물을 똑똑하게 피하면서, 코어 수가 늘어날수록 성능이 거의 선형적으로 확장되도록 만드는 것이었습니다.
1. 락 경쟁 극복: 다중 쓰레드 동기화의 혁신
초고코어 환경에서 가장 먼저 풀어야 할 난제는 바로 '락 경쟁(lock contention)'입니다. 8코어에서 80코어로 늘어나면, 락 때문에 생기는 대기 시간이 100배나 늘어날 수 있죠.
무엇이 문제였을까요? ClickHouse의 쿼리 캐시처럼, 여러 쓰레드가 데이터에 접근해 읽고 쓰는 곳에서 모든 작업이 '독점 락'을 썼던 것. 즉, 읽기만 할 때도 쓰기와 동일하게 쓰레드가 기다리면서 전체 성능이 크게 떨어졌습니다.
그 해법은 바로 '더블 체크 락킹(double-checked locking)'과 '원자적(atomic) 공유'입니다. 먼저, 업데이트가 필요한지 읽기 락만으로 빠르게 체크, 그리고 정말로 필요할 때만 짧은 기간 독점 락을 잡아 수정합니다. 덕분에 CPU 사용률은 76%에서 1%로 확 떨어졌고, 특정 쿼리의 성능이 89%나 향상되었습니다.
이뿐만 아닙니다. 전역 공유 데이터를 없애고, '쓰레드 지역 변수(thread-local)'로 바꾼 프로파일러 타이머 관리도 효과적이었습니다. 각 쓰레드가 자신만의 타이머 ID를 갖게 하면서 글로벌 락이 필요 없는 구조로 개선, 초고코어 환경에서의 성능 저하를 완벽히 차단했습니다.
2. 메모리 최적화: 대용량 해시 테이블과 효율적 재사용
AI분석은 엄청난 데이터를 쏟아붓고, 이걸 잡아내는 해시 테이블도 메모리를 무지막지하게 씁니다. 하지만 기존 메모리 관리자는 크고 작은 조각들을 쓸데없이 낭비하거나, 중복 계산으로 지쳐버리곤 했습니다.
ClickHouse는 해시 테이블의 256개 버킷 구조에 맞춰 메모리 할당자의 내부 재사용 정책(jemalloc)을 근본적으로 튜닝했습니다. 덕분에 거대 해시 테이블을 해제한 뒤 바로 다시 필요한 크기로 재사용할 수 있게 되어, 페이지 폴트와 실제 메모리 사용량이 거의 절반으로 줄었습니다.
또한, 반복적으로 불필요한 연산을 하던 쿼리를 '수식 변형'(예: sum(column+literal) → sum(column)+count(column)*literal)으로 바꿔, 메모리 소모는 물론 CPU 사용량도 대폭 개선했죠. 실제로 한 쿼리의 속도가 11배나 빨라졌습니다.
3. 병렬성과 해시 테이블 병합: 직렬의 벽을 부수다
초고성능 데이터 분석에서, 병렬 처리의 핵심은 '결과 합치기(merge)' 단계입니다. 여러 쓰레드가 힘껏 계산한 부분 결과를 하나로 합치는 과정인데, 병렬이 잘 안 되면 오히려 느려집니다.
ClickHouse는 해시 테이블 병합 과정을 기존의 직렬 방식에서 적극적으로 병렬 처리로 개선했습니다.
 이미지 출처: clickhouse
이미지 출처: clickhouse
{kind=link}
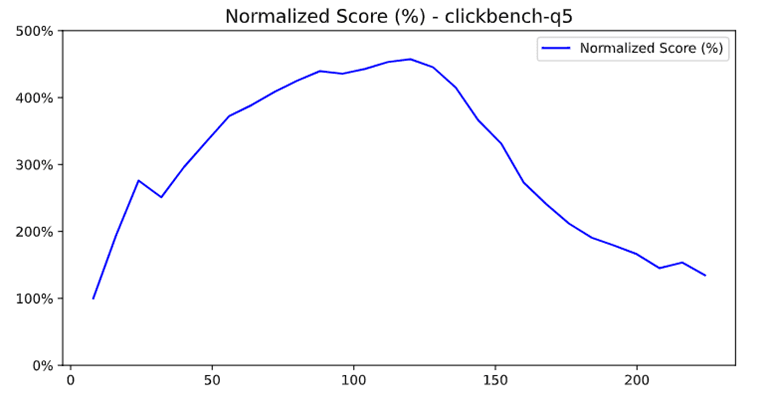
코어 수가 늘면서, 병합 단계의 성능 저하가 급증하던 기존 구조
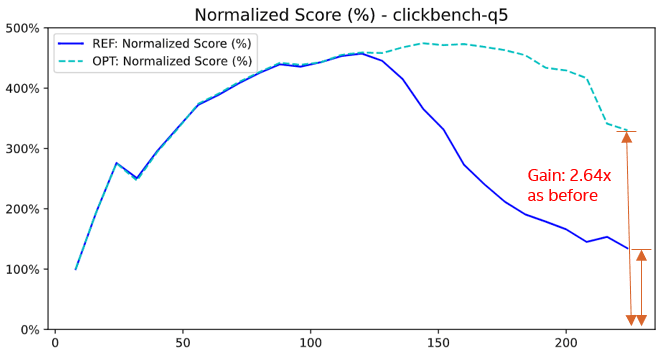
효율적으로 병합하려면, 단일 레벨 해시 테이블을 256버킷 구조의 이중 레벨로 빠르게 변환한 뒤 병렬로 합치는 알고리즘을 손봤습니다. 각 해시 테이블의 변환과 병합을 쓰레드마다 분산해 동시에 실행한 결과, 쿼리에 따라 최대 264%까지 성능이 개선되는 효과를 거뒀어요.
