SpreadsheetLLM - 스프레드시트에 전문화된 마이크로소프트의 프레임워크
SpreadsheetLLM
소개
SpreadsheetLLM은 대규모 언어 모델(LLM)이 스프레드시트를 효율적으로 이해하고 분석할 수 있도록 하는 혁신적인 프레임워크입니다. Microsoft 연구진은 복잡한 스프레드시트 데이터를 효율적으로 인코딩하고 LLM의 강력한 이해 및 추론 능력을 최적화하기 위해 이 프레임워크를 개발했습니다[1].
문제점 및 해결책
스프레드시트는 방대한 2차원 그리드, 유연한 레이아웃, 다양한 형식 옵션 등으로 인해 LLM에게 상당한 도전 과제를 제시합니다. 특히, 셀 주소, 값, 형식을 포함한 데이터를 처리하려면 많은 토큰이 필요해 기존의 직렬화 방식으로는 한계가 있었습니다[1][2].
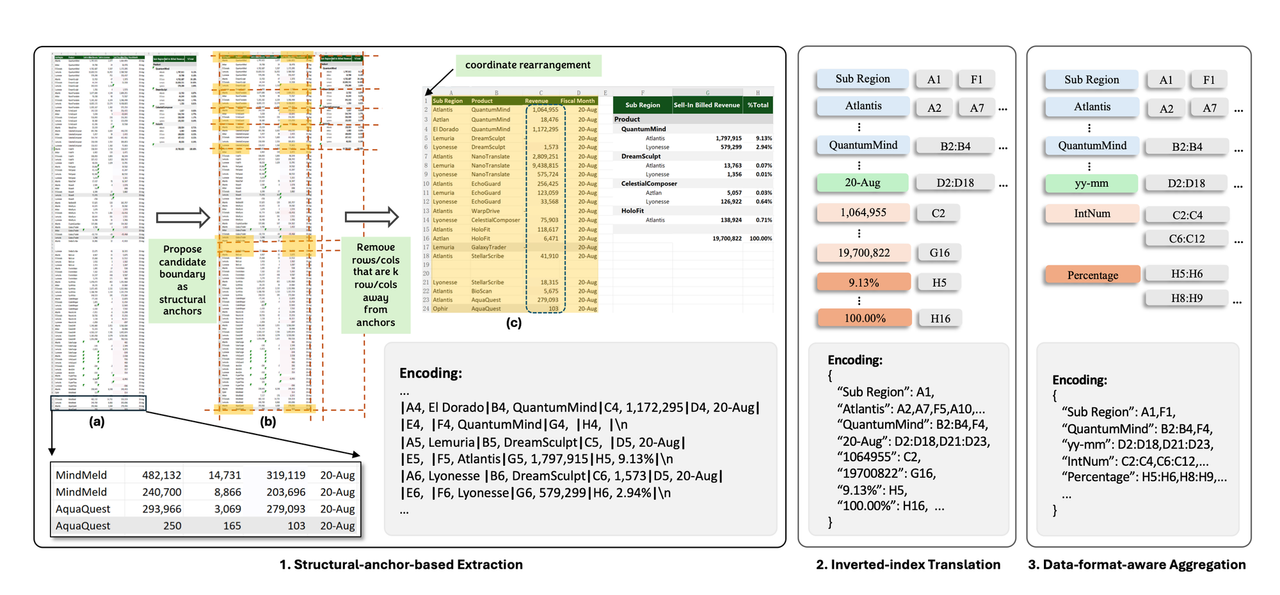
이를 해결하기 위해, 연구팀은 SheetCompressor라는 혁신적인 인코딩 프레임워크를 개발했습니다. SheetCompressor는 스프레드시트를 효과적으로 압축하여 LLM이 적은 토큰으로 더 많은 정보를 처리할 수 있도록 합니다. 이 프레임워크는 구조적 앵커 기반 압축, 역 인덱스 번역, 데이터 형식 인식 집계를 포함한 세 가지 주요 모듈로 구성됩니다[3][4][5].
세부 인코딩 방법
바닐라 인코딩 (Vanilla Encoding): 초기 단계에서는 스프레드시트의 셀 주소, 값, 형식을 시퀀스에 포함시켜 직렬화합니다. 이 방법은 직관적이지만 LLM의 토큰 제한에 금방 도달한다는 단점이 있습니다[2][4].
