
구글 Gemini 2.0 발표: 멀티 모달이 우리가 컴퓨터를 사용하는 방법을 완전히 바꿀지도 모릅니다.
Gemini 2.0 발표
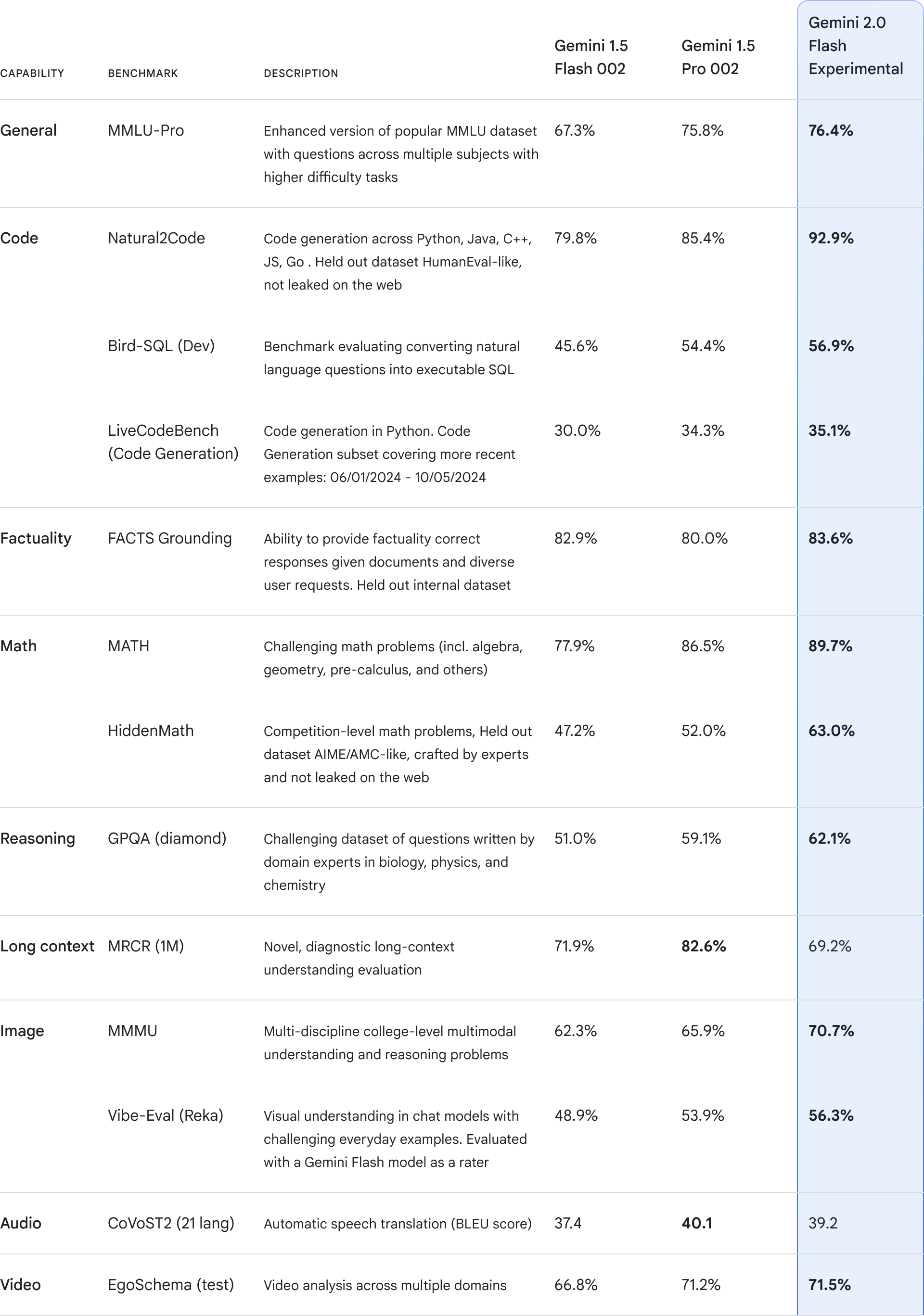
구글의 Gemini 2.0 이 발표되었습니다. 이 새로운 버전은 멀티 모달 능력이 크게 향상되었습니다. 텍스트, 이미지, 비디오, 오디오를 인풋과 아웃풋으로 처리할 수 있습니다. 처리하면서 이미지를 생성하고 다양한 언어의 목소리도 생성할 수 있습니다.