 이미지 출처: clickhouse
이미지 출처: clickhouse
{kind=link}
병렬 병합 및 변환 최적화 후 264% 성능 개선을 달성한 Q5 쿼리 결과
뿐만 아니라, 모든 해시 테이블이 단일 레벨일 때도 크기가 충분히 크면 병렬로 병합하도록 지능적으로 기준을 잡았습니다. GROUP BY 같은 복잡한 키 기반 병합에도 병렬 처리 원리를 적용, 넉넉한 CPU 활용으로 전체적인 응답 속도를 획기적으로 올렸죠.
4. AI 시대의 알고리즘: SIMD로 문자열 검색 가속화
빅데이터 분석에서 AI와 인공지능 관련 쿼리, 특히 URL이나 텍스트 필터링이 엄청 많이 일어납니다. 여기에 ClickHouse는 'SIMD(일괄 데이터 처리 명령어)'를 똑똑하게 사용해, 평범한 코어가 16개씩 한 번에 데이터 비교를 하도록 구조를 새로 짰어요.
바로 '이중 문자 필터링(two-character filter)'입니다. 기존엔 검색 패턴의 첫 글자만 SIMD로 필터링했기에, 검증해야 할 후보가 너무 많아 느렸습니다. 이제는 두 글자를 동시에 비교해서 불필요한 '가짜 후보'를 획기적으로 줄였죠.
 이미지 출처: clickhouse
이미지 출처: clickhouse
{kind=link}
빠르고 선택적인 SIMD 기반 문자열 검색의 영향 (쿼리 성능 향상)
실제로 LIKE '%google%' 와 같은 쿼리가 35% 더 빨라졌고, 문자열 검색 쿼리 전체가 평균 10% 이상 최적화되었습니다. 작은 변경이지만 AI 시대 분석에서 대량의 텍스트 필터링을 효율적으로 처리하는데 큰 차이를 만들었습니다.
5. 허위 공유(Fake Sharing) 방지: 캐시 라인 맞춤으로 끝없는 동시성
초고코어 서버에서 '허위 공유(false sharing)'은 작은 변수 하나가 전체 시스템에 영향을 미치는 무서운 현상입니다. 여러 쓰레드가 아주 가까운 메모리(캐시 라인) 안의 변수에 동시에 접근하면, CPU는 메모리 일관성을 유지하려고 전체 라인을 빈번히 동기화하며 속도가 느려집니다.
ClickHouse는 이벤트 프로파일링 카운터(각종 통계 변수)를 각각 64바이트 캐시 라인 단위로 정렬, 각 쓰레드가 완전히 독립적으로 변수에 접근할 수 있게 만들었습니다.
 이미지 출처: clickhouse
이미지 출처: clickhouse
{kind=link}
프로파일 이벤트 인크리먼트에서 캐시 라인 경합이 발생한 부분의 분석 결과
그 결과, 카운터 증가 연산에서만 36%에 달하던 CPU 낭비가 거의 사라졌고, 전체 시스템의 응답성과 동시성이 대폭 향상됐습니다.
데이터베이스 확장성과 AI 시대 실용 팁 한눈에 정리
인텔 280코어 서버에서의 ClickHouse 경험은 단순히 코어를 많이 쓰는 것 이상이었습니다. 락 경쟁 완화, 메모리 재사용, 병렬 병합 알고리즘, SIMD를 이용한 알고리즘 개선, 캐시 라인 정렬 등. 각각의 최적화가 AI·인공지능 분야를 위한 데이터 분석의 필수 기술이 되어가고 있죠.
실전에서 여러분이 배우고 적용할 수 있는 핵심 원리는 이렇습니다:
읽기 많은 데이터는 반드시 '락 대체'를 고민해라
메모리 재사용 여부가 대규모 분석의 성패를 좌우한다
병렬 처리에서 직렬 병합은 최대의 적이다
SIMD 같은 CPU 명령어는 알고리즘 자체를 변경해야 효용이 크다
캐시 라인 정렬만으로도 시스템 전체 성능을 바꿀 수 있다
AI 시스템을 제대로, 빠르게 구축하고 싶은 분이라면 꼭 기억하세요. 코어 개수만 늘어난 시스템에서도 데이터 엔진의 병목을 똑똑하게 뿌리뽑는 것이 곧 성공의 열쇠입니다!
참고
[1] Optimizing ClickHouse for Intel's ultra-high core count processors - ClickHouse 공식 블로그
이미지 출처
이미지 출처: Andrey Matveev on Pexels