구조적 앵커 기반 압축 (Structural-anchor-based Compression): 대형 스프레드시트는 종종 많은 동질적 행이나 열을 포함합니다. 이 방법은 테이블 경계에서 이질적인 행과 열을 식별하여 먼 동질적 데이터를 제거하고, 중요한 구조 정보를 유지하는 "스켈레톤" 버전을 생성합니다[2][3][4].
역 인덱스 번역 (Inverted-index Translation): 반복적인 값과 빈 셀 때문에 많은 토큰을 소비하는 전통적인 행별 직렬화 방법을 개선하기 위해, 비어 있지 않은 셀 텍스트의 사전을 만들어 동일한 내용의 주소를 병합합니다. 이 방법은 데이터 무결성을 유지하면서 토큰 사용을 최적화합니다[2][5].
데이터 형식 인식 집계 (Data-format-aware Aggregation): 인접한 셀의 유사한 형식을 클러스터링합니다. 예를 들어, 날짜 열은 "yyyy-mm-dd" 형식 문자열로, 숫자 값은 "FloatNum"으로 나타낼 수 있습니다. 이 접근 방식은 토큰 사용을 줄이면서 데이터의 의미론적 의미를 유지합니다[2][4].
이미지 출처 : 마이크로소프트
Chain of Spreadsheet (CoS)
SpreadsheetLLM은 스프레드시트 이해의 하위 작업을 위해 Chain of Spreadsheet(CoS)를 제안합니다. CoS는 테이블 감지, 경계 감지, 응답 생성을 포함한 여러 단계를 통해 스프레드시트 데이터를 체계적으로 분석합니다. 이러한 접근 방식은 스프레드시트 질의 응답(QA) 작업에서도 매우 유용하며, LLM이 복잡한 스프레드시트를 효과적으로 처리하고 사용자 질의에 정확하게 응답할 수 있도록 합니다[1][3][5].
실험 및 결과
스프레드시트 테이블 감지 성능 개선: SpreadsheetLLM은 GPT4의 문맥 내 학습 설정에서 25.6%의 성능 향상을 달성했으며, F1 점수에서 기존 모델을 12.3% 초과한 78.9%를 기록했습니다[2][5][6].
효과적인 압축: SheetCompressor 프레임워크는 평균 25배의 압축 비율을 달성하여 토큰 사용을 96% 줄였습니다. 이로 인해 대형 스프레드시트를 효율적으로 처리할 수 있게 되었습니다[1][7].
스프레드시트 질문 응답(QA) 개선: CoS 방법론을 적용한 결과, 스프레드시트 QA 작업에서 기존 방법보다 뛰어난 성능을 발휘했습니다. 특히, TAPEX 및 Binder 모델에 비해 각각 37% 및 12%의 정확도 향상을 보였습니다[5][7].
결론 및 미래 전망
SpreadsheetLLM은 스프레드시트 데이터를 이해하고 분석하는 데 있어 LLM의 능력을 크게 향상시키는 프레임워크입니다. 이 프레임워크는 복잡한 스프레드시트 데이터를 효율적으로 압축하고, 더 예측 가능한 응답을 생성하는 데 유용합니다. Microsoft 연구진은 이 기술이 향후 더 개발되어 다양한 비즈니스 및 데이터 관리 작업에서 활용될 것으로 기대합니다[3][6][7].
생각
LLM은 아니고 하나의 프레임워크이다. 마이크로소프트의 입장에서 스프레드시트 영역에서 생산성을 조금만 높여도 해자가 될 수 있으니 이런 연구가 이뤄지는 것 같다. 이런 식으로 작은 작업 영역에 특화된 기법들이 많이 나올 것 같다. 더 나아가 특정 영역에 특화된 LLM이 특화된 워크플로우와 사용하기 편리하게 결합되어 등장할 것 같다. 파워포인트를 위한 LLM, 엑셀을 위한 LLM 등 다양한 모델이 나올 가능성이 있다. UI, UX에 특화된 피그마의 AI 의 사례도 있다.
구글에서도 큰 모델에서 작은 모델을 추출하는 기법들을 연구하고 있고 특정 분야에 특화된 sLM 등이 많이 나오게 될 가능성이 있다.
참고 문헌
이 노트는 요약·비평·학습 목적으로 작성되었습니다. 저작권 문의가 있으시면 에서 알려주세요.
키워드만 입력하면 나만의 학습 노트가 완성돼요.
책이나 강의 없이, AI로 위키 노트를 바로 만들어서 읽으세요.
콘텐츠를 만들 때도 사용해 보세요. AI가 리서치, 정리, 이미지까지 초안을 바로 만들어 드려요.