LLaVA - GPT-4V에 비견되는 오픈소스 비전 멀티 모달 모델
멀티모달의 시각 분야 모델로 비전 인코더와 언어모델인 Vicuna를 결합했다. 그림을 입력하면 해당 그림이 무엇인지 텍스트로 기술할 수 있고 이를 바탕으로 다양한 일들을 수행할 수 있다.
주체는 위스콘신 메디슨 대학과 마이크로 소프트 리서치, 콜럼비아 대학교이다.
LLaVA - 공식 홈페이지
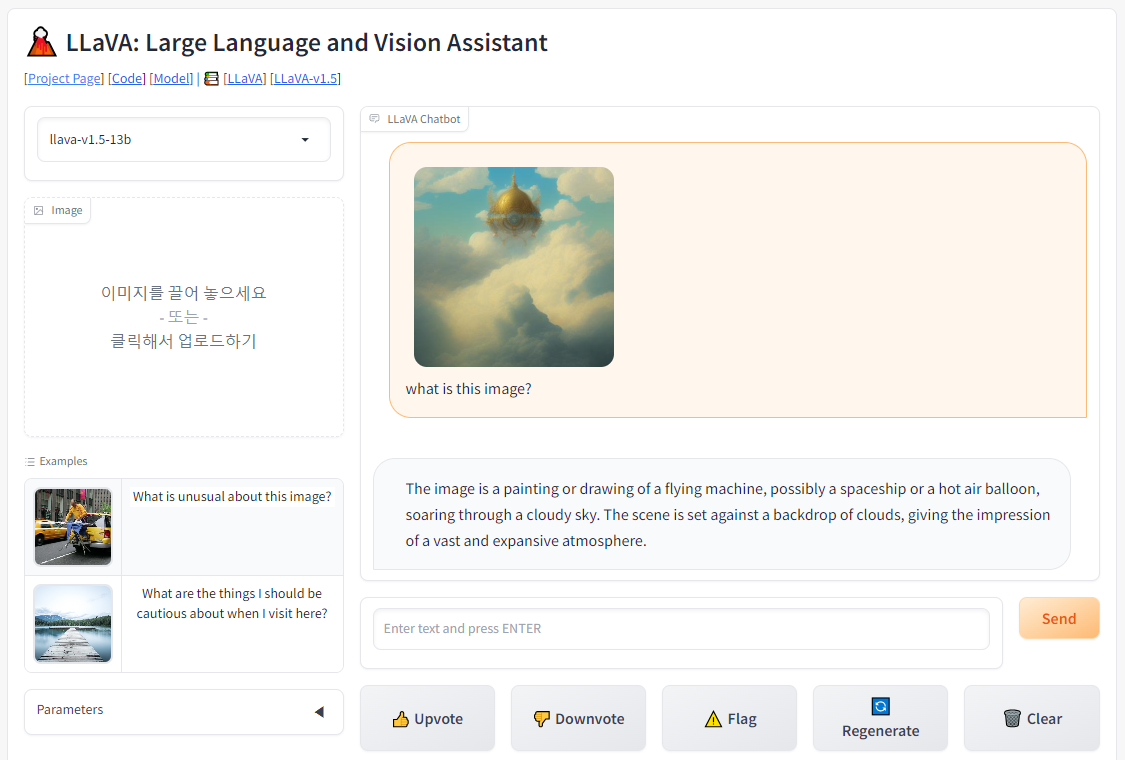
특정 이미지 인풋에 대한 텍스트를 생성한 모습. 이미지를 바탕으로 여러 작업을 수행할 수 있다.
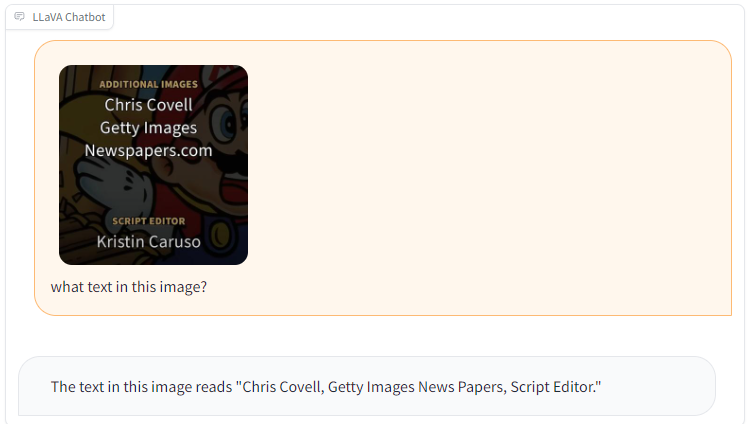
어느 정도의 OCR 기능도 수행할 수 있다. (완벽한 텍스트 추출은 안되지만 어느 정도의 텍스트를 바탕으로 작업을 수행할 수 있을 것으로 보인다.)
이미지 인코더는 CLIP ViT-L/14 비전 인코더를 수행하였고 언어 모델은 Vicuna (llama를 ShareGPT의 데이터로 파인튜닝한 모델)를 사용했다고 한다.
GPT-4와 비교하여 85.1%의 상대점수를 달성하여 멀티모달 환경에서의 Self instruction (자가 지시) 방법의 효과를 보여주는 모델이라고 한다.
GPT-4V에 비견되는 비주얼 분야의 오픈소스 모델로 보인다.
#인공지능#ai#멀티모달#비전 인코더#언어모델