OpenAI o1 리서치 포스트 요약
OpenAI o1은 강화 학습을 통한 훈련을 통해 복잡한 추론을 수행하는 새로운 대형 언어 모델입니다. 이 모델은 답변을 생성하기 전에 Chain of Thought(연쇄 사고 과정)을 거치며, 이를 통해 문제 해결 능력을 크게 향상시킵니다.
강화 학습을 통해 모델의 사고 능력이 꾸준히 개선되며, 훈련 시간(train-time compute)과 사고 시간(test-time compute)의 증가에 따라 성능이 향상됩니다.
테스트 시간과 학습 시간의 증가에 따라 성능 향상.
강화 학습 알고리즘을 통해 생산적으로 생각하는 법을 학습시킨다. o1의 성능이 더 많은 강화 학습(train-time compute)과 더 많은 사고 시간(test-time compute)이 주어질수록 꾸준히 향상된다는 것을 발견.
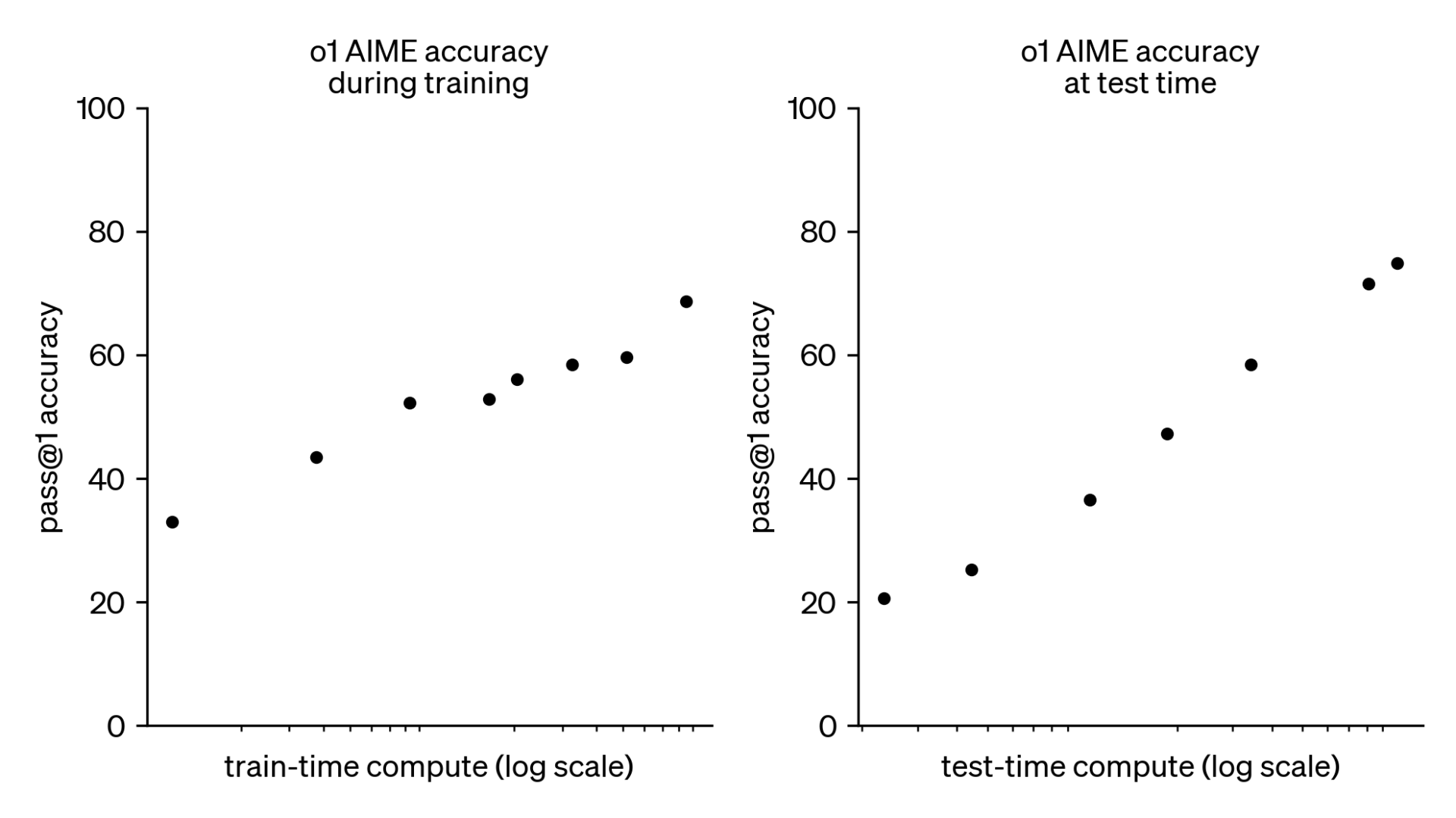
o1 의 성능이 훈련 시간과 사고 시간에 비례하여 증가하는 것을 보여주는 그래프.
