GPT-4의 라이벌 Claude 2 출시
Anthropic에서 새로운 인공지능 LLM 모델인 Claude 2를 공개했습니다. API와 새로운 베타 사이트인 claude.ai 에서 사용할 수 있습니다. 다만 claude.ai 는 현재는 미국과 영국에서만 서비스되고 있습니다. 이번 달 안으로 여러 국가로 확장한다고 합니다.
이전 모델에서 코딩, 수학, 추론 분야에서 향상이 있었다고 합니다. 측정된 성능은 다음과 같습니다.
Bar exam (미국 변호사 시험) 76.5%
GRE 읽기와 쓰기 시험에서 90번째 백분위 수
Codex HumanEval (파이썬 코딩 테스트) 에서 71.2%
GSM8k (초등학교 수학 문제) 에서 88.0% 기록
클로드의 장점은 바로 10만 토큰의 컨텍스트 윈도우를 가진다는 것입니다. 기술 문서나, 코드 또는 책을 그냥 입력해서 질문 등을 할 수 있습니다.
서비스 주소 : Claude (claude.ai)
현재 웹서비스는 한국에서 사용할 수 없지만 poe 에서 제한적인 무료로 사용할 수 있습니다.
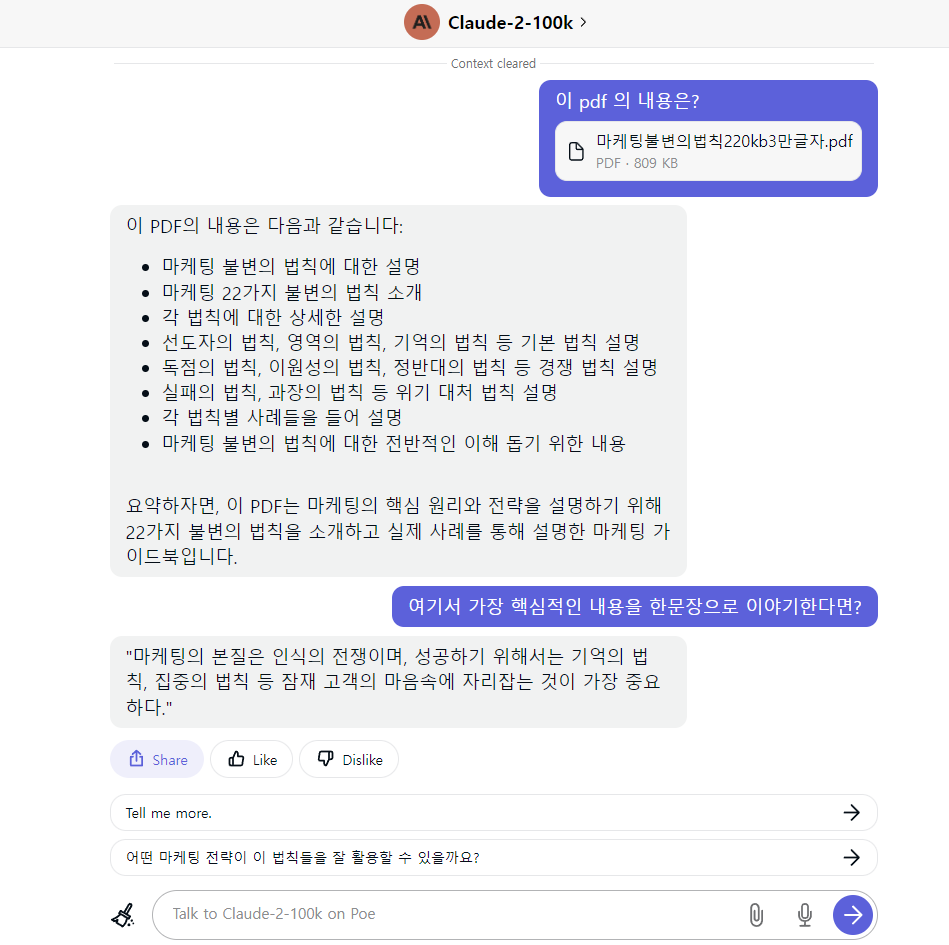
3만글자짜리 pdf를 올리고 질문을 하는 모습입니다.
이번에는 코드 파일을 올리고 개선 방법을 알려달라고 요청해 보겠습니다.
