
llama 3.1 405b, 70b, 8b 벤치 마크
내일 공개될 것으로 보이는 라마 3.1 405b, 70b, 8b의 벤치마크 정보가 유출됐다. 벤치마크 자료에서는 여러 영역에서 GPT-4o를 뛰어넘을 가능성이 있다고 한다.
| gpt-4o | Meta-Llama-3.1-405B | Meta-Llama-3.1-70B | Meta-Llama-3-70B | Meta-Llama-3.1-8B | Meta-Llama-3-8B | |
|---|---|---|---|---|---|---|
| boolq | 0.905 | 0.921 | 0.909 | 0.892 | 0.871 | 0.82 |
| gsm8k | 0.942 | 0.968 | 0.948 | 0.833 | 0.844 | 0.572 |
| hellaswag | 0.891 | 0.92 | 0.908 | 0.874 | 0.768 | 0.462 |
| human_eval | 0.921 | 0.854 | 0.793 | 0.39 | 0.683 | 0.341 |
| mmlu_humanities | 0.802 | 0.818 | 0.795 | 0.706 | 0.619 | 0.56 |
| mmlu_other | 0.872 | 0.875 | 0.852 | 0.825 | 0.74 | 0.709 |
| mmlu_social_sciences | 0.913 | 0.898 | 0.878 | 0.872 | 0.761 | 0.741 |
| mmlu_stem | 0.696 | 0.831 | 0.771 | 0.696 | 0.595 | 0.561 |
| openbookqa | 0.882 | 0.908 | 0.936 | 0.928 | 0.852 | 0.802 |
| piqa | 0.844 | 0.874 | 0.862 | 0.894 | 0.801 | 0.764 |
| social_iqa | 0.79 | 0.797 | 0.813 | 0.789 | 0.734 | 0.667 |
