Llama 3.1 사용법 - 8B, 70B, 405B 모두 무료로 사용하기
Llama 3.1 을 사용할 수 있는 방법을 함께 알아보고 설명합니다. 다양한 방법을 통해 무료로 사용할 수 있습니다.
8B 로컬 컴퓨터에 설치하기
8B 모델은 로컬 컴퓨터에도 설치하고 실행할 수 있습니다. 방법은 ollama 나 LM studio 를 이용하는 방법이 있습니다.
저는 ollama를 설치해서 진행하겠습니다. Ollama
여기에서 운영 체제에 맞는 파일을 다운로드 받아 설치하시면 됩니다.
그 다음 우측 상단에 있는 Models를 누릅니다.
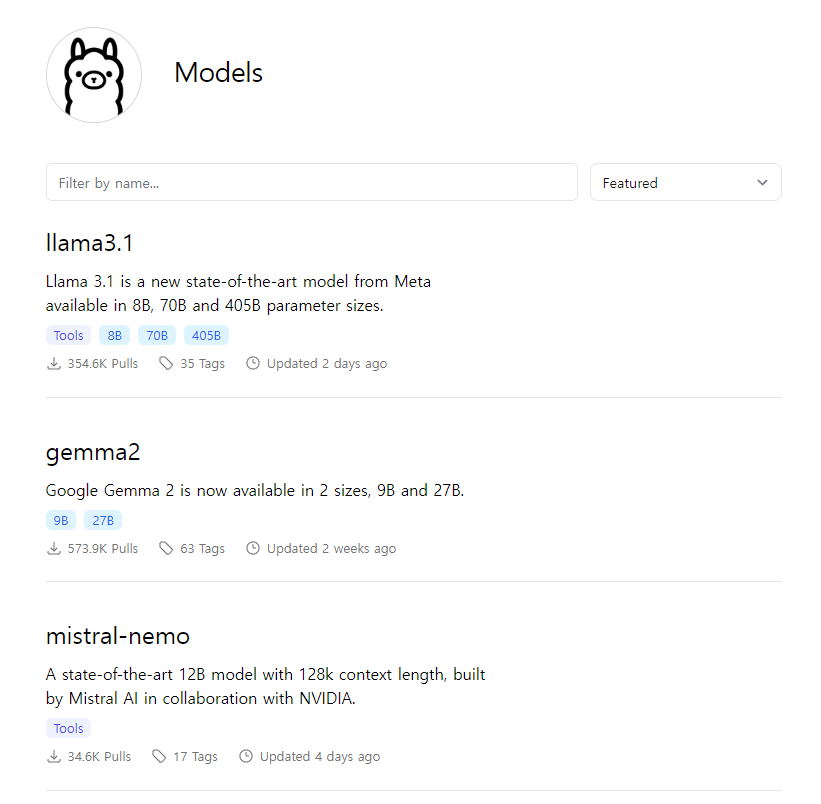
여기에서 llama 3.1을 선택합니다.
여기에서 8B, 70B, 405B 가 있는데 로컬에서 실행하기에는 8B가 가장 좋습니다. 올라마의 8B 모델은 4비트 양자화 버전으로 용량은 4.7GB 입니다.
다음은 터미널로 이동합니다.
윈도우의 경우 검색창에 power 라고 입력하여 파워셀을 실행합니다.
입력창에 다음과 같이 입력해서 모델을 다운로드 받고 설치하면 됩니다.
ollama run llama3.1
모델 다운로드 받는데 좀 시간이 걸립니다. 참 쉽죠잉?
올라마가 실행 중일 때는 윈도우의 경우 우측 하단에 이렇게 양 모양의 아이콘이 떠있습니다. 재부팅 시 올라마가 자동으로 실행되는데 이게 싫으시면 윈도우 검색 - 시작 프로그램에서 ollama.exe 를 비활성화하면 됩니다.