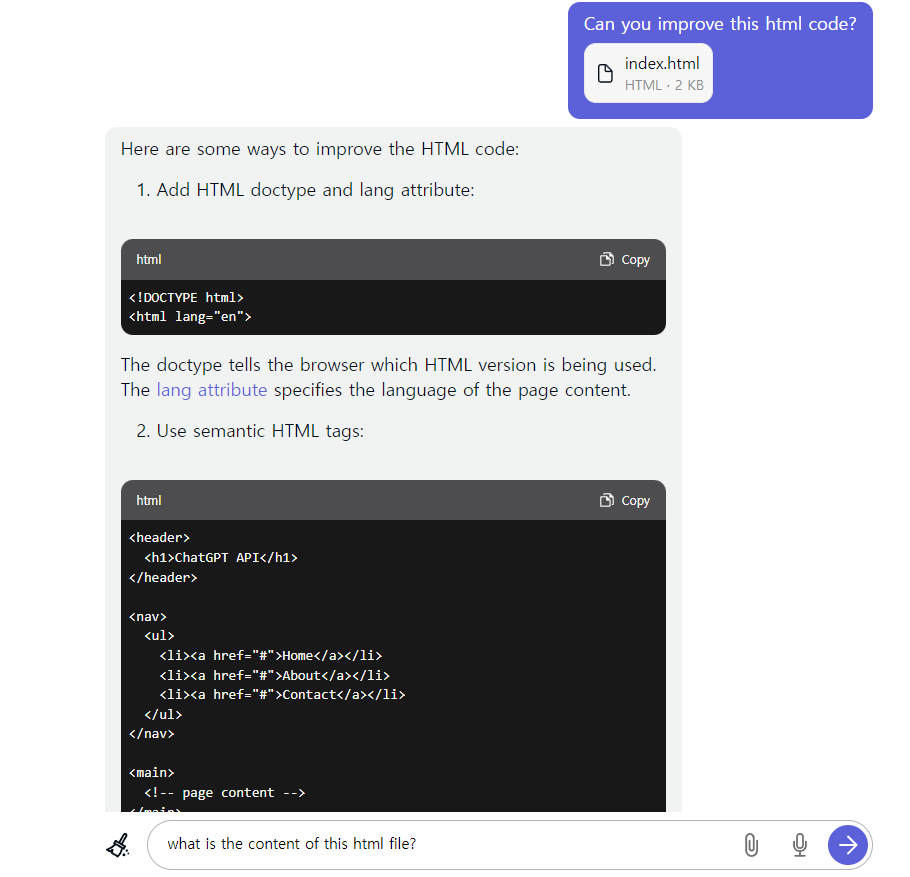
진짜 엄청난 conext window를 자랑하는 군요. 구글에서 왜 이렇게 많은 돈을 투자했는지 궁금했는데 이유를 알 수 있을 것 같습니다. 100k 컨텐스트 윈도우는 ChatGPT와 같은 라이벌 서비스에도 영향을 많이 끼칠 것 같습니다.
GPT-4와 비교해서는 다음과 같은 결과가 있었다고 합니다. (괄호 안에는 승자 표시)
GRE verbal: 165 vs 169 (GPT-4 승)
GRE writing: 5 vs 4 (Claude)
GRE quantitative: 154 vs 163 (GPT-4)
USMLE: ~67 vs ~85 (GPT-4)
Bar: 76.5 vs 75.7 (Claude)
HumanEval coding: 71.2% vs 67% (Claude 승) / GPT-3.5 는 48% 기록
GSM-8K grade-school math: 88% vs 92% (GPT-4)
출처 : https://twitter.com/DrJimFan/status/1678809539846770688
학습은 2023년 초반까지 되었다고 합니다.
그리고 이전 버전인 1.3에 비해 해로운 응답을 거르는 능력이 2배 정도 향상되었다고 합니다.
10%가 영어가 아닌 언어로 학습되었다고 합니다. 그래서 그런지 한글도 잘 작동합니다.
모델 카드를 보니 MMLU에서는 78.5% 성능을 기록했네요. GPT-4의 경우 86.4%를 기록했습니다. (Papers with Code - MMLU Benchmark (Multi-task Language Understanding) 물론 측정 방법에 따라 차이가 있을 수 도 있는데 그래도 꽤 근접해가지 않나 생각해 봅니다.