Aider 벤치마크 LLM 순위: 코드 편집 및 리팩토링 성능 비교 분석
Aider 벤치마크
에이더 벤치마크는 aider 라는 코드 편집 도구에서의 LLM 모델들의 코딩 성능을 측정한 지표이다. 꽤 유명한 벤치마크이다.
코드 에디팅 리더보드
Aider의 코드 편집 벤치마크는 LLM(대형 언어 모델)에게 파이썬 소스 파일을 편집하게 해서 133개의 작은 코딩 연습 문제를 완료하게 한다.
이는 LLM의 코딩 능력과 기존 코드에 새 코드를 통합할 수 있는지를 측정한다.
모델은 모든 변경 사항을 사람의 개입 없이 소스 파일에 성공적으로 적용해야 한다.
| Model | Percent completed correctly | Percent using correct edit format | Command | Edit format |
|---|---|---|---|---|
| claude-3-5-sonnet-20241022 | 84.2% | 99.2% | aider --model anthropic/claude-3-5-sonnet-20241022 | diff |
| o1-preview | 79.7% | 93.2% | aider --model o1-preview | diff |
| claude-3.5-sonnet-20240620 | 77.4% | 99.2% | aider --model claude-3.5-sonnet-20240620 | diff |
| claude-3-5-haiku-20241022 | 75.2% | 95.5% | aider --model anthropic/claude-3-5-haiku-20241022 | diff |
| Qwen2.5-Coder-32B-Instruct (whole) | 73.7% | 100.0% | aider --model openai/Qwen2.5-Coder-32B-Instruct | whole |
| DeepSeek Coder V2 0724 (deprecated) | 72.9% | 97.7% | aider --model deepseek/deepseek-coder | diff |
| gpt-4o-2024-05-13 | 72.9% | 96.2% | aider | diff |
| openai/chatgpt-4o-latest | 72.2% | 97.0% | aider --model openai/chatgpt-4o-latest | diff |
| DeepSeek V2.5 | 72.2% | 96.2% | aider --deepseek | diff |
| Qwen2.5-Coder-32B-Instruct (diff) | 71.4% | 94.7% | aider --model openai/Qwen2.5-Coder-32B-Instruct | diff |
| gpt-4o-2024-08-06 | 71.4% | 98.5% | aider --model openai/gpt-4o-2024-08-06 | diff |
| o1-mini (whole) | 70.7% | 90.0% | aider --model o1-mini | whole |
| DeepSeek Chat V2 0628 (deprecated) | 69.9% | 97.7% | aider --model deepseek/deepseek-chat | diff |
| Qwen2.5-Coder-14B-Instruct | 69.2% | 100.0% | aider --model openai/Qwen2.5-Coder-14B-Instruct | whole |
| claude-3-opus-20240229 | 68.4% | 100.0% | aider --opus | diff |
| gpt-4-0613 | 67.7% | 100.0% | aider -4 | diff |
여기에서 보면 claude 의 코드 편집 능력이 굉장히 좋은 것을 알 수 있다. 커서 등에서 클로드를 사용하면 능력치가 굉장히 좋아지는 원인이다. 클로드는 agentic coding 이라고 코딩을 단계별로 나눠서 수행할 수 있는 능력이 강화되었는데 이 때문이다.
그리고 o1 preview 가 2위를 차지했다.
새로 나온 qwen coder 2.5, gpt-4o의 순으로 성능이 측정되었다.
코드 리팩토링 능력
Aider 리팩토링 벤치마크
Aider의 리팩토링 벤치마크는 LLM(대형 언어 모델)에게 큰 파이썬 클래스에서 89개의 큰 메서드를 리팩토링하게 한다.
이는 더 도전적인 벤치마크로, 모델이 긴 코드 조각을 건너뛰거나 실수 없이 출력할 수 있는 능력을 테스트한다.
| Model | Percent completed correctly | Percent using correct edit format | Command | Edit format |
|---|---|---|---|---|
| claude-3-5-sonnet-20241022 | 92.1% | 91.0% | aider --sonnet | diff |
| o1-preview | 75.3% | 57.3% | aider --model o1-preview | diff |
| claude-3-opus-20240229 | 72.3% | 79.5% | aider --opus | diff |
| claude-3.5-sonnet-20240620 | 64.0% | 76.4% | aider --sonnet | diff |
| gpt-4o | 62.9% | 53.9% | aider | diff |
| gpt-4-1106-preview | 50.6% | 39.3% | aider --model gpt-4-1106-preview | udiff |
| gpt-4o-2024-08-06 | 49.4% | 89.9% | aider --model openai/gpt-4o-2024-08-06 | diff |
| gemini/gemini-1.5-pro-latest | 49.4% | 7.9% | aider --model gemini/gemini-1.5-pro-latest | diff-fenced |
| o1-mini | 44.9% | 29.2% | aider --model o1-mini | diff |
| gpt-4-turbo-2024-04-09 (udiff) | 34.1% | 30.7% | aider --gpt-4-turbo | udiff |
| gpt-4-0125-preview | 33.7% | 47.2% | aider --model gpt-4-0125-preview | udiff |
| DeepSeek Coder V2 0724 (deprecated) | 32.6% | 59.6% | aider --model deepseek/deepseek-coder | diff |
| DeepSeek Chat V2.5 | 31.5% | 67.4% | aider --deepseek | diff |
| gpt-4-turbo-2024-04-09 (diff) | 21.4% | 6.8% | aider --model gpt-4-turbo-2024-04-09 | diff |
역시 클로드가 상위에 랭크되었다.
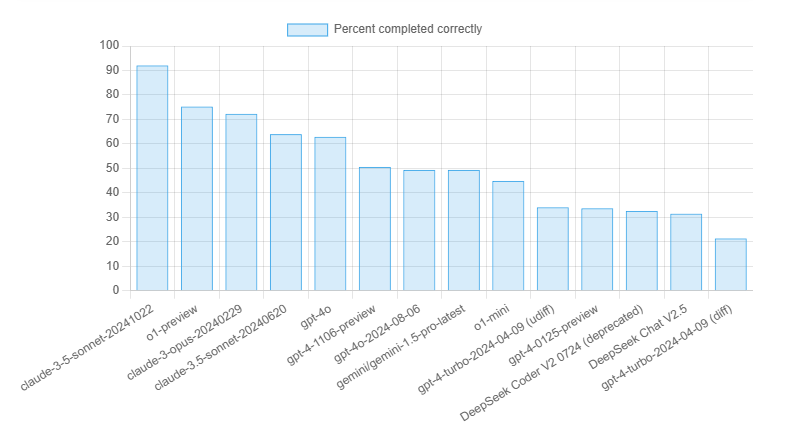
리팩토링은 많은 컨텍스트 토큰을 사용하기 때문에 여기에 포함될 수 있는 모델 수는 제한되어 있다.
diff 형식을 사용할 수 있는 모델이 더 적은 토큰을 사용하고 효율적이다.
Paul Gauthier 폴 고티에 작성, 마지막 업데이트 2024년 11월 11일.
키워드만 입력하면 나만의 학습 노트가 완성돼요.
책이나 강의 없이, AI로 위키 노트를 바로 만들어서 읽으세요.
콘텐츠를 만들 때도 사용해 보세요. AI가 리서치, 정리, 이미지까지 초안을 바로 만들어 드려요.