Hugging Face api 사용법 - ChatGPT 외에 다양한 인공지능 모델 사용하기
허깅 페이스에서 다양한 인공지능 모델들을 사용해 볼 수 있습니다. 그런데 허깅 페이스 API (Inference API) 를 사용하면 이곳에 있는 다양한 모델들의 API를 무료로 사용해 볼 수 있습니다.
물론 단순히 모델이 어떻게 작동하는지 보려면 Hosted inference API나 공개된 Spaces에서 사용해 보면 됩니다.
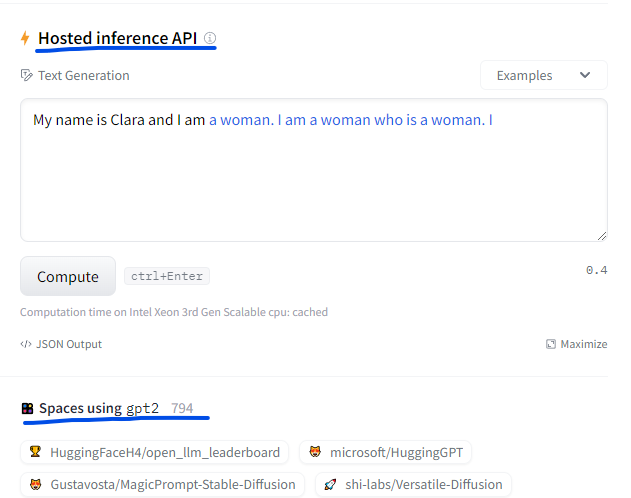
모델 상세 페이지에 있는 Hosted inference API와 Spaces
또 하나의 제약 사항은 모델 용량이 10G가 넘으면 무료 API로는 사용할 수 없습니다.
그렇지만 메모리 사용량이 많지 않은 모델들은 API를 코드로 사용하고 테스트해 볼 수 있습니다. 그럼 한번 사용법을 알아보도록 할까요?
API Key 발급받기
먼저 hugging face에 로그인 한 후 settings - Access Tokens - New Token을 눌러 Access Token을 발급받습니다. role은 read로 해주세요.
이걸 활용해서 inference api를 사용할 수 있습니다.
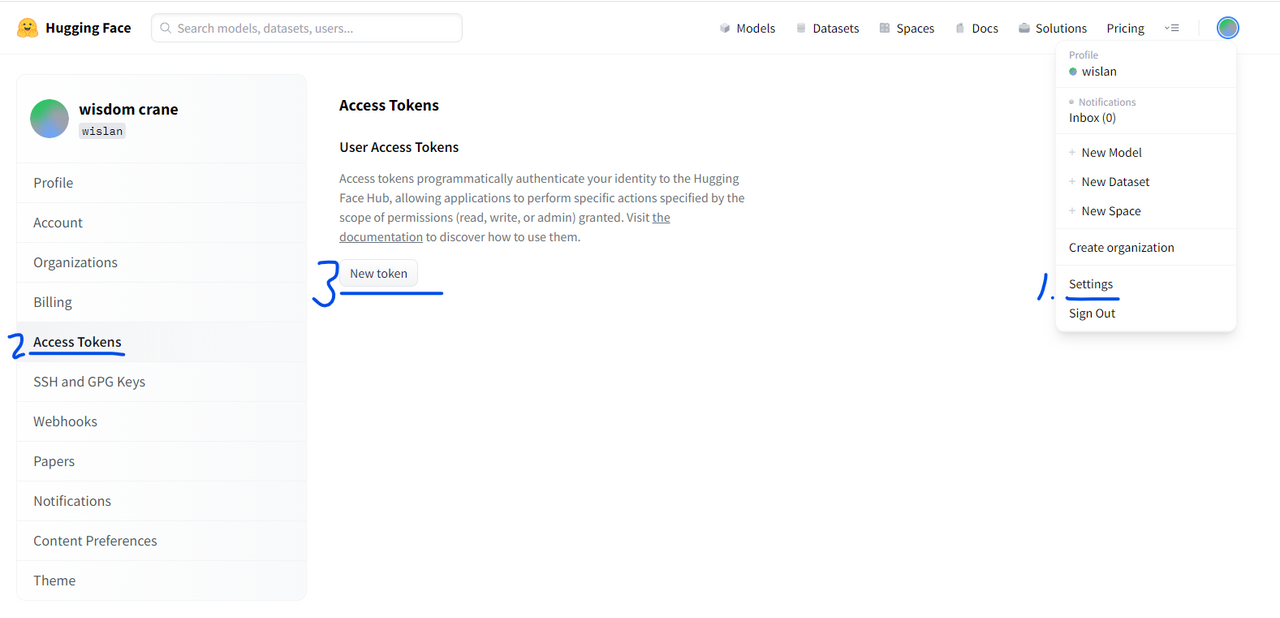
Inference API 사용하기
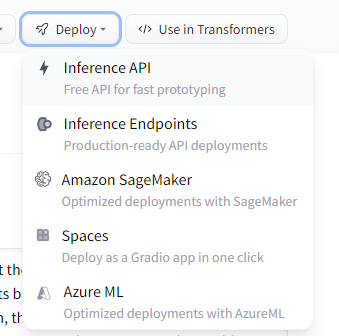
허깅 페이스의 모델에서 사용해 보고 싶은 모델을 선택합니다.
