
파이토치로 인공신경망 만들기 (how to make neural network)
PyTorch로 간단한 신경망 만들기 (MLP - Multilayer Perceptron 예제)
일단 인공 신경망을 배워야 하는 이유는 지금 모든 AI 의 핵심이기 때문이다.
LLM은 인공 신경망의 한 종류일 뿐이다. (강력하기는 하지만...ㅋㅋ)
인공신경망은 입력값과 출력값의 데이터 셋이 있으면 모든 종류의 패턴을 학습할 수 있다.
오늘은 이 인공신경망을 만들고 활용하면서 이해해 보자.
신경망을 쉽게 쓸 수 있게 만들어 놓은 파이토치를 사용해서 진행해 보자.
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 데이터 생성
num_samples = 100
x_train = torch.rand(num_samples, 2) * 10
y_train = (x_train.sum(dim=1) >= 5).float().unsqueeze(1)
x_test = torch.rand(20, 2) * 10
y_test = (x_test.sum(dim=1) >= 5).float().unsqueeze(1)
# 2. 모델 정의
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(2, 8)
self.fc2 = nn.Linear(8, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.sigmoid(self.fc2(x))
return x
model = SimpleNN()
# 3. 손실 함수와 옵티마이저
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 4. 학습
epochs = 20
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(x_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}")
# 5. 평가
model.eval()
with torch.no_grad():
predictions = model(x_test)
predictions = (predictions > 0.5).float()
accuracy = (predictions == y_test).sum() / y_test.size(0)
print(f"Test Accuracy: {accuracy:.4f}")파이토치가 깔려 있지 않다면 pip install pytorch
x_train 에 입력 데이터를 만들어 주고 y_train 에 결과 데이터를 만들어 준다. 두 데이터의 합이 5 이상이면 1, 5미만이면 0을 출력하는 간단한 인공 신경망을 만들어 보자.
num_samples = 100
x_train = torch.rand(num_samples, 2) * 10
y_train = (x_train.sum(dim=1) >= 5).float().unsqueeze(1)
x_test = torch.rand(20, 2) * 10
y_test = (x_test.sum(dim=1) >= 5).float().unsqueeze(1)나중에 모델이 나왔을 때 테스트해서 정확도를 측정하기 위해 test 셋도 만들어 준다.
그 다음에 모델을 정의해 준다.
# 2. 모델 정의
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(2, 8)
self.fc2 = nn.Linear(8, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.sigmoid(self.fc2(x))
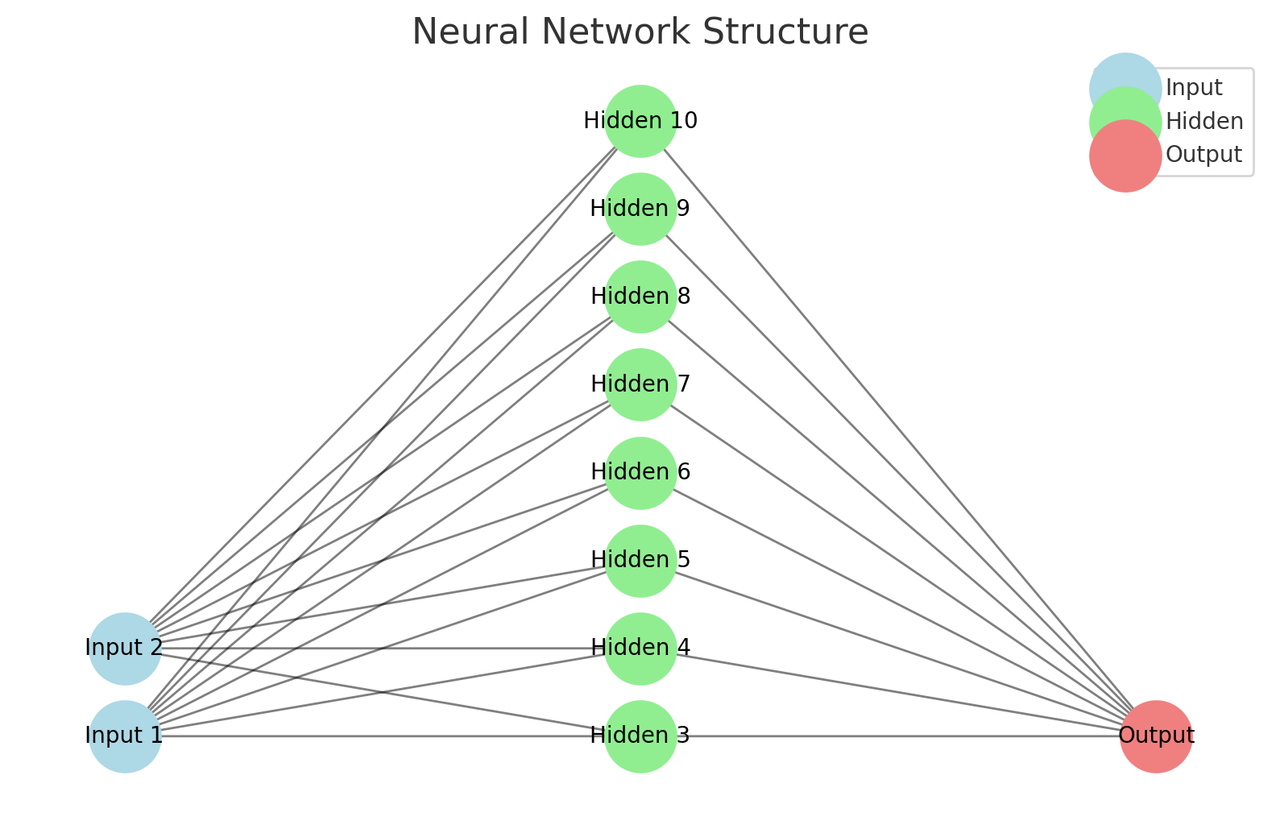
return x입력 값은 2이고, 두번째 층에서는 8개의 은닉층을 가진다. 마지막으로 1개의 출력 값을 내보낸다.
