LLM은 논리머신이다. 임베딩편
틸노트 AI 마스터 가이드임베딩 (embedding) - 논리머신
앞서 이야기했듯이 LLM은 수 많은 문장을 학습합니다. 이 과정에서 문장, 단어 등의 데이터를 벡터화해서 숫자로 표현합니다. ChatGPT와 같은 LLM에게 있어 데이터는 곧 숫자인 셈입니다. 이 벡터화된 텍스트는 벡터 공간에 표현할 수 있습니다. 이를 임베딩이라고 합니다.
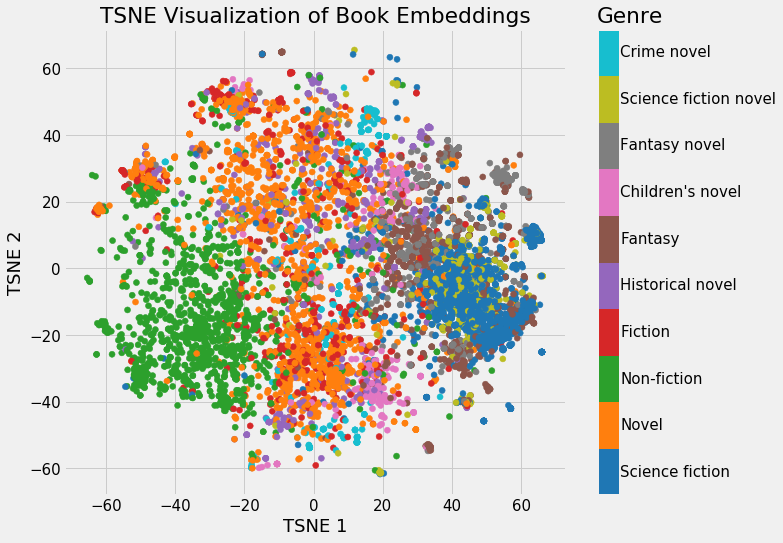
이미지 : 위키피디아에 있는 책들을 2차원의 공간에 장르별로 표시한 예시 [1]
위의 이미지는 저차원의 공간에 표현을 했지만 LLM은 좀 더 복잡한 다차원 상의 공간에 표현을 합니다. OpenAI의 대표적인 text-embedding-ada-002의 경우 1536차원에 저장합니다.
embedding : [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
] 이렇게 벡터의 값이 1536개 있다고 생각하면 됩니다.
어렵지는 않습니다. 의미가 비슷한 문장일 수록 위의 벡터값이 비슷해 진다고 생각하면 됩니다. 그렇기 때문에 두 벡터를 뺐을 때 값이 작으면 서로 가깝다고 판단합니다. LLM은 이러한 공간에서 각 요소의 멀고 가까움을 통해 논리를 이해하게 됩니다.
ChatGPT는 수 많은 논리나 패턴을 데이터로부터 학습한 논리 머신이라고 볼 수 있습니다. 수 많은 논리가 모델 내에 학습되어 있으므로 우리가 논리가 필요할 때 요청을 하면 해당 논리를 활용할 수 있습니다.

예를 들어 ChatGPT는 요약이나 번역의 논리를 가지고 있고 우리가 요약이나 번역을 요청하면 해당 작업을 수행할 수 있습니다. 그 밖에도 다양한 논리를 활용할 수 있습니다. 일종의 논리를 위한 계산기라고 비유하면 이해하기 쉽습니다.
이제 앞으로의 과정을 통해 어떤 일을 할 수 있는지 함께 알아나가 봅시다.
[1] : 이미지 출처 Neural Network Embeddings Explained