
GPT-4o - 새로운 GPT-4 멀티 모달 모델
GPT-4o (omni)
OpenAI의 새로운 플래그십 모델. 오디오, 비전, 텍스트를 오가며 실시간으로 처리할 수 있다.
GPT-4o는 자연스러운 인간-컴퓨터 인터랙션을 추구한다. 텍스트, 오디오, 이미지의 다양한 조합을 받을 수 있으며 역시 다양한 형식의 아웃풋을 낼 수 있다. 오디오 인풋에는 최소 232 밀리세컨드 내에 반응할 수 있으며 평균은 320 밀리세컨드이다. 이는 인간의 응답 속도와 비슷하다.
이 모델은 영어와 코드에 있어 GPT-4 Turbo의 퍼포먼스에 근접한다. 또한 비영어 언어에 있어서도 성능이 향상되었다. API는 더 빠르고 50% 저렴하다. GPT-4o는 특히 비전과 오디오 이해에 있어 기존 모델보다 뛰어나다.
기존의 Voice 모드는 2.8~5.4 초의 레이턴시가 있었다. 하지만 GPT-4o는 실시간에 가까운 응답 속도에 말하는 사람의 톤을 관찰할 수 있고, 다양한 화자를 구분할 수 있고, 배경 소음 등을 인식할 수 있다. 또한 웃음, 노래하기, 감정 표현하기 등을 할 수 있다.
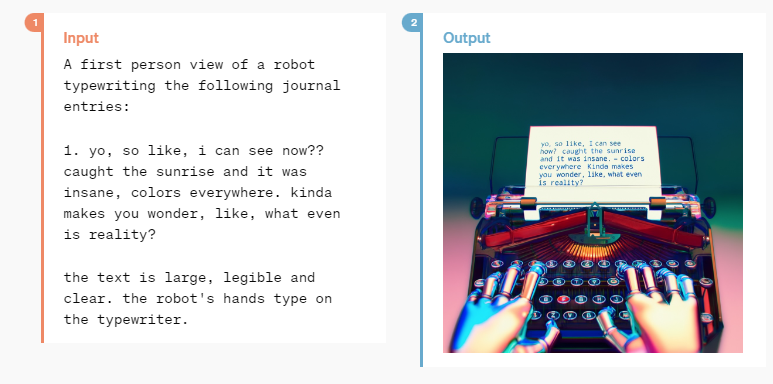
다양한 언어를 하나의 신경망으로 훈련했기 때문에 다양한 포맷을 혼합해서 사용할 수 있다. 위의 사진은 텍스트 input을 바탕으로 이미지 아웃풋을 뽑아내는 장면.
성능
텍스트 능력
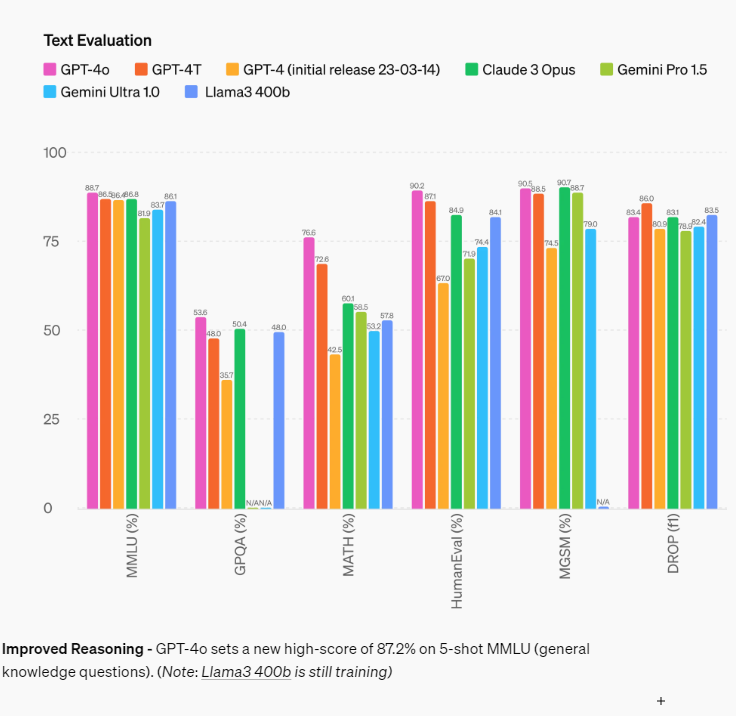
MMLU에서 무려 88.7점을 기록해 버렸다...