Gemini 2.0 플래시 버전은 지금 바로 사용이 가능합니다. 플래시는 이전 유료 요금제에서 사용가능했던 1.5 프로보다 성능이 좋다고 하네요. 그리고 속도는 2배가 빠르다고 합니다. 컨텍스트 리밋은 1백만 토큰입니다.
출처 : Introducing Gemini 2.0: our new AI model for the agentic era
새로운 기능
Gemini 2.0은 새로운 기능들을 가지고 있습니다. 다음과 같은 기능이 있습니다:
여러 형태의 출력: Native 이미지 출력과 Native 음성 출력을 포함 (기존에서 개선된 기능으로 향후 지원 예정) 합니다.
Native image generation : 텍스트로 이미지를 생성하거나 변경이 가능함.
이미지를 그대로 유지하면서 텍스트로 프롬프트로 변경이 가능함. (초기 테스터들에게 제공)
Native text-to-speech : 제미나이의 말하기 스타일을 조절 가능 (다양한 언어로 이야기할 수 있음.)
Native tool use : (도구의 자연스러운 사용) : Google 검색과 지도 사용이 가능합니다.
코드 실행 모드 지원: Python 코드 작성·실행으로 결과 반영 가능 (단, 외부 네트워크 접근 불가)
실시간 데모 제공 : AI Studio, 웹 콘솔 등을 통한 음성·영상 기반 실험 가능
Multimodal live api : audio, video 실시간 스트리밍 인풋 및 아웃풋 지원. 인풋은 다국어 오디오 지원.
aistudio.google.com 에서 사용해 볼 수 있음.
실험적 버전: Gemini 2.0 Flash
구글은 Gemini 2.0 Flash의 실험적 버전을 출시합니다. 이 모델은 지연시간이 낮고 성능이 향상되었습니다. 개발자들은 Google AI Studio와 Vertex AI를 통해 Gemini API로 이 모델을 사용하여 개발을 시작할 수 있습니다. Gemini와 Gemini Advanced 사용자들은 데스크탑에서 모델 드롭다운을 선택하여 Gemini 2.0의 채팅 최적화 버전을 시도할 수 있습니다.
새로운 연구 프로토타입
구글은 Gemini 2.0을 새로운 연구 프로토타입에서도 사용하고 있습니다.
Project Astra : 범용 AI 어시스턴트입니다. 시각적 인식 시스템으로, 물체를 식별하고, 사용자에게 위치 정보를 제공하며, 다국어 대화 기능을 지원합니다.
대기자리스트 : https://docs.google.com/forms/d/e/1FAIpQLScCrFFCFcZ9q_0Ti_a-qkh56W26lysgcArpNiaDDQ8DngG9eg/viewform
Project Mariner : 초기 프로토타입으로 Chrome에서 동작을 수행할 수 있는 실험적 확장 프로그램입니다. 크롬 확장 프로그램으로 웹 브라우저를 자동으로 제어할 수 있습니다.
대기자 리스트 : https://docs.google.com/forms/d/e/1FAIpQLSe2J4BvD48E-57giEiXIDz_yZeqGmX0Q3AvvR_LfzpRat2kGQ/viewform
Jules (줄스): 실험적인 AI 기반 코드 에이전트입니다. 개발자를 위해 GitHub 워크플로우와 통합하여 코드 문제를 탐지하고 수정합니다. 참고
Deep Research: 고급 검색과 종합 보고서 생성을 지원합니다. (유료 요금제)
미래는 에이전트.