
유레카 - 인간 수준의 보상 설계 알고리즘
유레카 (Eureka)
강화 학습의 보상 설계를 GPT-4와 같은 LLM을 활용해서 최적화할 수 있는 모델.
복잡한 물리적 작업도 학습이 가능하다. 홈페이지에서는 펜 돌리기를 예로 보여준다.
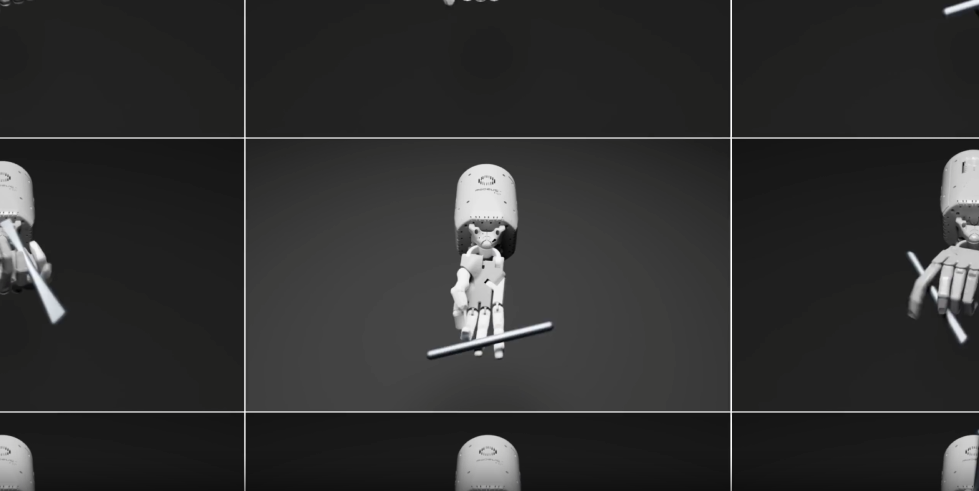
인간 전문가가 보상 설정을 하는 것보다 83%의 상황에서 더 나았다고 한다.
또한 RLHF에 있어 새로운 접근법을 활용해 인간의 인풋과 결합해 더 나은 결과를 낼 수 있다고 한다.
로봇 학습 등에 활용할 수 있을 것으로 보인다.
RL(Reinforcement Learning)에는 NVIDIA의 Issac Gym 시뮬레이터를 활용했는데 이 시뮬레이터는 현실을 1000배 가속화하여 시뮬레이션할 수 있다고 한다.
Eureka | Human-Level Reward Design via Coding Large Language Models
#인공지능#ai#강화학습#보상설계#로봇