저는 Summarization에서 distilbart-cnn-12-6 을 선택했습니다.
그리고 우측 상단의 Deploy를 누른 후 Inference API를 선택합니다.
이렇게 하면 API 코드가 나옵니다. Show API token을 눌러 내 키가 나오게 해서 복사합니다. (이 API token은 비밀키이므로 외부에 노출이 되어서는 안됩니다.)
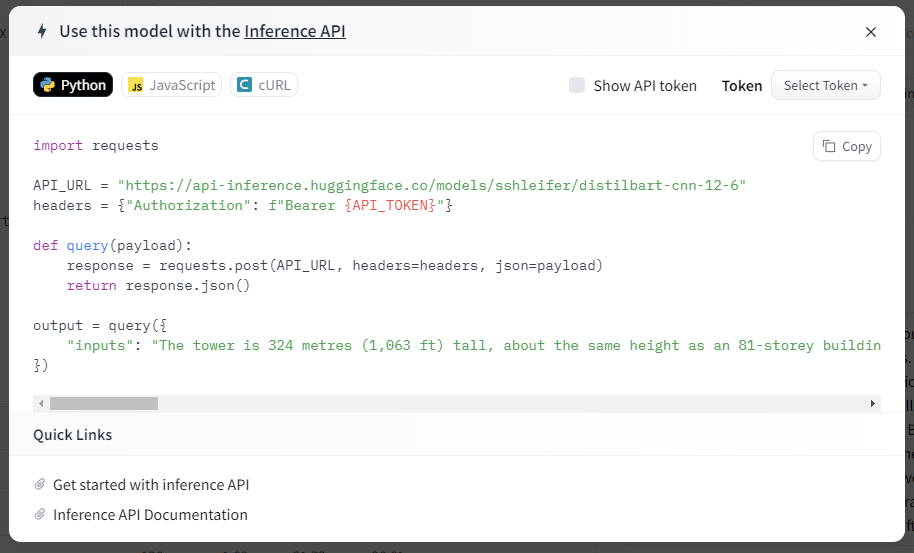
파이썬, 자바스크립트, cURL 의 모드 중 선택할 수 있습니다. 저는 파이썬 코드로 했습니다.
이 코드를 복사해서 파이썬 파일을 만든 후 이를 실행하면 됩니다.
저는 hf.py 파일을 만들어서 다음과 같이 작성했습니다.
import requests
API_URL = "https://api-inference.huggingface.co/models/sshleifer/distilbart-cnn-12-6"
headers = {"Authorization": "Bearer YOUR_API_TOKEN"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query(
{
"inputs": "The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct.",
}
)
print(output)YOUR_API_TOKEN 부분에는 여러분의 키를 입력하셔야 합니다.
python hf.py 를 입력해서 파일을 실행하고 출력한 내용입니다.

약 600 글자 이상의 텍스트가 300글자 정도로 요약이 된 것을 알 수 있습니다.
모델 크기 제약
아쉽게도 모델 크기가 큰 모델은 사용할 수 없습니다. 예를 들어 llama-7b를 사용했을 때 나오는 메시지입니다.
{'error': 'The model huggyllama/llama-7b is too large to be loaded automatically (13GB > 10GB). For commercial use please use PRO spaces (https://huggingface.co/spaces) or Inference Endpoints (https://huggingface.co/inference-endpoints).'}
여기에서 13GB는 모델의 크기로 추정됩니다.

실제로 llama 모델의 사이즈는 약 13GB입니다.
참고로 필요한 GPU 메모리는 full precision (float 32) 으로 계산하려면 모델 파라미터 수 * 4를 하면 된다고 합니다. (7B이면 28GB의 VRAM 필요) 반대로 half precision (16bit) 은 * 2를 하면 되고 4bit 버전에서는 파라미터 수가 필요한 GPU 용량이 됩니다. 그래서 4bit 버전은 7B 이면 7GB의 VRAM 용량이 필요합니다.
참고 : LLaMA 7B GPU Memory Requirement - 🤗Transformers - Hugging Face Forums
키워드만 입력하면 나만의 학습 노트가 완성돼요.
책이나 강의 없이, AI로 위키 노트를 바로 만들어서 읽으세요.
콘텐츠를 만들 때도 사용해 보세요. AI가 리서치, 정리, 이미지까지 초안을 바로 만들어 드려요.