자율에이전트 : GPT4-V를 활용해 아마존에서 물건사기
논문 "GPT-4V in Wonderland: Large Multimodal Models for Zero-Shot Smartphone GUI Navigation"를 읽고 정리해 봤습니다. 간단하게 말해서 GPT-4V와 같은 시각 인식 모델을 사용해 스마트폰을 조작하는 것입니다.
논문은 GPT-4 파일 기능을 이용해 통째로 올려셔 요약 한 후 필요한 부분만 정리했습니다. 논문의 경우 읽기가 힘들어 접근성이 떨어지는데 이렇게 하면 쉽게 소화할 수 있습니다.
MM-Navigator (Multi Modal Navigator)는 스마트폰 GUI 탐색을 위해 개발된 GPT-4V 기반 에이전트입니다. 이 시스템은 인간처럼 스마트폰 화면과 상호 작용하며 지시된 명령을 수행할 수 있습니다.
다양한 iOS 화면 및 사용자 지시를 포함하는 새로운 분석 데이터셋을 수집하고, 두 데이터셋에서 광범위한 평가를 수행했다고 합니다.
예시를 보면 이해하기 쉽습니다.
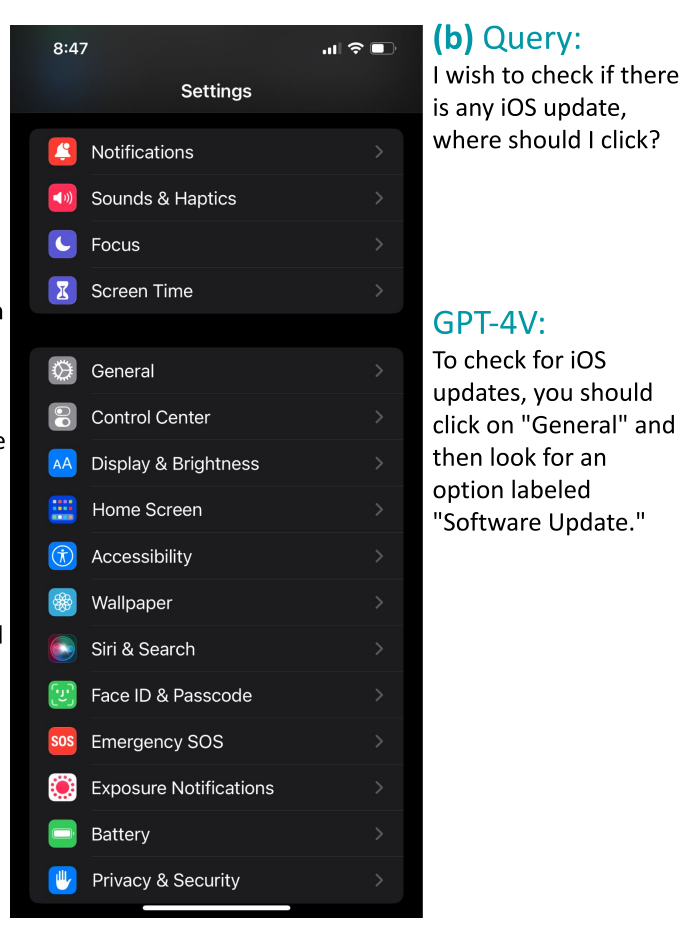
사용자 : "이 화면을 보고 아이폰 업데이트를 하려면 어떻게 해야 하는지 알려줘"
GPT-4V : "General"탭을 누르고 "소프트웨어 업데이트"를 찾아 보세요.
이렇게 한 후 결과에 대해 사람이 좋다 / 안좋다를 표시한 것입니다.
저도 전에 브라우저를 조종하는 에이전트를 만들어 보려고 한 적이 있었는데요. 웹 페이지의 html의 경우 길이가 너무 길어 인식시키기가 힘들었습니다. 하지만 이럴 때 GPT-4V와 같은 멀티모달이 있다면 효율적으로 스크린을 인식시키고 조작할 수 있습니다.
마지막으로 아마존 쇼핑으로 우유 거품기(milk frother)를 찾고 주문하는 예시입니다.