모델이 다운로드가 완료되면 다음 명령어로 실행하면 됩니다.
ollama run llama3.1 "hello"
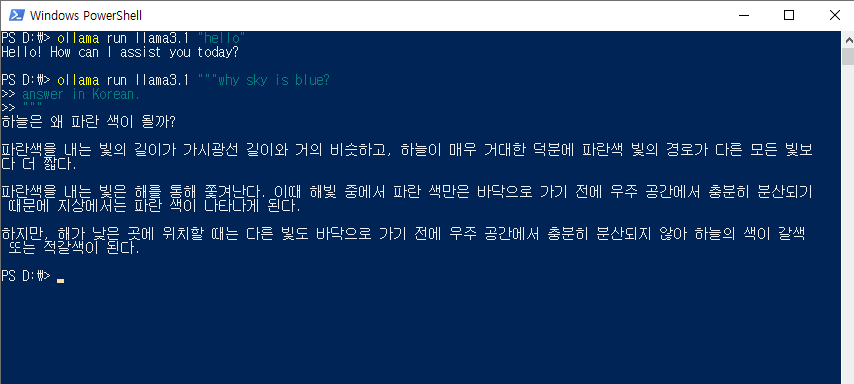
"hello" 부분에 원하는 프롬프트를 입력하면 됩니다.
이제 로컬에서 무제한으로 8B 모델을 사용할 수 있습니다.
Open WebUI
Open WebUI 를 사용하면 다양한 llm 을 채팅 형식으로 편하게 사용할 수 있습니다.
open web ui 는 도커를 사용합니다. docker 가 설치되어 있지 않으시다면 Docker: Accelerated Container Application Development 에서 설치할 수 있습니다.
도커가 설치됐다면 다음과 같이 docker를 설치할 수 있습니다. 상황에 맞게 터미널에서 명령어를 입력하세요.
Ollama 가 컴퓨터에 설치되어 있을 때 (저는 1번으로 진행)
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainOllama 가 다른 서버에 있을 때
OLLAMA_BASE_URL를 서버 URL에 맞게 도정docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:mainOpen WebUI 를 Nvidia GPU 지원과 함께 실행할 때
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
도커 이미지 설치가 완료되었다면 http://localhost:3000 을 통해 Open WebUI 에 접속합니다. 회원가입은 계정을 임의로 생성한 후 로그인하면 됩니다.
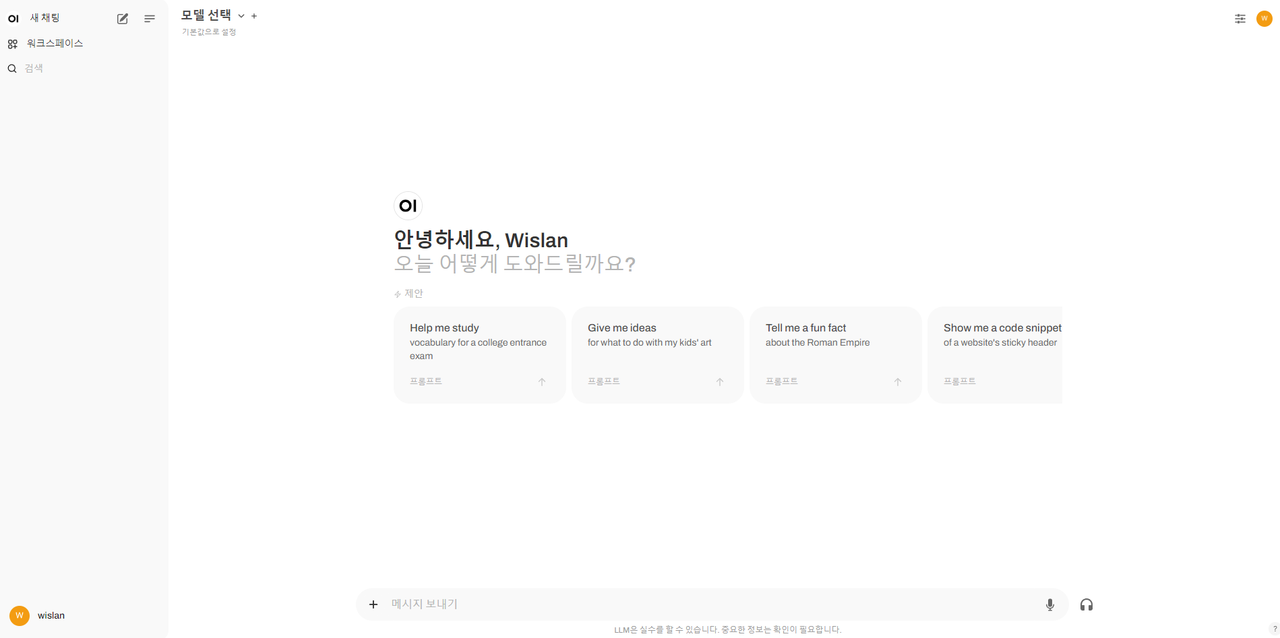
그러면 이런 화면을 보실 수 있을 겁니다.
