
마이크로소프트에서 작은 모델인 phi-3를 출시했습니다.
phi-3-mini는 3.3조 토큰에 대해 훈련됐고 38억개 매개 변수를 가진 언어 모델입니다. 3.8B 입니다.
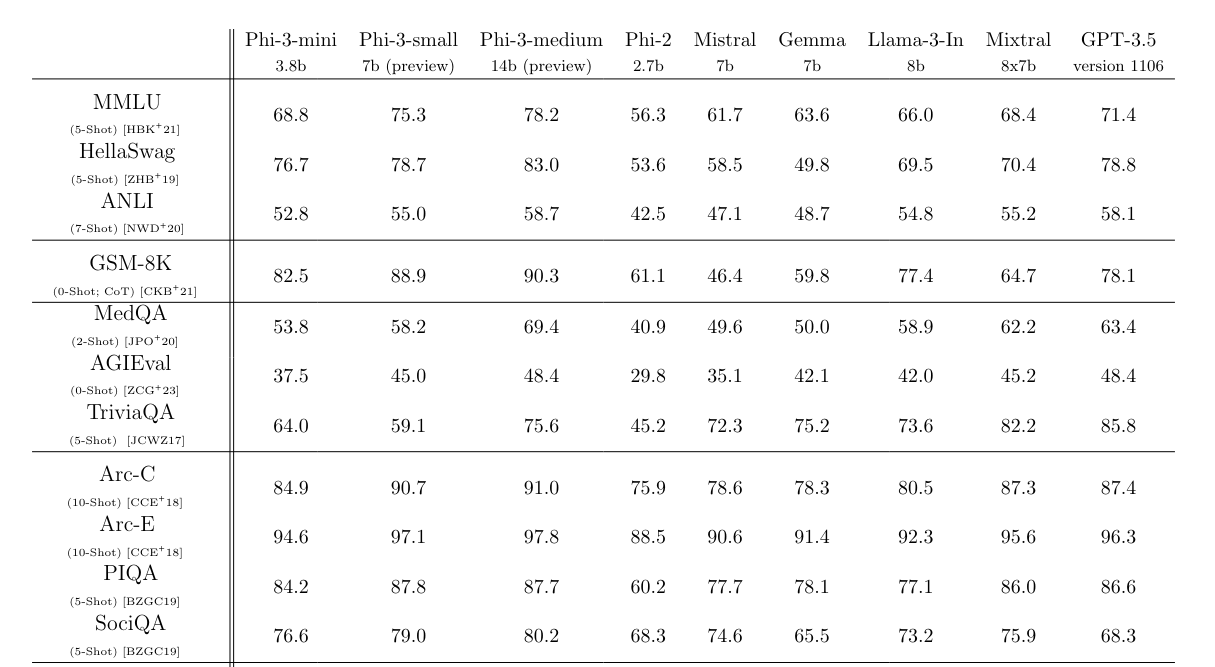
Mixtral 8X7B 나 GPT-3.5 와 비교해도 전체적으로 우수한 성능을 보입니다. MMLU에서 69%, MT-bench에서 8.38을 달성했습니다.
이 모델은 phi-2에 사용된 데이터 세트의 확장 버전을 훈련 데이터로 사용하며, 여기에는 웹 데이터와 합성 데이터가 포함됩니다.
또 7B 및 14B 매개변수의 모델인 phi-3-small과 phi-3-medium에 대한 확장 정보도 공개했습니다. 4.8조 토큰에 대해 훈련되었으며, phi-3-mini보다 더 뛰어난 성능을 보입니다. (각각 MMLU에서 75%와 78%, 그리고 MT-bench에서 8.7과 8.9 달성)
arxiv : Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
파이3를 "커리큘럼"과 함께 훈련시켰다고 하네요. 아이들이 이야기나 책에서 단순한 단어나 문장 구조로 큰 토픽을 배우는 것에 착안했다고 합니다.
“There aren’t enough children’s books out there, so we took a list of more than 3,000 words and asked an LLM to make ‘children’s books’ to teach Phi,” Boyd says.
보이드는 "시중에 어린이용 책이 부족해서 3,000개 이상의 단어 목록을 가지고 LLM에게 Phi를 가르칠 '어린이용 책'을 만들어 달라고 요청했습니다."라고 말합니다.
사용은 애저, 허깅 페이스, Ollama 에서 사용할 수 있습니다.
생각
3.3B는 정말 작은 모델로 폰에서도 쉽게 작동할 수 있을 것 같습니다. Gemma 2b가 떠오릅니다.
마이크로소프트는 phi를 통해 머신러닝에서 데이터 셋의 중요성을 테스트하는 것처럼 보입니다. 정제된 웹 데이터 + 합성 데이터를 통해 좋은 성과를 낸다는 것을 보여주는 것 같습니다. 사실 이것만 봐도 무엇을 하려는지 알것 같습니다.
작은 모델이 큰 모델에 비해 지식은 뒤처질 수 있지만 회사의 국소적인 응용 프로그램에 활용하기에는 좋은 것 같습니다.