오디오 ASR (Audio Speech Recognition)
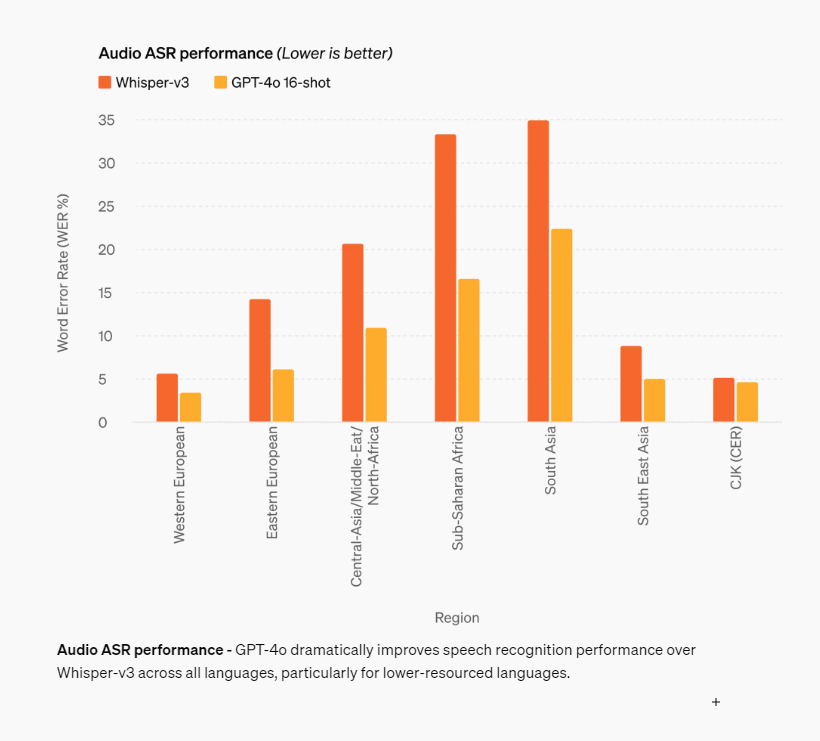
음성 인식에서는 단일 모델인 위스퍼보다는 떨어지지만 모든 영역에 있어서 성능향상이 있었다. 특히 한국어가 포함된 CJK는 차이가 적다...!
Vision
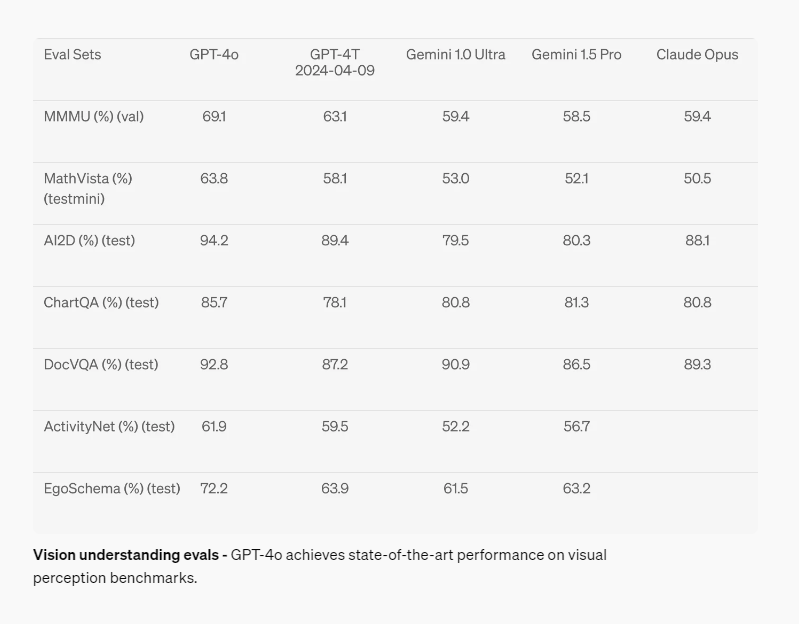
비전 능력은 다른 모든 모델을 뛰어넘는 성능을 보인다...!
언어 토큰화
20개의 언어가 새로운 토큰으로 인하여 더 높은 압축율을 가지게 됐다. 한국어의 경우 1.7배 성능 개선. 토큰 리밋은 128k.
모델 안전과 제한
다양한 모달리티에 안전 장치를 구현함. 다음과 같은 기술들이 포함. 훈련 데이터 필터링 및 훈련 후 모델의 행동 제어하기. 자체적으로 다양한 기준을 만들고 이를 준수하기 위해 노력함. 70명 이상의 레드팀을 두고 다양한 영역에 있어 위험을 줄이기 위해 노력함.
모델 배포
오늘부터 시작하여 점진적으로 배포할 예정임. 무료 사용자들도 GPT-4o를 사용할 수 있게 되고 유료 사용자들은 5배가 많은 메시지 상한선을 가지게 될 것임. 새로운 버전의 보이스 모드는 알파 상태로 ChatGPT 플러스 유저들에게 얼리 액세스로 배포할 예정임.
개발자들은 GPT-4o API 에 접근할 수 있음. (텍스트, 비전 모델) GPT-4o는 2배 더 빠르고, 반값에 제공되며 5배의 레이트 리미트를 가짐. 또한 GPT-4o의 새로운 오디오와 실시간 비디오 기능(realtime video)은 신뢰할 수 있는 작은 그룹부터 API로 배포할 계획을 가지고 있음.