주요 성과
경쟁 프로그래밍(Codeforces): o1은 89번째 백분위수 성적을 기록하며 뛰어난 프로그래밍 실력을 입증했습니다.
미국 수학 올림피아드 예선(AIME): o1은 미국 상위 500명 학생에 포함되는 성적을 달성했습니다.
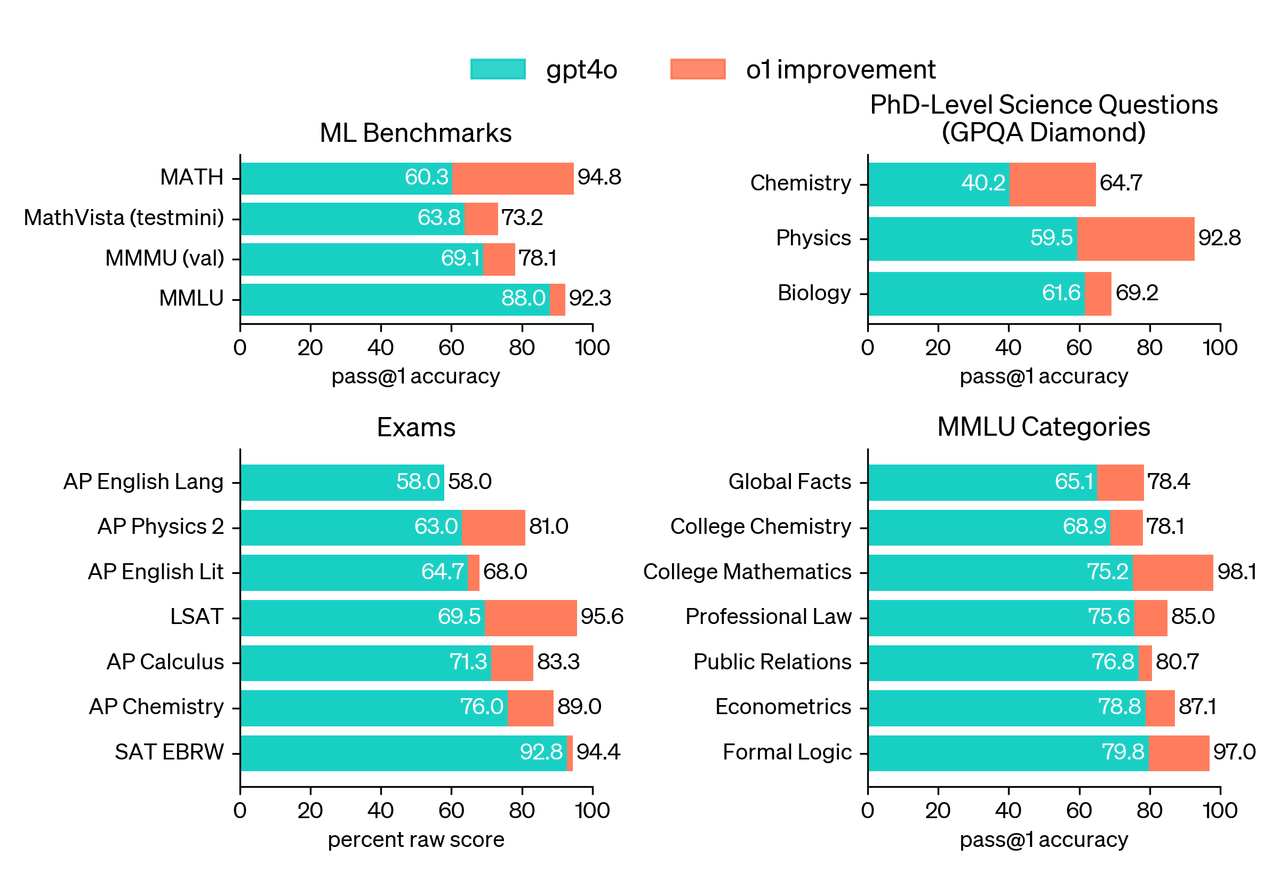
많은 추론 중심의 벤치마크에서, o1은 인간 전문가와 비슷한 성과를 보입니다. 최근의 최첨단 모델들은 MATH와 GSM8K에서 매우 뛰어난 성과를 보여, 이제는 이 벤치마크들이 모델 간의 성능을 구분하기에 효과적이지 않게 되었습니다.
