
MiniMax-01: 긴 컨텍스트 처리에 탁월한 최신 오픈 소스 AI 모델 시리즈 (456B)
MiniMax-01
미니맥스-01(MiniMax-01)은 미니맥스(MiniMax) 연구팀이 개발한 최신 오픈 소스 모델 시리즈로, MiniMax-Text-01과 MiniMax-VL-01 두 가지 모델을 포함하고 있습니다. 이 모델은 텍스트 및 비주얼 언어 모델링 분야에서 새로운 기준을 세우며, 극한의 컨텍스트 길이를 처리할 수 있도록 설계되었습니다.
개요
MiniMax-01 시리즈는 혁신적인 구조와 새롭게 도입된 'Lightning Attention' 메커니즘을 통해 경쟁 모델보다 훨씬 더 긴 컨텍스트를 처리하는 능력을 갖추고 있습니다. 이 시리즈는 단일 입력으로 최대 400만 토큰의 컨텍스트를 처리할 수 있으며, GPT-4o에 비해 32배, Claude-3.5-Sonnet에 비해 20배 더 긴 컨텍스트를 지원합니다. 또한, 이모델은 Visual Language Task에서도 강력한 성능을 보여줍니다.
모델 구조
MiniMax-Text-01
MiniMax-Text-01은 4560억 개의 전체 파라미터를 가지고 있으며, 각 토큰에 대해 459억 개의 파라미터가 활성화됩니다. 이 모델은 Lightning Attention, Softmax Attention, Mixture-of-Experts (MoE)를 통합한 하이브리드 아키텍처를 채택하여 긴 컨텍스트 길이를 지원합니다. 주요 특징은 다음과 같습니다:
총 파라미터: 4560억
활성화된 파라미터: 459억/token
층 수: 80
주의 메커니즘: 7개의 Lightning Attention 뒤 1개의 Softmax Attention 배치
주의 헤드 수: 64
주의 헤드 크기: 128
Mixture-of-Experts: 전문가 수 32, 히든 차원 9216, Top-2 라우팅 전략
MiniMax-VL-01
MiniMax-Text-01의 강력한 성능을 기반으로, MiniMax-VL-01은 뛰어난 비주얼 기능을 갖춘 멀티모달 모델입니다. 이 모델은 Vision Transformer (ViT), MLP 프로젝트, 그리고 MiniMax-Text-01 구성 요소로 이루어져 있습니다. 특징은 다음과 같습니다:
총 파라미터: 3억3000만
ViT 레이어: 24
패치 크기: 14
히든 차원: 1024
FFN 히든 차원: 4096
주의 헤드 수: 16
주의 헤드 크기: 64
성능 평가
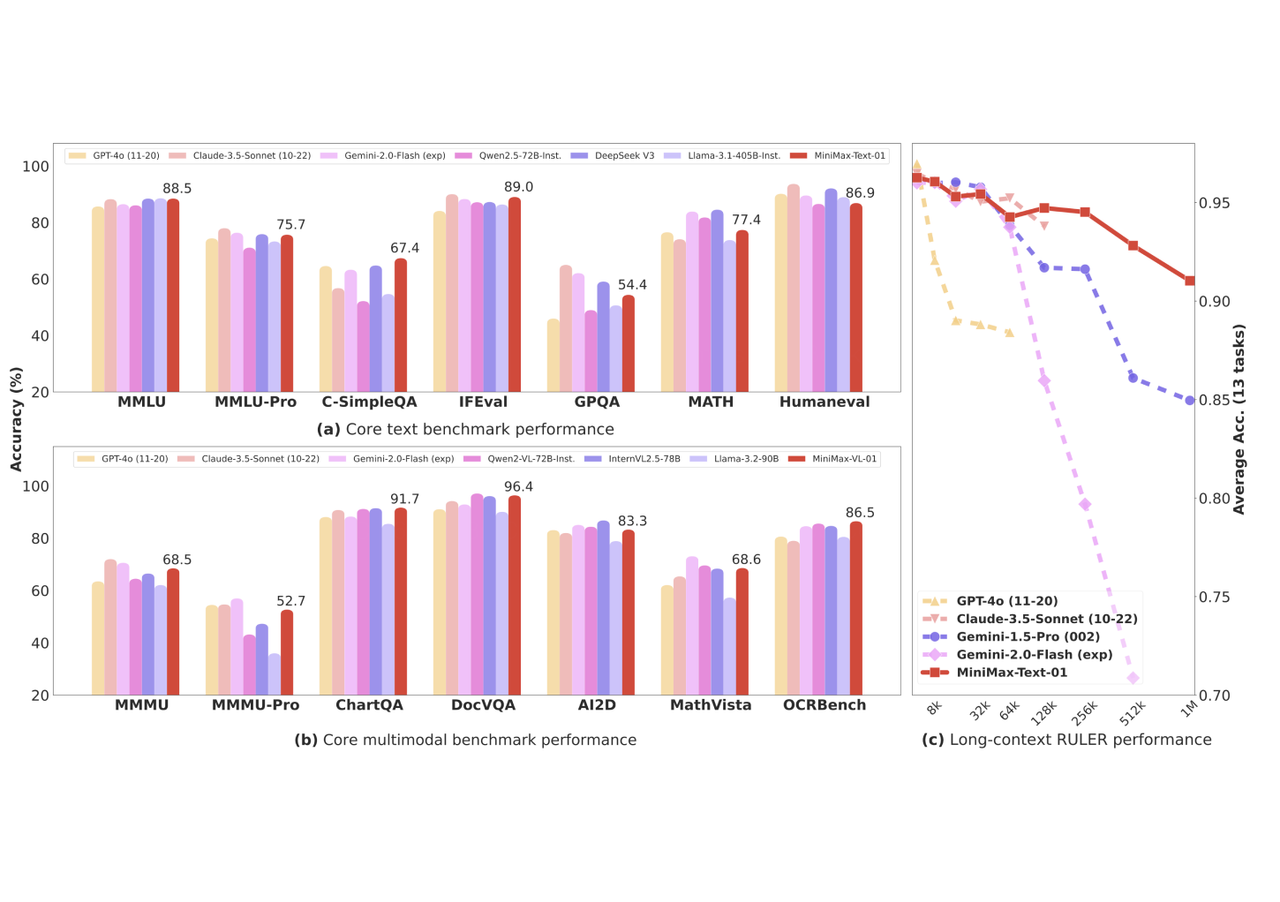
MiniMax-Text-01은 다양한 벤치마크 테스트에서 높은 성능을 보여주었습니다. 특히 GPT-4o, Claude-3.5-Sonnet 등의 선두 모델과 비교할 때 긴 문서 처리에서 성능 저하가 적었습니다. 또한, MiniMax-VL-01은 여러 멀티모달 작업에서 우수한 성능을 입증하였습니다.
