PHI-1 : 높은 품질의 파이썬 코드 모델 - 작은 인공지능 모델의 등장
얼마 전 마이크로소프트 리서치에서 Textbooks Are All You Need 라는 논문을 발표했습니다.
여기서 발표한 모델은 phi-1 인데요. 파이썬 코드를 학습한 코드를 위한 LLM 입니다. 크기는 작은데요. 1.3B 파라미터를 가지고 있습니다. 참고로 GPT-3.5가 175B 입니다. 그런데 중요한 것은 교과서 수준의 텍스트 (text book quality) 의 데이터로 학습을 시켰다는 것입니다. 그리고 이 모델이 HumanEval에서 55.5%의 성적을 기록했다고 합니다. HumanEval은 대형 언어 모델의 코딩 능력을 측정할 수 있는 테스트 세트입니다. 또 이보다 작은 350M의 파라미터를 가지고 있는 phi-1-small은 HumanEval에서 45%를 기록했다고 합니다.
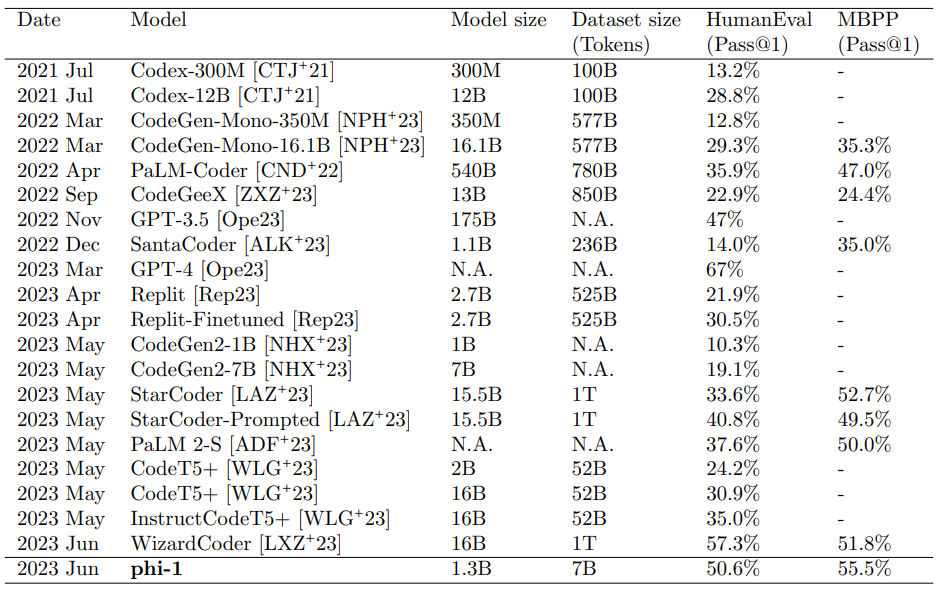
참고로 훈련 시간은 8대의 A-100 GPU로 4일이 걸렸다고 하네요.
높은 품질의 데이터
높은 품질의 데이터를 바탕으로 학습하기 위해서 파이-1이 사용한 데이터셋입니다.
The Stack 과 StackOverflow의 코드 언어 데이터셋. GPT-4의 다음과 같은 프롬프트로 일부 주석 버전을 선별해서 만들었다고 하네요. "determine its educational value for a student whose goal is to learn basic coding concepts" (기본 코딩을 배우려는 학생을 위해 교육적인 가치를 결정하세요.) 그리고 이 주석 버전의 작은 데이터세트의 임베딩을 나머지 데이터들의 가치를 결정하는데 사용했습니다. (~6B 토큰)
합성 텍스트북 : GPT-3.5 사용해서 만든 파이썬 교과서 (<1B 토큰)
적은 양의 연습 문제 (exercise dataset) : 파이썬 문제와 풀이 (~180M) 토큰
CodeTextbook에서 phi-1-base를 만들고 CodeExercise 데이터셋으로 파인튜닝해서 phi-1이 나왔다고 합니다. 이 파인튜닝에서 엄청난 성능의 향상이 있었다고 하네요.
높은 품질의 데이터를 사용하면 적은 수의 파라미터를 가진 모델로도 성과를 낼 수 있다는 것을 알려주는 일인것 같습니다. 그리고 높은 품질의 데이터를 선별하는데 GPT-4를 사용한 것도 인상깊습니다.
높은 품질의 데이터로 학습 + 적절한 파인튜닝으로 특정 도메인에 특화된 작은 인공지능 모델들이 등장할 수 있음을 알리는 일인 것 같습니다.
키워드만 입력하면 나만의 학습 노트가 완성돼요.
책이나 강의 없이, AI로 위키 노트를 바로 만들어서 읽으세요.
콘텐츠를 만들 때도 사용해 보세요. AI가 리서치, 정리, 이미지까지 초안을 바로 만들어 드려요.