즉 숫자 2개를 넣으면 그 합이 5이상인지 미만인지 파악을 해주는 간단한 인공 신경망이다.
forward 함수는 다음 층으로 이동할 때 처리를 하는 함수이다.
relu 는 가중치를 곱하고 더한 후 bias 를 더한 값이 0보다 작으면 0을 출력하고 이보다 크면 그대로 출력하는 방식이다.
sigmoid 는 0~1 사이의 값을 출력해서 확률값처럼 사용할 수 있다.
model = SimpleNN()
# 3. 손실 함수와 옵티마이저
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)모델을 로드하고 손실함수와 옵티마이저를 세팅해준다. 옵티마이저는 Adam 을 활용했다.
# 4. 학습
epochs = 20
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(x_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}")실제로 학습을 하는 부분이다.
20번의 배치를 돈다. 모델에 x_train 값을 넣고 손실을 측정한 후 역전파 알고리즘으로 가중치를 조정해준다.
이 가중치가 신경망이 학습하는 핵심 요소이다.
단순 선형 모델을 생각해 보자.
y=w1⋅x1+w2⋅x2+b
w가 가중치이고 x가 입력 데이터이다. b는 bias를 각 뉴런의 결과값에 추가적으로 더해지는 값이다.
이렇게 해서 하나의 굉장히 큰 식이 나오게 되고 이것이 우리가 말하는 인공 지능 모델이 된다.
(여기에서 매개 변수의 수는 가중치와 바이어스 개수를 모두 더한 값이 된다.)
위의 코드는 위와 같은 식의 인공 신경망이 된다.
input 1과 2에 1.0 과 3.0의 값을 입력하는 예시를 생각해 보자.
먼저 인공 신경망이 이 값을 처리한다. 그 후 답을 보여줘서 역전파 알고리즘과 옵티마이저로 가중치와 바이어스를 조정한다.
그 다음 데이터를 넣고 이 과정을 반복하면서 가중치와 바이어스를 조정한다.
이렇게 해서 하나의 모델이 나오게 된다.
이제 학습한 모델을 평가하고 새로운 데이터셋으로 사용까지 해보자.
# 5. 평가
model.eval()
with torch.no_grad():
predictions = model(x_test)
predictions = (predictions > 0.5).float()
accuracy = (predictions == y_test).sum() / y_test.size(0)
print(f"Test Accuracy: {accuracy:.4f}")
# 새로운 데이터 입력
new_data = torch.tensor([[1.0, 10.0]]) # 입력 데이터는 2개의 숫자로 이루어져야 함
# 모델 예측
model.eval() # 평가 모드
with torch.no_grad(): # 학습 비활성화
prediction = model(new_data) # 모델에 입력 데이터 전달
prediction_class = (prediction > 0.5).float() # 0.5 이상이면 1, 아니면 0
print(
f"Input: {new_data.tolist()}, Prediction: {prediction.item():.4f}, Class: {int(prediction_class.item())}"
)Test Accuracy: 0.9500
Input: [[1.0, 10.0]], Prediction: 0.9940, Class: 1
이런 식으로 테스트 정확도가 95%가 나왔고,
1.0과 10.0을 입력했을 때 1로 합이 5보다 크다는 결과가 나왔다.
이게 인공 신경망이다.
이 모델을 사용해서 이제 데이터를 처리할 수 있다.
예를 들어 1.0과 3.0을 입력했다.
위의 인공 신경망 그림에서 각 선은 가중치이고 이를 곱한다. 두번째 층에서 각 값을 합한 후 바이어스를 더한다.
0보다 작으면 0을 출력하고 0보다 크면 그대로 나간다. (relu)
이와 같은 방식으로 진행해서 마지막 출력이 0인지 1인지를 본다.