70B 사용하기 (groq)
70B는 아마 대부분의 컴퓨터에서 돌리기 어려울 겁니다. 그럴 때 groq의 API 서비스를 이용하면 됩니다. 그로크는 LPU를 활용하여 API를 사용할 수 있게 하는 서비스입니다. 사용량 제한이 걸려 있는 무료 API를 제공하는데 여기에서 라마 3.1 등 다양한 LLM을 활용할 수 있습니다.
GroqCloud 로 이동합니다. 우측 상단에서 사용할 수 있는 다양한 모델들을 확인할 수 있습니다.
좌측 바의 API Keys로 이동에 API 키를 발급받습니다. 이 키는 한번 표시되면 다시 볼 수 없으니 안전한 텍스트 파일에 저장해 두세요. (외부 노출 X)
코드에서 API키를 활용해서 직접 호출해도 되고 LLM 모델들을 편리하게 사용하기 위해서 open web ui 를 사용해도 됩니다.
다시 open web ui로 돌아와서 진행해 보겠습니다.
좌측 하단의 관리자 패널로 들어갑니다.
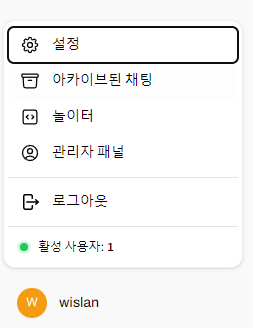
관리자 채널에서 설정을 누르고 연결로 이동합니다.
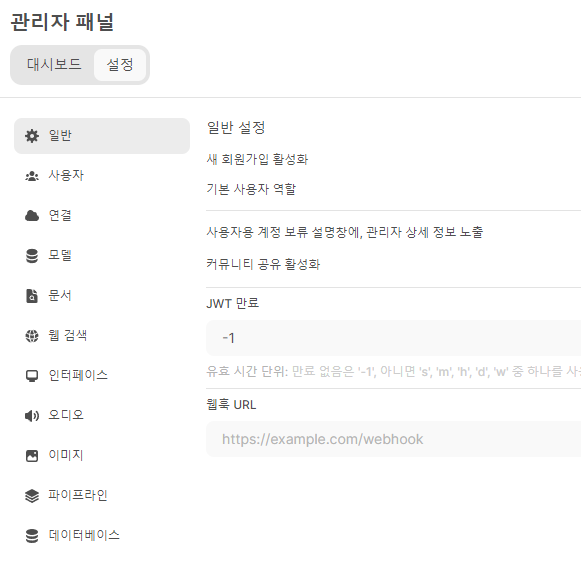
이 연결 부분에 아까 만든 groq의 키를 OpenAI API 에 입력하면 됩니다.

주소에는 https://api.groq.com/openai/v1 를 입력하고 키는 아까 생성한 키를 입력합니다.