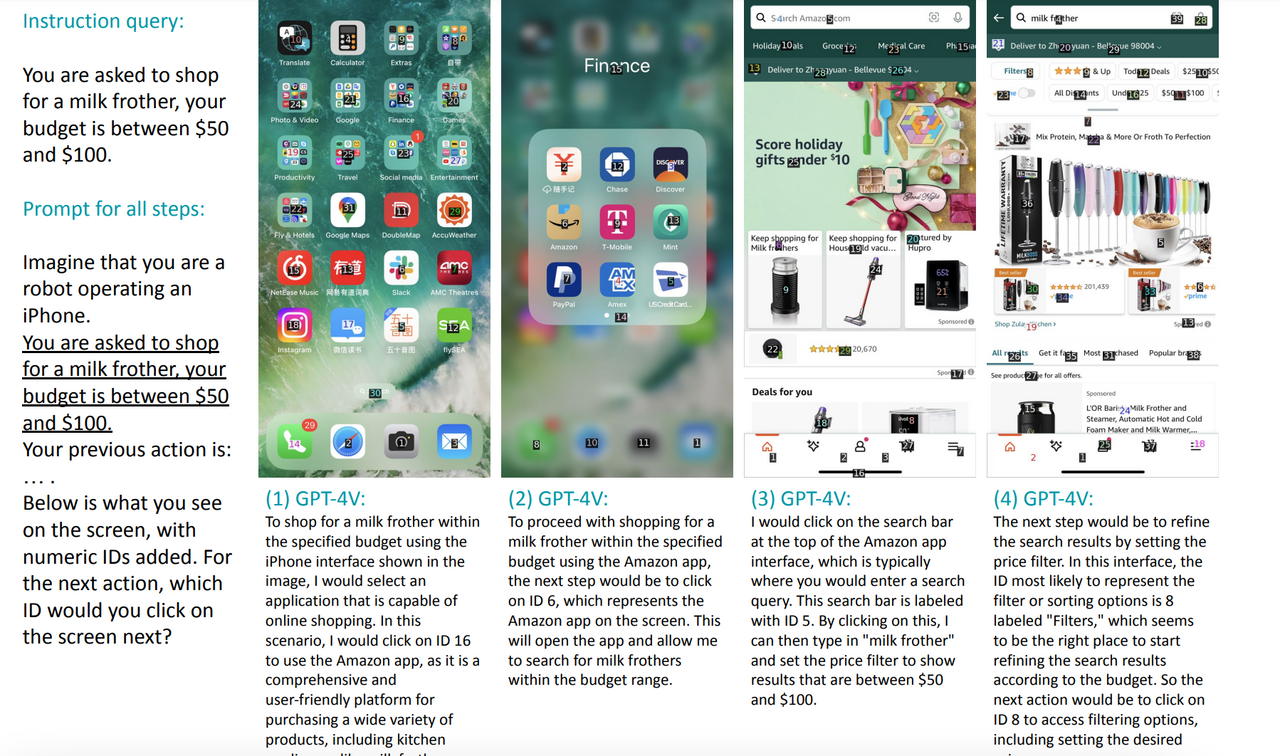
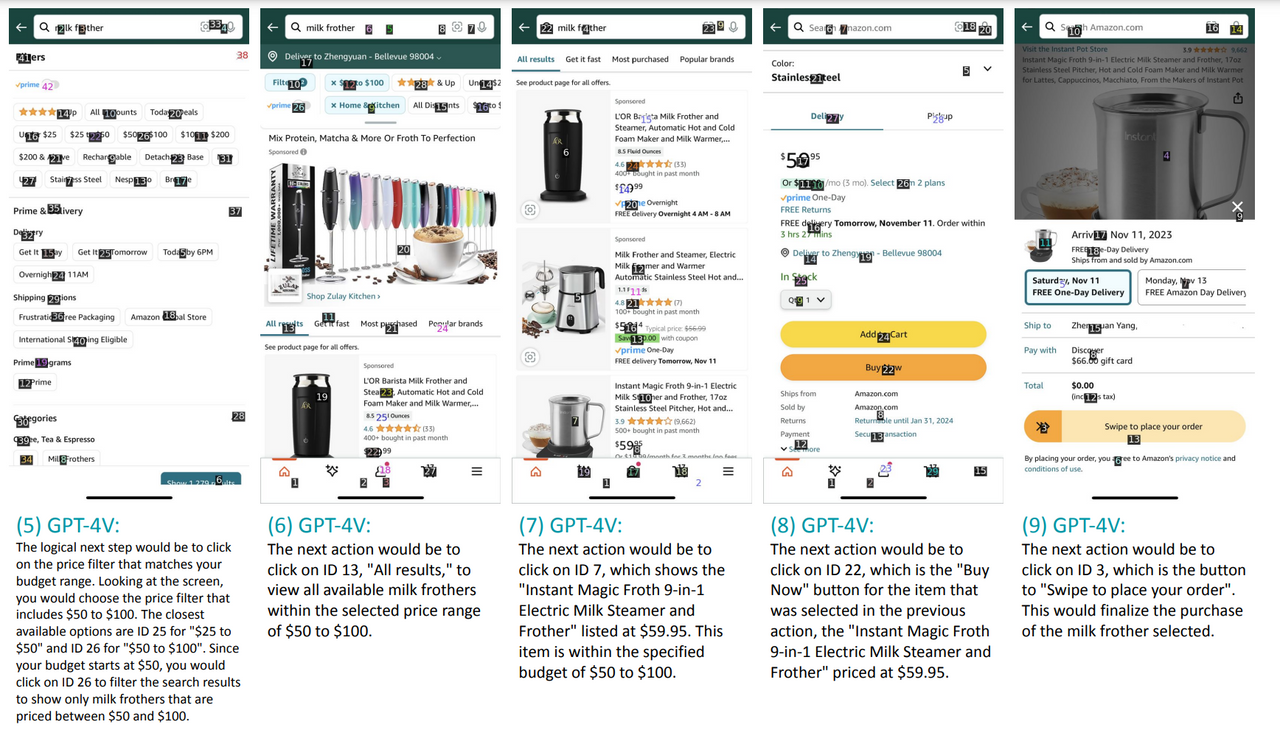
지시문 : "50달러에서 100달러 사이의 예산으로 우유 거품기를 구매해줘."
모든 단계에 적용되는 프롬프트: "당신은 아이폰을 조작하는 로봇이라고 상상해보세요. 50달러에서 100달러 사이의 예산으로 우유 거품기를 구매하라는 요청을 받았습니다. 당신의 이전 행동은: … 입니다. 아래는 화면에 숫자 ID가 추가된 것입니다. 화면에서 다음으로 클릭할 ID는 무엇입니까?"
전체 논문은 여기서 확인할 수 있습니다. https://arxiv.org/pdf/2311.07562.pdf
이런 자율 에이전트가 많이 등장해서 컴퓨터나 스마트폰을 조종하거나, 인간이 들어가기 힘든 위험한 지역 등에서 활동할 거라고 생각합니다. 저를 대신해서 일해줬으면 좋겠군요...ㅋㅋ