우리는 미국의 뛰어난 고등학생들을 대상으로 하는 AIME 시험에서 수학 성능을 평가했습니다. 2024년 AIME 시험에서 GPT-4o는 평균적으로 12% (1.8/15)의 문제를 해결한 반면, o1은 한 문제당 단일 샘플로 74% (11.1/15)를 해결했고, 64개의 샘플에서 합의된 답변으로는 83% (12.5/15)를, 학습된 채점 함수를 통해 1000개의 샘플을 다시 평가한 결과로는 93% (13.9/15)를 해결했습니다. 13.9점은 전국 상위 500명 학생 중 하나로 선정될 수 있는 점수이며, 미국 수학 올림피아드(USA Mathematical Olympiad)의 커트라인을 넘는 성과입니다.
64개의 샘플에서 합의된 답변이라는 뜻은 64번의 시도를 한 후 그 중에서 다수의 샘플이 일치하는 답변을 선택했다는 의미이다.
학습된 채점 함수라는 것은 문제 풀이 과정에서 다양한 규칙과 패턴을 학습하여, 더 높은 품질의 답을 판별할 수 있도록 만드는 것을 의미한다. 이 채점 함수로 1000개의 샘플을 평가하여 가장 적합한 답을 도출하는 것이다. 이 과정은 강화 학습의 일환으로 볼 수 있다.
과학 문제 벤치마크: 물리, 생물학, 화학 문제에서 PhD 수준 이상의 정확도를 보였습니다.
GPQA-diamond 벤치마크: 인간 전문가를 능가하는 성과를 기록했습니다.
https://openai.com/index/learning-to-reason-with-llms/
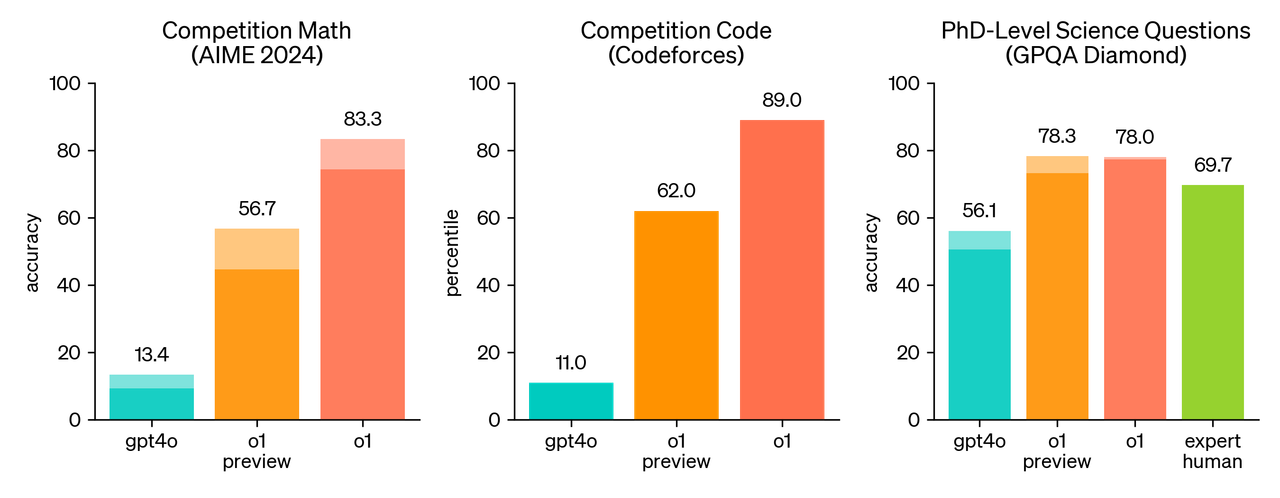
gpt-4o를 복잡한 추론 능력에서 크게 상회하는 모습. 붉은 색 o1 은 사고 시간을 최대로 잡은 것을 의미. 음영 부분은 64개의 샘플에서 합의된 답변의 퀄리티를 의미한다.
