
Mixtral 8x7B - 작은 전문가 모델의 조합으로 효율성을 높이다.
Mixtral 8x7B는 Mistral AI에서 만든 인공지능 모델이다. SMoE (sparse mixture of experts model)로 여러 전문가 역할을 하는 작은 모델을 엮었다. 아파치 2.0 라이센스로 허용적인 라이센스 정책을 가지고 있다. Mistral AI에 따르면 성능 면에서는 Llama 2 70B 모델을 6배 빠른 추론 속도로 능가했다고 한다.
다음과 같은 특징을 가진다.
32k 컨텍스트 토큰
영어, 프랑스어, 이탈리아어, 독일어, 스페인어를 다룬다.
코드 작성에 강점을 보인다.
지침 (instruction) 에 따른 파인튜닝이 가능하다.
Sparse architecture
sparse는 드문 드문이라는 뜻이다. mixtral이 사용한 이 희소 네트워크는 8개의 전문가 모드를 feedforward 블록 단계에서 선택한다. 모든 단계(토큰)에서 라우터 네트워크가 2개의 전문가 그룹을 선택하고 처리한다.
이 기술은 토큰 당 모델의 일부분만을 사용할 수 있게해서 모델의 효율성을 높인다. Mixtral은 46.7B의 파라미터를 가지고 있지만 토큰 당 12.8B의 파라미터만을 사용한다. 이를 통해 12.8B의 속도와 비용으로 인풋과 아웃풋을 처리할 수 있게 된다.
성능
성능에서는 LLaMA 2 70B나 GPT-3.5와 비슷한 성능을 보이거나 일부 능가했다고 한다.
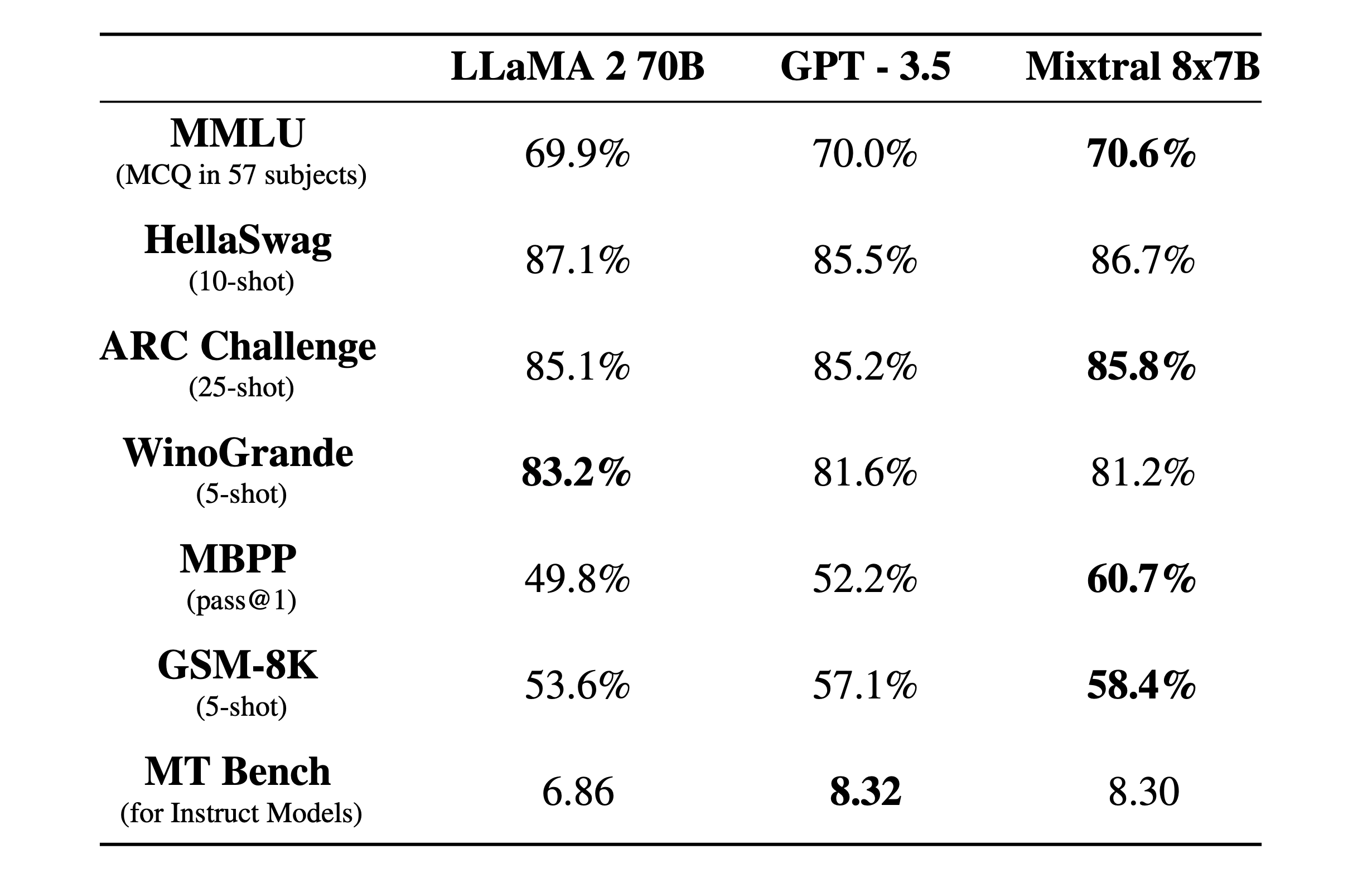
데이터는 오픈 웹에서 추출한 데이터로 사전 훈련했다.
플랫폼에서는 mixtral-small 이라는 api endpoint에서 베타 버전으로 사용할 수 있다고 한다.
생각
작은 모델들과 전문가 모드를 섞은 기술이다. 이렇게 small model 들을 활용해서 특정 분야의 instruction을 학습한 뒤 버티컬 영역을 공략하는 움직임이 있을 것 같다. 특히 MoE를 오픈 모델로 공개한 것이 인상 깊다.