12일간의 OpenAI 제품 발표 2일차 - o1 mini 를 활용한 reinforcement finetuning 모델 발표.
o1 mini 를 활용한 reinforcement finetuning 모델 발표.
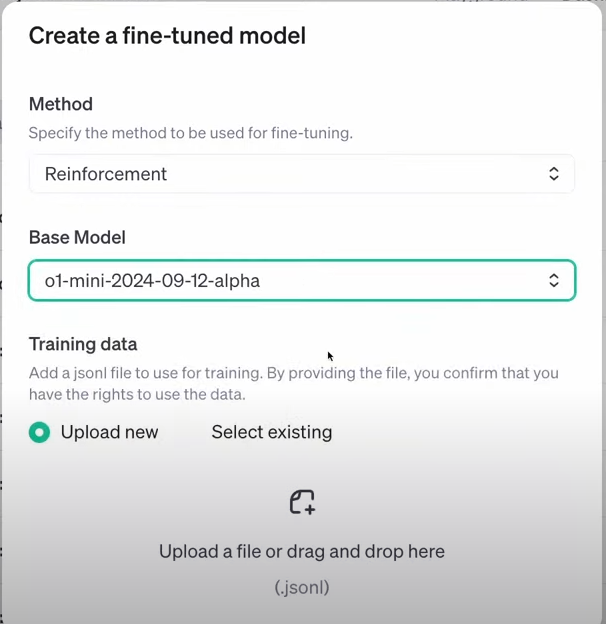
새로운 모델 맞춤화 프로그램은 사용자가 직접 데이터 세트를 사용해 o1 모델을 강화 학습 조정(RFT)할 수 있게 함.
RFT는 단순한 미세 조정이 아닌 강화 학습 알고리즘을 활용해 모델의 사고 능력을 향상시킴.
커스터마이즈된 모델은 법률, 금융, 공학, 보험 등 다양한 분야의 특정 작업에서 뛰어난 성능을 발휘할 수 있음.
예를 들어, Thomson Reuters와 협력해 법률 보조사로서의 o1 mini를 강화 학습 조정함.
기존의 지도 학습 미세 조정과는 달리 강화 학습 조정은 전혀 새로운 방식을 학습하게 하며, 적은 예제로도 효과적으로 학습함.
OpenAI의 최신 Frontier 모델 훈련에도 사용된 방법으로, 과학 연구 등 여러 분야에서 큰 잠재력을 가짐.
베르클리 연구소의 연구원 Justin Ree가 희귀 유전병 연구에 강화 학습 조정을 적용한 사례를 소개함.
환자의 증상 목록을 기반으로 유전자 변이를 예측하는 모델을 통해 성과가 향상됨을 보여줌.

강화 학습 조정의 작동 원리와 데이터 셋, 평가지 등을 설명하며 실제 사례를 시연함.
강화 학습 조정의 원리는 모델이 문제를 보고 문제를 생각할 시간을 주는 것입니다. 모델이 최종 답을 내놓으면, 강화 학습 알고리즘을 사용해 올바른 답을 이끌어낸 사고 과정을 강화하고, 잘못된 답을 이끌어낸 사고 과정을 비선호합니다. 이렇게 하여 모델이 소수의 예제로도 새로운 방식으로 추론을 배우도록 합니다.
Grader는 모델의 출력 결과를 평가하는 도구로, 모델의 출력과 정답을 비교하여 0에서 1 사이의 점수를 반환합니다. 0은 모델이 전혀 맞추지 못했음을, 1은 모델이 완전히 맞췄음을 의미하며, 부분 점수도 가능합니다. Grader는 모델의 정확도를 평가하고, 모델이 학습하는 동안 피드백을 제공하는 데 사용됩니다.
프로그램 실행 및 모델 평가 결과, 강화 학습 조정이 모델의 성능을 크게 향상시킴.
이제 더 많은 연구자와 조직이 프로그램에 참여할 수 있도록 알파 프로그램을 확장함.
프로그램의 의도는 복잡한 작업을 수행하는 전문가 팀에게 AI 지원을 제공하는 것임.
프로그램에 참여하려는 신청을 받고 있으며, 내년 초에는 이를 대중에 공개할 계획임.
사실은 강화학습의 미세 조정 플랫폼이 나올 것이라고 생각했는데 이렇게 나올 줄은 몰랐어요.
정형화된 강화학습은 아니지만 예제 열 몇개 정도로도 잘 학습하는 모델을 만들 수 있다고 합니다.
만약 강화 학습을 제대로 파인튜닝할 수 있는 플랫폼이 나온다면 세계를 지배할지도...