이렇게 해서 각 입력값들의 합이 5보다 작은지 큰지 알 수 있는 것이다.
마지막 코드로는 모델을 저장하고 불러온 후 가중치를 출력까지 해보자.
# 모델 저장
torch.save(model.state_dict(), "model.pth")
# 모델 불러오기
model = SimpleNN()
model.load_state_dict(torch.load("model.pth"))
# 가중치와 편향 출력
print(model.state_dict())이렇게 나온다.
OrderedDict({
'fc1.weight':
tensor([[-0.6229, 0.1654],
[-0.4121, 0.0796],
[ 0.8066, 0.6311],
[-0.4425, -0.4426],
[-0.2636, 0.8107],
[ 0.4037, -0.4993],
[-0.2698, -0.0083],
[ 0.4120, -0.3938]]),
'fc1.bias':
tensor([-0.6044, 0.4252, -0.5025, 0.4929, 0.2736, 0.4973, -0.4285, 0.5349]),
'fc2.weight': tensor([[-0.1019, -0.2412, 0.1628, 0.2304, 0.4744, 0.0496, -04, 0.4744, 0.0496, -0.0103, 0.4446]]),
'fc2.bias': tensor([0.4292])})예를 들어 1.0과 3.0을 입력했을 때 [1.0, 3.0]
첫번째 레이어의 첫번째 뉴런은 1.0*-0.6229+3.0*0.1654-0.6044 = −0.7311 이 되고 ReLU에 의해서 0이 된다.
이런 식으로 쭈욱 계산이 되어 마지막 출력에 0 또는 1이 나온다.
이게 chatgpt, 테슬라 자동운전 등 모든 인공 신경망에 쓰이는 원리이다.
다른 데이터 적용
간단한 문자 데이터 처리 예제
문장을 입력받아 긍정(1)인지 부정(0)인지 예측하는 신경망
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.feature_extraction.text import CountVectorizer
# 데이터 준비
texts = ["I love this", "This is bad", "I hate it", "So good", "Really bad"]
labels = [1, 0, 0, 1, 0] # 긍정: 1, 부정: 0
# 텍스트를 숫자로 변환 (원-핫 인코딩 유사 방식)
vectorizer = CountVectorizer() # 단어 빈도 기반 벡터화
X = vectorizer.fit_transform(texts).toarray() # 텍스트 → 숫자
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(labels, dtype=torch.float32).unsqueeze(1)
# 간단한 신경망 정의
class SimpleNN(nn.Module):
def __init__(self, input_size):
super(SimpleNN, self).__init__()
self.fc = nn.Linear(input_size, 1) # 입력 크기 → 출력 1개
self.sigmoid = nn.Sigmoid() # 활성화 함수
def forward(self, x):
x = self.fc(x)
return self.sigmoid(x)
# 모델 초기화
model = SimpleNN(input_size=X.size(1))
# 손실 함수와 옵티마이저
criterion = nn.BCELoss() # 이진 크로스엔트로피 손실
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 학습
for epoch in range(100):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
# 예측
new_texts = ["I love it", "Really hate this"]
new_X = vectorizer.transform(new_texts).toarray() # 텍스트 → 숫자
new_X = torch.tensor(new_X, dtype=torch.float32)
predictions = model(new_X)
print(predictions)이런 식으로 다양한 데이터를 처리할 수 있다.
이미지
이미지의 경우 픽셀 값으로 이미 숫자로 표현되어 있다. 이를 0과 1사이로 정규화한 후 CNN (합성곱 신경망을) 사용해 처리하면 된다.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 데이터셋 로드 및 전처리
transform = transforms.Compose([
transforms.ToTensor(), # 이미지를 텐서로 변환
transforms.Normalize((0.5,), (0.5,)) # 정규화
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
# 간단한 CNN 정의
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 합성곱 레이어
self.fc1 = nn.Linear(32 * 26 * 26, 10) # 완전 연결 레이어
def forward(self, x):
x = torch.relu(self.conv1(x)) # 합성곱 + ReLU
x = x.view(x.size(0), -1) # Flatten
x = self.fc1(x) # 완전 연결 레이어
return x
# 모델 초기화
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 학습
for epoch in range(1):
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print("Training Complete!")CNN은 이미지나 시각 데이터에서 패턴을 자동으로 찾아내는 신경망이다. 예를 들어, 고양이 사진을 입력받으면 고양이의 모양, 귀, 눈 같은 특징을 인식해서 "고양이"인지 판단할 수 있다.
시사점
인공 신경망은 입력과 출력의 데이터셋을 준비할 수 있는 모든 데이터의 패턴을 학습할 수 있다.
내가 자주 쓰는 작업들을 학습시킬 수 도 있고 chatgpt 처럼 거대한 언어 모델을 학습할 수 도 있다.
이것이 우리의 삶을 변화시킬까? 아마 거의 모든 것이 바뀌지 않을까.