| truthfulqa_mc1 | 0.825 | 0.8 | 0.769 | 0.52 | 0.606 | 0.327 |
| winogrande | 0.822 | 0.867 | 0.845 | 0.776 | 0.65 | 0.56 |
| 표 : 베이스 모델의 성능 (instruct 아님) |
출처 : https://www.reddit.com/r/LocalLLaMA/comments/1e9hg7g/azure_llama_31_benchmarks/
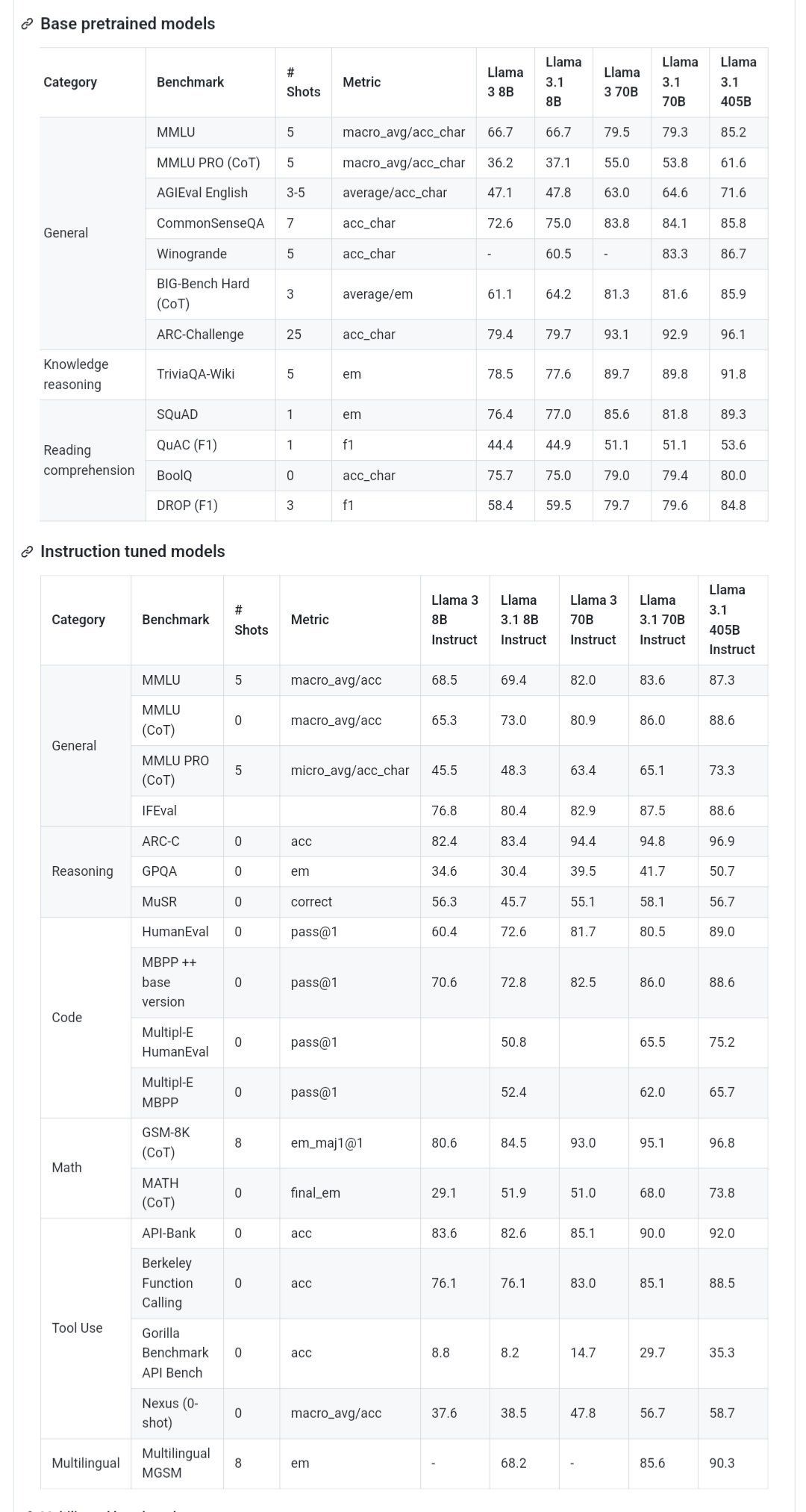
이미지 : 전체 모델 카드의 성능
출처 : x.com
놀라운건 8B, 70B 모델의 성능이 크게 향상되었다는 것이다.
70B 모델의 높은 성능은 405B와 비슷한 성능을 보여주는데 대형 모델을 더 작은 모델로 증류(distillation)하는 방식이 효과적임을 시사한다. (구글도 이와 같은 방법을 사용하고 있다.)
그리고 8B의 성능도 올라감에 따라 활용도가 높아질 것 같다.
기대되는 건 한글의 성능이 어느정도냐와 meta.ai 와 같은 서비스에서 405B를 바로 사용할 수 있느냐가 될 것 같다.
성능 면에서는 각 빅테크가 금방 서로 따라잡는 것 같다. 이제는 추론 능력의 싸움이 될 것 같다. 모델의 성능은 좋지만 진정한 추론을 할 수 있느냐에 따라 승부가 갈릴 것 같다. 예를 들어 LLM이 수학이나 추리 문제, IQ 문제를 풀 수 있다면 향상된 추론 능력을 보인다고 할 수 있다. 이 단계까지 가기 굉장히 어려울 수 도 있다. 하지만 얀 르쿤이 추론 능력에 대해 강조해왔던만큼 이번 405B는 기대가 많이 된다.
GPT-5 또는 동등한 모델은 올해 말 출시될 것으로 예상되는데 추론 능력이나 에이전트 능력이 강화되어 경쟁하게 될 것 같다.
일단 오늘 밤에 공개될 것으로 보이는데 차후 분석해 보겠습니다~!