텍스트 벤치마크
MMLU*: 88.5
SimpleQA: 23.7
GPT-4o: 91.2
Claude-3.5-Sonnet: 88.8
비전 벤치마크
MMMU*: 68.5
ChartQA*: 91.7
DocVQA*: 96.4
사용 방법
아래는 MiniMax-Text-01과 MiniMax-VL-01을 사용하는 예제입니다:
MiniMax-Text-01
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig, QuantoConfig, GenerationConfig
# 설정 로드
hf_config = AutoConfig.from_pretrained("MiniMaxAI/MiniMax-Text-01", trust_remote_code=True)
quantization_config = QuantoConfig(weights="int8", modules_to_not_convert=["lm_head", "embed_tokens"] + [f"model.layers.{i}.coefficient" for i in range(hf_config.num_hidden_layers)] + [f"model.layers.{i}.block_sparse_moe.gate" for i in range(hf_config.num_hidden_layers)])
# 토크나이저 로드
tokenizer = AutoTokenizer.from_pretrained("MiniMaxAI/MiniMax-Text-01")
prompt = "Hello!"
messages = [{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant created by MiniMax based on MiniMax-Text-01 model."}]}, {"role": "user", "content": [{"type": "text", "text": prompt}]}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer(text, return_tensors="pt").to("cuda")
# 모델 로드
quantized_model = AutoModelForCausalLM.from_pretrained("MiniMaxAI/MiniMax-Text-01", torch_dtype="bfloat16", device_map=device_map, quantization_config=quantization_config, trust_remote_code=True, offload_buffers=True)
# 응답 생성
generation_config = GenerationConfig(max_new_tokens=20, eos_token_id=200020, use_cache=True)
generated_ids = quantized_model.generate(**model_inputs, generation_config=generation_config)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]MiniMax-VL-01
from transformers import AutoModelForCausalLM, AutoProcessor, AutoConfig, QuantoConfig, GenerationConfig
import torch
import json
import os
from PIL import Image
# 설정 로드
hf_config = AutoConfig.from_pretrained("MiniMaxAI/MiniMax-VL-01", trust_remote_code=True)
quantization_config = QuantoConfig(weights="int8", modules_to_not_convert=["vision_tower", "image_newline", "multi_modal_projector", "lm_head", "embed_tokens"] + [f"model.layers.{i}.coefficient" for i in range(hf_config.text_config.num_hidden_layers)] + [f"model.layers.{i}.block_sparse_moe.gate" for i in range(hf_config.text_config.num_hidden_layers)])
# 프로세서 로드
processor = AutoProcessor.from_pretrained("MiniMaxAI/MiniMax-VL-01", trust_remote_code=True)
messages = [{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant created by MiniMax based on MiniMax-VL-01 model."}]}, {"role": "user", "content": [{"type": "image", "image": "placeholder"}, {"type": "text", "text": "Describe this image."}]}]
prompt = processor.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
raw_image = Image.open("figures/image.jpg")
model_inputs = processor(images=[raw_image], text=prompt, return_tensors='pt').to('cuda').to(torch.bfloat16)
# 모델 로드
quantized_model = AutoModelForCausalLM.from_pretrained("MiniMaxAI/MiniMax-VL-01", torch_dtype="bfloat16", device_map=device_map, quantization_config=quantization_config, trust_remote_code=True, offload_buffers=True)
generation_config = GenerationConfig(max_new_tokens=100, eos_token_id=200020, use_cache=True)
# 응답 생성
generated_ids = quantized_model.generate(**model_inputs, generation_config=generation_config)
response = processor.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]결론
MiniMax-01 시리즈는 새로운 차원의 텍스트 및 비전 언어 모델링을 제공합니다. 이를 통해 다양한 AI 응용 분야에서 긴 컨텍스트를 처리하는 능력이 향상되었습니다. 이러한 성능은 특히 대규모 데이터를 다루는 애플리케이션에서 유용할 것입니다. MiniMax의 모델은 GitHub 및 다양한 플랫폼에서 공개되어 있으며, 개발자와 연구자들이 손쉽게 접근하여 사용할 수 있도록 구성되었습니다.
참고
허깅페이스 : MiniMaxAI (MiniMax)
API 플랫폼 : MiniMax - Intelligence with everyone