Chain of thought
사고 과정인 Chain of Thought를 강화학습을 통해 학습하여 인간의 사고 과정을 모방하는 것이다. (솔직히 이 부분에서 소름...)
o1은 Chain of Thought(COT) 방식을 학습하여 복잡한 문제에 대해 더 깊이 있는 사고 과정을 거칩니다. 이 방식은 인간의 사고를 모방하여 정확한 답변을 생성하는 데 기여합니다.
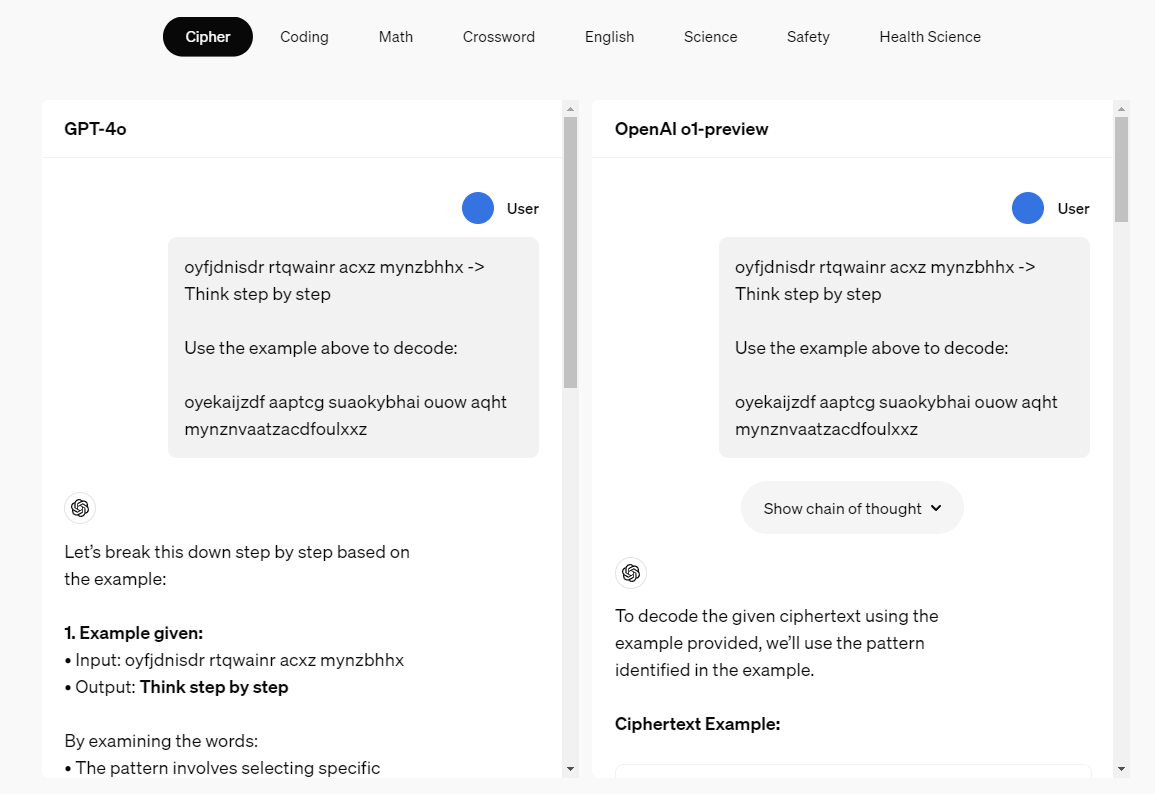
암호를 해석하는 모습.
코딩
우리는 o1을 초기 모델로 사용하여 프로그래밍 능력을 더욱 향상시키기 위해 추가 학습을 거친 모델을 훈련했습니다. 이 모델은 2024 국제 정보 올림피아드(IOI)에서 213점을 획득하여 49번째 퍼센타일에 해당하는 성적을 기록했습니다. (상위 51%로 중간 정도의 성적을 기록)이 모델은 인간 참가자들과 동일한 조건에서 2024 IOI에 참가했으며, 10시간 동안 6개의 어려운 알고리즘 문제를 풀어야 했고, 각 문제당 최대 50번의 제출 기회가 주어졌습니다.