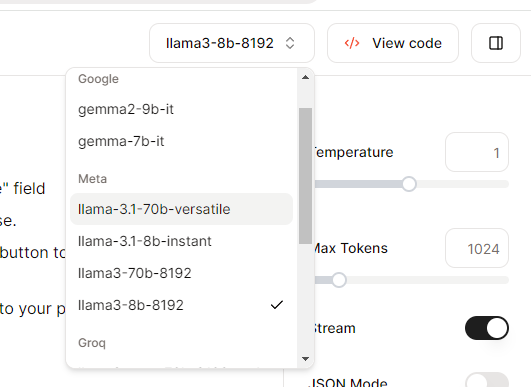
이후 새 채팅 - 모델 선택에서 groq에 연결된 다양한 모델들을 확인할 수 있습니다.
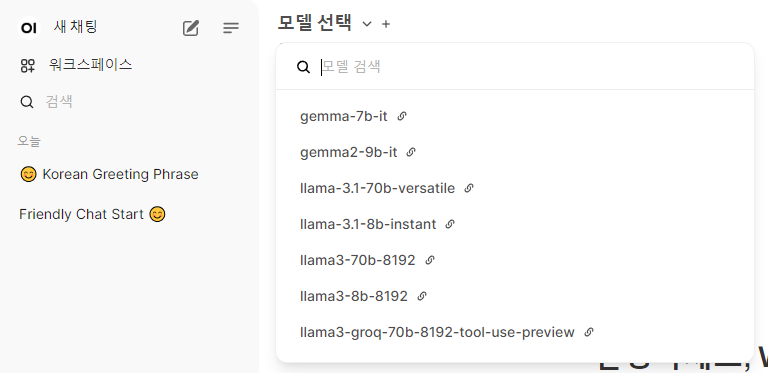
여기에서 llama-3.1-70b-versatile 을 선택하면 됩니다. 이게 3.1 70B 모델입니다.
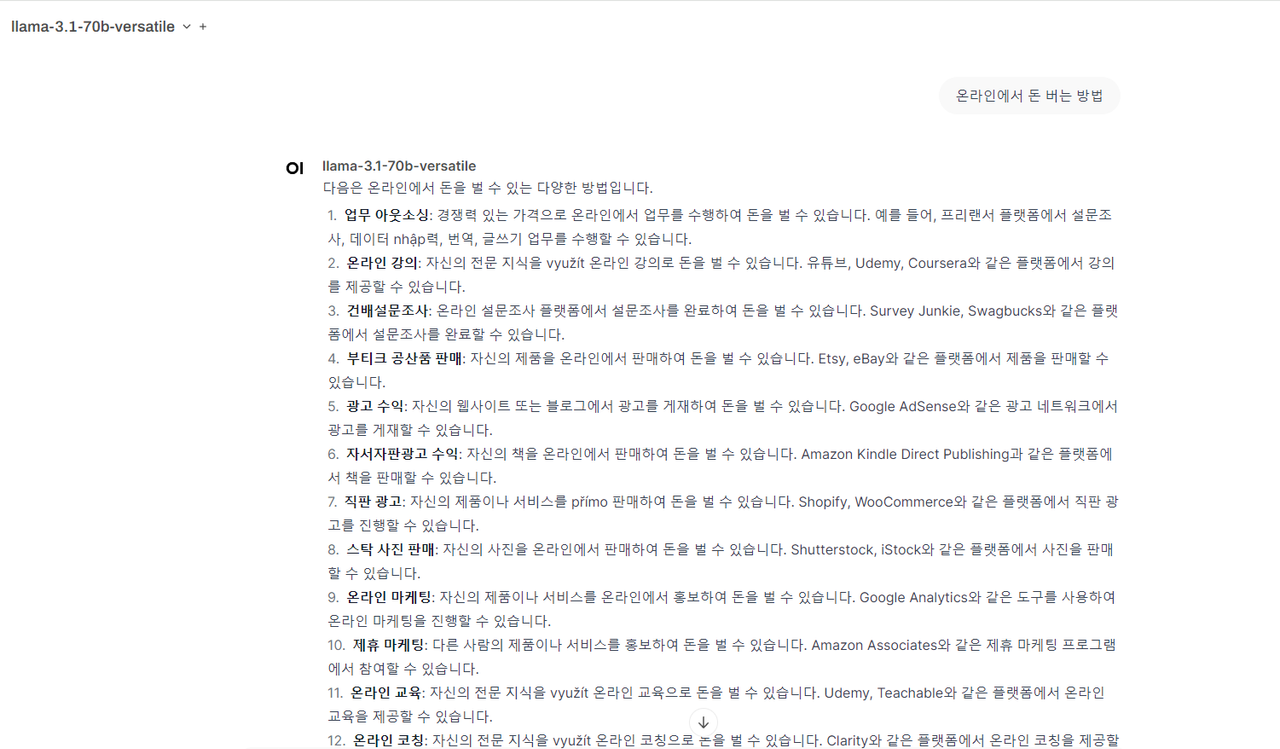
70b의 경우 한글로 질문했을 때 깨지는 현상을 볼 수 있습니다. groq 에서 아직 최적화가 되어 있지 않은듯 합니다.
