
구글 Video Poet 공개 - Text to Video 모델, AI 비디오 시대의 도래
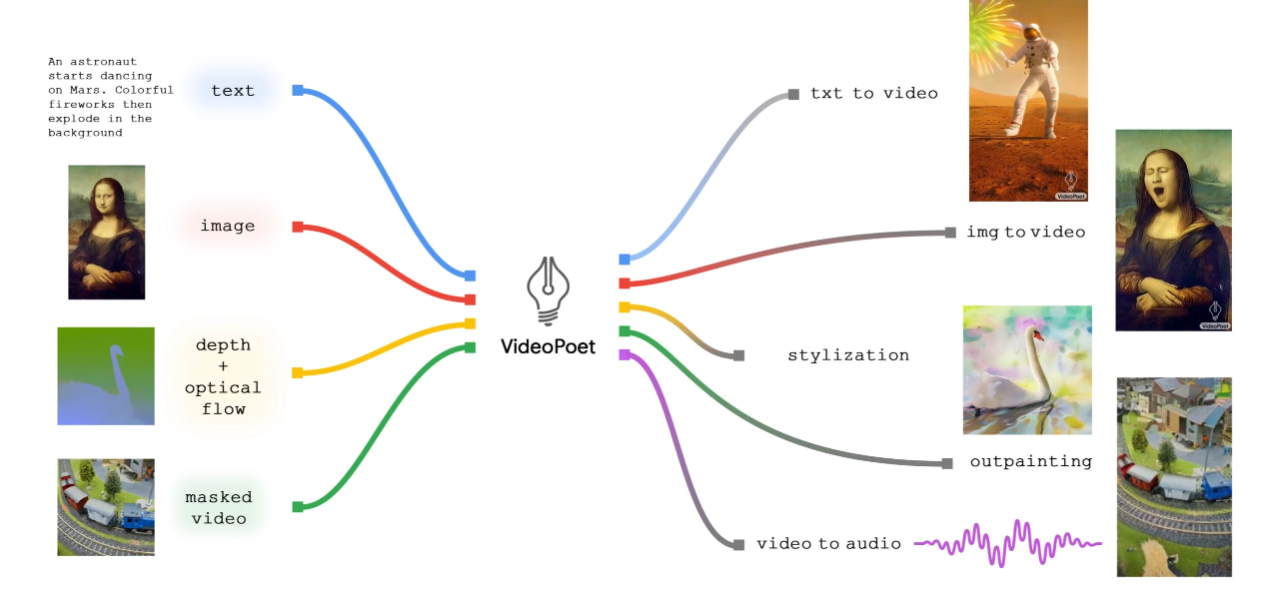
구글에서 비디오 포트를 공개했습니다. 이 AI 모델은 텍스트나 다른 인풋으로 비디오를 만들거나 편집할 수 있게 해주는 시스템입니다. 텍스트를 비디오로 만들거나, 이미지를 비디오로 변경하거나 비디오에 스타일을 입힐 수 있습니다.
VideoPoet 자체는 LLM으로 비디오, 이미지, 오디오, 텍스트 등의 데이터와 함께 학습되었습니다.
이 모델은 any to any 모델로 발전할 가능성이 큽니다. 텍스트 - 오디오, 오디오 - 비디오, 비디오 자막 등 다양한 영역에 적용할 가능성이 크다고 합니다.
아래 동영상은 구글에서 공개한 라쿤의 이야기를 바드로 편집하고 비디오포트로 생성한 것입니다.
VideoPoet의 특징은 다음과 같습니다.
LLM에 여러 기능을 통합하여 다른 경쟁 모델들과 차별화.
여러 토크나이저(MAGVIT V2 및 SoundStream)를 사용하여 비디오, 이미지, 오디오, 텍스트 모달리티들을 활용해 언어 모델(autoregressive language model)을 훈련.
텍스트 내용에 따라 다양한 길이, 움직임, 스타일을 가진 비디오를 생성할 수 있다. 이미지 애니메이션화, 비디오 스타일링, 오디오 생성 등이 가능하다. 카메라 움직임도 조정할 수 있다.
구글이 아직 모델을 공개하거나 사용할 수 있는 것은 아니지만 바드 어드밴스드에 포함될 가능성도 있다고 합니다.
Gen2, Pika, 스테이블 디퓨전 비디오, 구글의 비디오 포트 등 본격적인 AI 영상 시대가 오는 것 같네요. 조만간 1인이 영화를 만들거나 활용하는 것을 볼 수 있을 것 같습니다.
참고 : VideoPoet: Google's latest large language model generates videos
다양한 비디오와 샘플은 구글 리서치 사이트에서 확인할 수 있습니다. VideoPoet – Google Research