
DeepSeek 모델 - 중국 펀드의 오픈 소스 모델
딥시크(DeepSeek)는 경제적이며 효율적인 혼합 전문가 모델(Mixture-of-Experts, MoE) 언어 모델을 대표하는 DeepSeek-V2를 제공합니다. DeepSeek-V2는 2360억 개의 총 파라미터를 가지고 있으며, 각 토큰에 대해 210억 개가 활성화됩니다. 이전 모델인 DeepSeek-67B(V1)에 비해 더 강력한 성능을 발휘하며, 훈련 비용을 42.5% 절감하고, KV 캐시를 93.3% 감소시키며 최대 생성 처리량을 5.76배로 향상시킵니다.
특이한 점은 스타트업이나 빅테크가 아닌 중국의 퀀트 펀드가 개발한다는 점이다.
모델 개요
DeepSeek-V2는 다양한 고품질 코퍼스에서 8.1조 토큰을 사용하여 사전 훈련되었습니다. 이 종합적인 사전 훈련 후에는 지도 학습(Supervised Fine-Tuning, SFT)과 강화 학습(Reinforcement Learning, RL) 과정을 통해 모델의 능력을 완전히 발휘할 수 있도록 했습니다. 평가 결과, DeepSeek-V2는 표준 벤치마크 및 오픈형 생성 평가에서 놀라운 성능을 보여줍니다.
주요 기능 및 성능
DeepSeek-V2는 수학, 코드 및 추론에 특화되어 있으며, 다음과 같은 주요 기능을 갖추고 있습니다.
수학: DeepSeek-V2는 GSM8K와 같은 수학 벤치마크에서 탁월한 성능을 보여줍니다.
코딩: HumanEval 및 MBPP 벤치마크에서 우수한 성능을 발휘합니다.
추론: MMLU 및 BBH 벤치마크에서 경쟁력 있는 성과를 내며, 영어와 중국어 모두에서 높은 점수를 기록합니다.
컨텍스트 길이 지원
DeepSeek-V2는 다양한 컨텍스트 길이를 지원합니다:
오픈 소스 모델: 128K 컨텍스트 길이 지원
대화/API 지원 모델: 32K 컨텍스트 길이 지원
경제적이고 효율적인 MoE 아키텍처
DeepSeek-V2는 경제적 훈련과 효율적 추론을 보장하는 혁신적인 아키텍처를 채택했습니다.
다중 헤드 잠재 주의력(MLA): 낮은 순위의 키-값 통합 압축을 사용하여 추론 시간 키-값 캐시 병목 현상을 제거합니다.
FFN: 훈련 비용을 줄이면서 더 강력한 모델을 훈련할 수 있게 하는 DeepSeekMoE 아키텍처를 도입했습니다.
통계 및 평가 결과
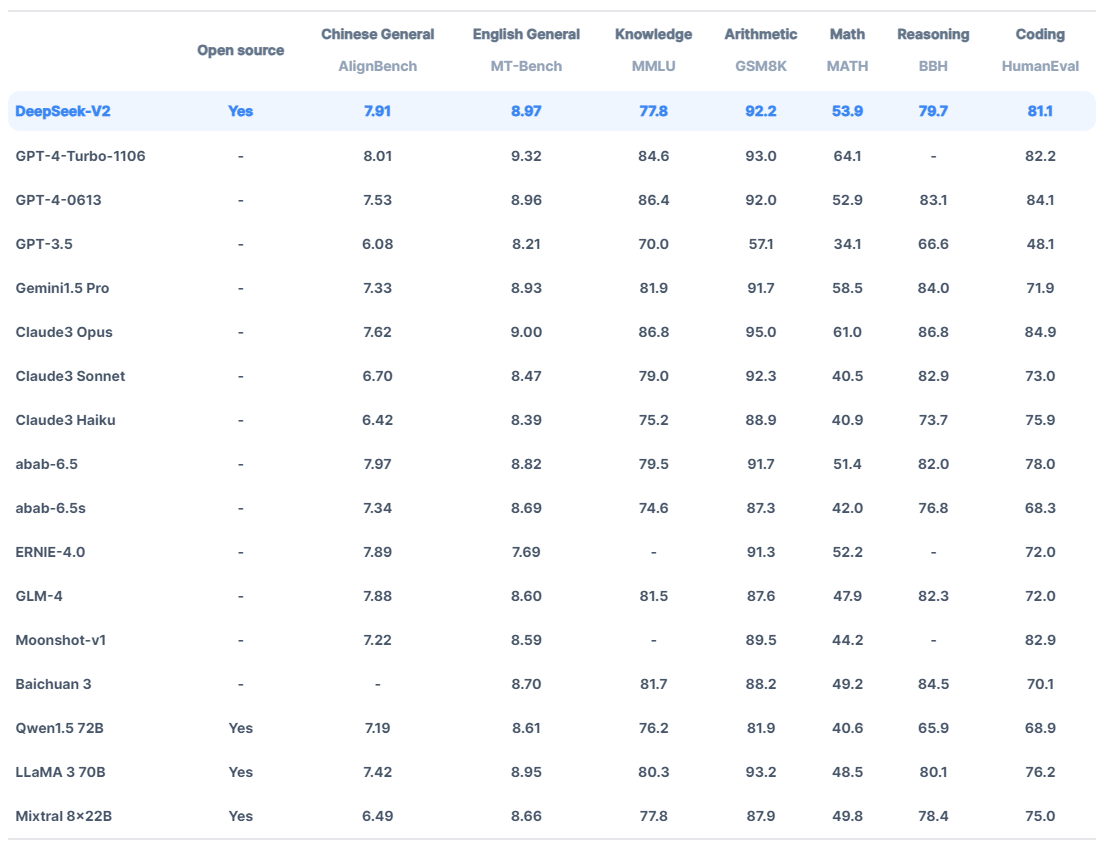
gpt-4-turbo와 성능이 유사.
API 및 지원 플랫폼
DeepSeek는 OpenAI 호환 API를 제공하여 쉽게 사용할 수 있으며, 매우 경쟁력 있는 가격으로 제공됩니다.
입력 토큰당 가격: 1백만 입력 토큰당 $0.14
출력 토큰당 가격: 1백만 출력 토큰당 $0.28
오픈 소스 및 이용권
DeepSeek-V2는 상업적 사용을 지원하며 MIT 라이선스와 모델 라이선스에 따라 제공됩니다. 사용자는 GitHub 및 Huggingface를 통해 모델을 다운로드할 수 있습니다.
Deepseek Coder V2
코드 전용 모델. GPT-4 Turbo와 성능이 유사. coder.deepseek.com 에서 사용할 수 있음.