그래도 무료 사용량과 다른 모델 사용 부분이 괜찮으니 검토해 보시기 바랍니다.
여기에서 groq 의 무료의 사용량 제한 (rate limit) 을 볼 수 있습니다. GroqCloud
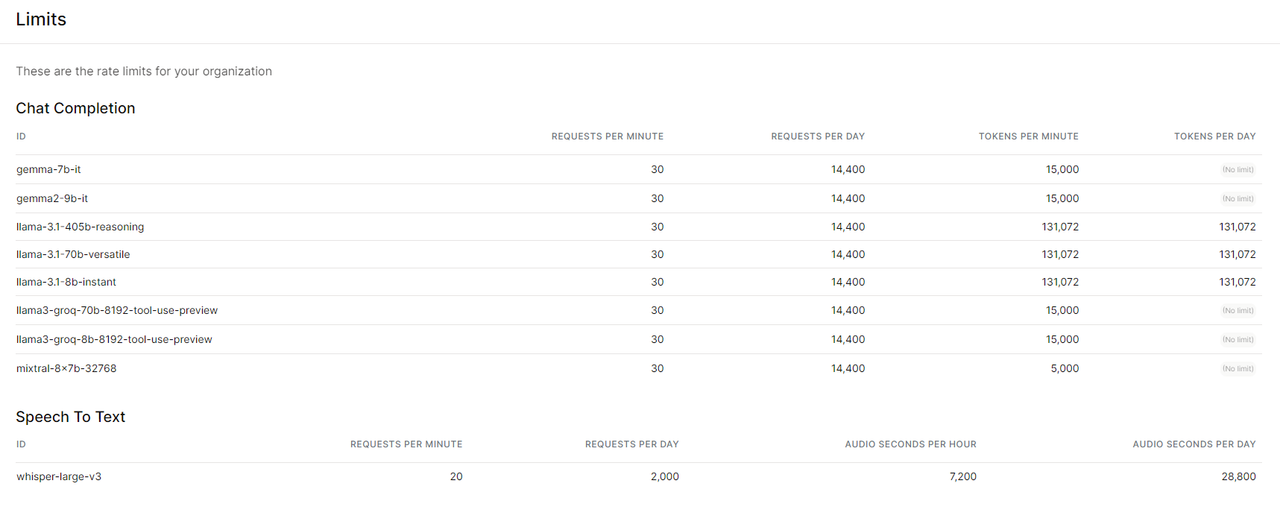
분당 30번 정도의 요청으로 무료에서도 꽤 관대한 사용량을 제공합니다.
405B - together ai 이용
together.ai 에 가입을 하면 5달러 정도의 크레딧을 활용할 수 있습니다. 이걸 활용해서 405b를 돌려 보겠습니다.