사람의 선호도
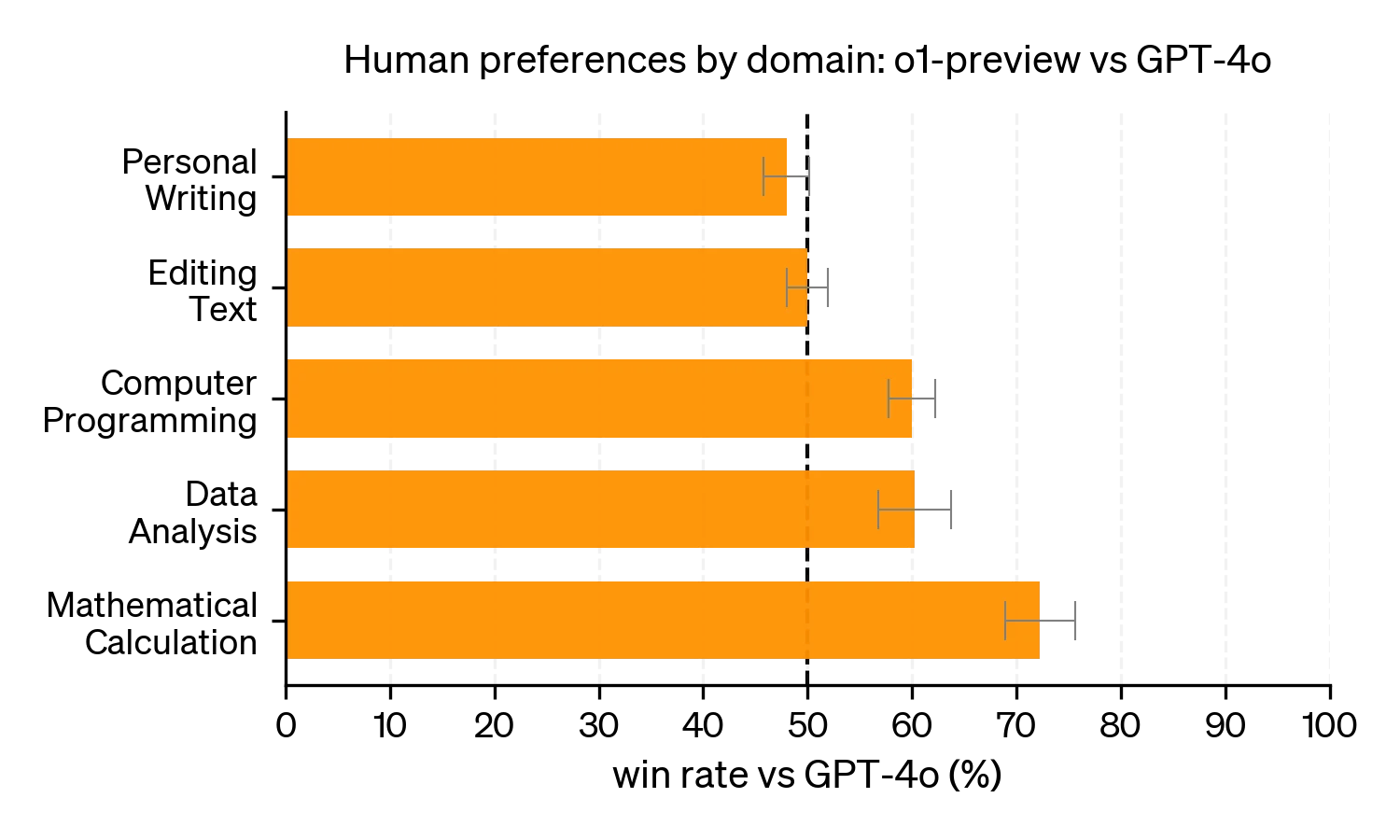
선호도 측면에서는 자연어 처리에서는 gpt-4o와 50 대 50의 승률을 보였고, 코딩, 데이터 분석, 수학 계산에서는 더 높은 승률을 보였다.
안전성
cot를 사용하여 안전성에서도 gpt-4o 보다 높은 점수를 기록했다.
사고 과정 모니터링
사용자 경험, 경쟁 우위, 그리고 사고 과정 모니터링을 추구할 수 있는 옵션을 포함한 여러 요인을 고려한 후, 우리는 사용자가 사고 과정의 원본을 직접 보지 않도록 결정했습니다. 이 결정에는 단점이 있음을 인지하고 있습니다. 우리는 모델이 사고 과정에서 유용한 아이디어를 답변에 재현하도록 훈련시킴으로써 이를 부분적으로 보완하려고 노력하고 있습니다. o1 모델 시리즈의 경우, 사고 과정의 요약본을 모델이 생성하여 사용자에게 보여줍니다.