
DeepSeek-Coder-V2 - GPT-4o와 성능이 비슷한 오픈 소스 코드 모델
DeepSeek-Coder-V2는 코드 분야의 오픈 소스 Mixture-of-Experts(MoE) 코드 언어 모델입니다.
개요
DeepSeek-Coder-V2는 GPT-4-Turbo와 비교할 만한 성능을 자랑하는 코드 특화 작업에 최적화된 오픈 소스 모델입니다. DeepSeek-Coder-33B와 비교하여, 코드 관련 작업, 추론 및 일반 작업에서 매우 개선된 성능을 보여줍니다. 또한, 지원하는 프로그래밍 언어 수가 86개에서 338개로 확장되었으며, 컨텍스트 길이도 16K에서 128K로 늘어났습니다.
주요 특징 성능 향상: 추가 6조 개의 토큰으로 다시 학습하여 코딩 및 수학적 추론 능력을 크게 향상했습니다.
폭넓은 언어 지원: 지원하는 프로그래밍 언어 수가 338개로 확장되었습니다.
긴 컨텍스트 길이: 컨텍스트 길이가 기존 16K에서 128K로 확장되었습니다.
개방형 소스: 오픈 소스 라이선스를 통해 누구나 사용할 수 있습니다.
모델 다운로드 DeepSeek-Coder-V2는 두 가지 주요 버전으로 제공됩니다: Lite 모델과 Full 모델.
| 모델 | 총 파라미터 수 | 활성 파라미터 수 | 컨텍스트 길이 |
|---|---|---|---|
| DeepSeek-Coder-V2-Lite-Base | 16B | 2.4B | 128k |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 128k |
| DeepSeek-Coder-V2-Base | 236B | 21B | 128k |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 128k |
다운로드 링크 : DeepSeek-Coder - a deepseek-ai Collection
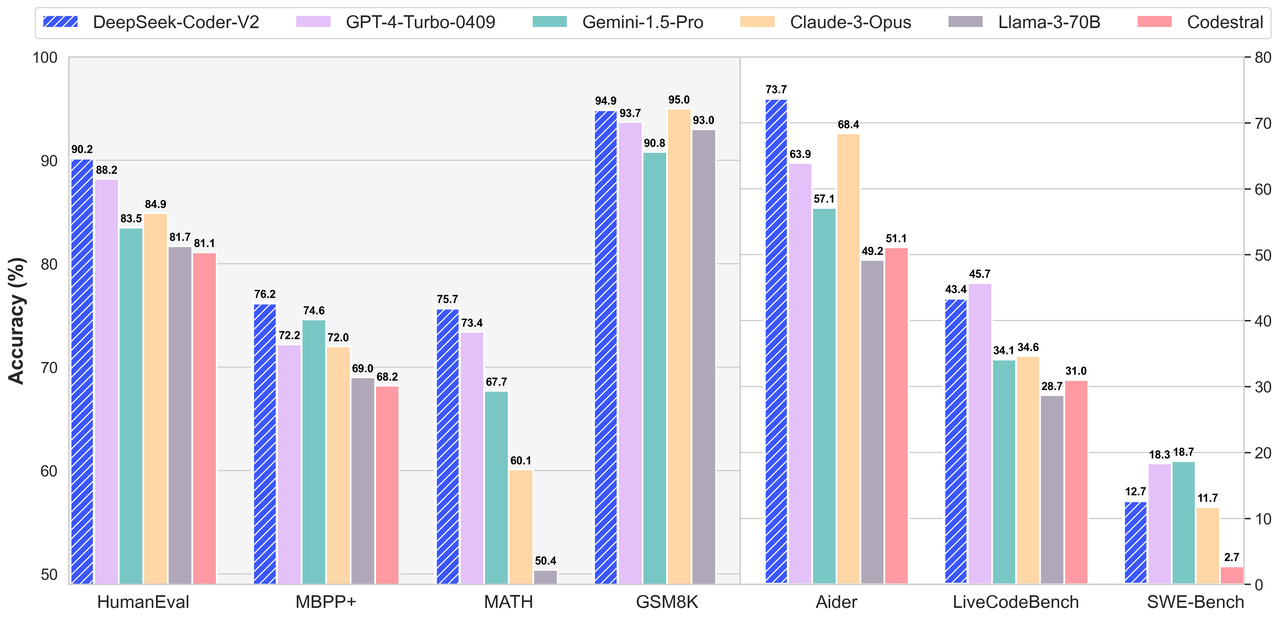
성능 평가
코드 생성 벤치마크 (Code Generation)
| #TP | #AP | HumanEval | MBPP+ | LiveCodeBench | USACO | |
|---|---|---|---|---|---|---|
| Closed-Source Models | ||||||
| Gemini-1.5-Pro | - | - | 83.5 | 74.6 | 34.1 | 4.9 |
| Claude-3-Opus | - | - | 84.2 | 72.0 | 34.6 | 7.8 |
| GPT-4-Turbo-1106 | - | - | 87.8 | 69.3 | 37.1 | 11.1 |
| GPT-4-Turbo-0409 | - | - | 88.2 | 72.2 | 45.7 | 12.3 |
| GPT-4o-0513 | - | - | 91.0 | 73.5 | 43.4 | 18.8 |
| Open-Source Models | ||||||
| CodeStral | 22B | 22B | 78.1 | 68.2 | 31.0 | 4.6 |
| DeepSeek-Coder-Instruct | 33B | 33B | 79.3 | 70.1 | 22.5 | 4.2 |
| Llama3-Instruct | 70B | 70B | 81.1 | 68.8 | 28.7 | 3.3 |
| DeepSeek-Coder-V2-Lite-Instruct | 16B | 2.4B | 81.1 | 68.8 | 24.3 | 6.5 |
| DeepSeek-Coder-V2-Instruct | 236B | 21B | 90.2 | 76.2 | 43.4 | 12.1 |
DeepSeek-Coder-V2-Instruct의 경우 GPT-4o-0513과 비슷한 성능을 보인다.
사용
웹사이트에서 활용 : https://chat.deepseek.com/coder
트랜스포머를 이용
# Code Completion
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-Coder-V2-Lite-Base", trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))#인공지능#ai#코딩