회원 가입을 한 후 https://api.together.ai/ 에서 api 키를 복사합니다.
도커에서 이미지 구동 확인 후 - localhost:3000 - 관리자 패널 - 설정 - 연결에서 +를 누른 후 다음과 같이 입력합니다.
https://api.together.xyz/v1 그리고 API key 에 복사한 api 키를 입력합니다.
그 후 모델 선택을 하면 정말 다양한 모델들이 나오는데요.
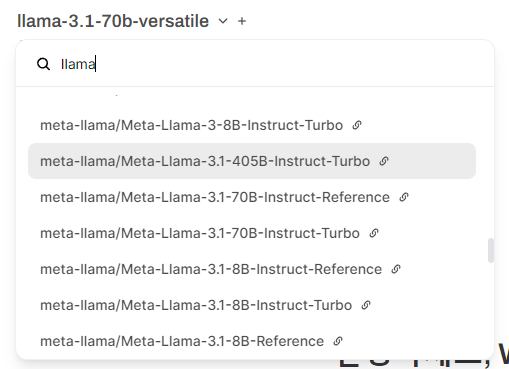
여기에서 llama 3.1 405B를 선택해 주면 됩니다.
다음은 채팅 결과입니다.
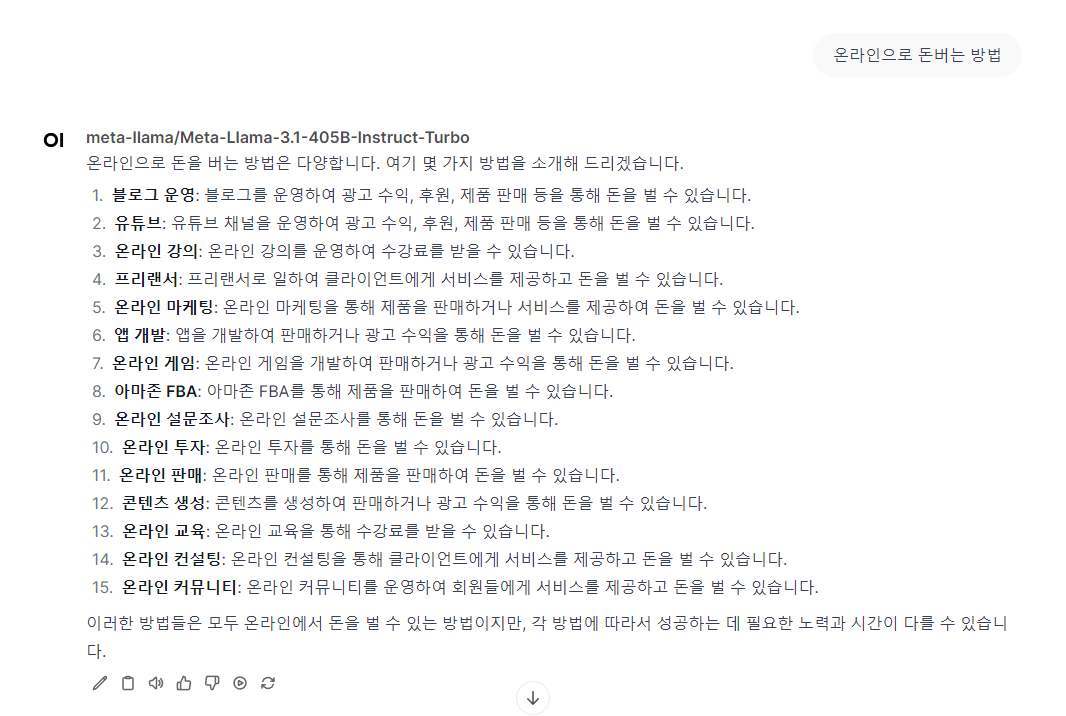
한글도 깨짐없이 잘 나오는 것을 볼 수 있습니다.
다음 시간에는 실제로 나의 작업에 AI 에이전트를 적용하는 사례를 다뤄보도록 하겠습니다.