
인공지능에서 트랜스포머 공부 - 병렬로 한 번에 처리하자
인공지능에서 Transformer 란?
단어와 같은 순차 데이터 내의 관계를 추적해 맥락과 의미를 학습하는 신경망 아키텍처이다.
전에는 순차 데이터의 관계를 파악할 때 RNN(순환신경망)과 CNN(합성곱 신경망)으로 순차적으로 처리할 수 밖에 없었으나 트랜스포머가 등장 한 후 병렬로 한 번에 처리할 수 있게 되었다.
attention is all you need 라는 구글의 논문에서 2017년 발표되었다.
이를 통해 대규모 데이터셋에 대한 학습을 효율적으로 진행할 수 있었다. 이는 GPT (Generative Pre-trained Transformer)와 BERT (Bidirectional Encoder Representations from Transformers)와 같은 최근 인기 있는 모델의 기반이 되었다.
현재 인공지능의 열풍은 이 트랜스포머 기술을 기반으로 발생하고 있는 것이다.
트랜스포머는 주요 구성요소를 살펴 보자. gpt의 힘을 빌려 봤다.
셀프 어텐션(Self-Attention): 셀프 어텐션은 입력 시퀀스의 각 단어가 다른 단어와 얼마나 관련이 있는지를 계산하는 메커니즘입니다. 이를 통해 문맥 이해와 문장 내 관계 파악이 가능해집니다. (행렬 연산 등을 사용한다. 각 문장이 어느 정도 연관이 있는지 한 번에 계산.)

포지션 와이즈 피드 포워드 네트워크(Position-wise Feed-Forward Networks): 이 구성 요소는 각 위치의 단어에 독립적으로 적용되는 완전 연결된 피드 포워드 네트워크입니다. 이를 통해 입력 단어의 특성을 추출하고 변환합니다.
포지션 인코딩(Position Encoding): 트랜스포머는 순차적인 구조를 가지지 않기 때문에, 입력 시퀀스의 단어 위치 정보를 포함시키기 위해 포지션 인코딩이 사용됩니다. 이를 통해 모델이 문장 내 단어의 순서를 인식할 수 있습니다.
인코더-디코더 구조(Encoder-Decoder Structure): 트랜스포머는 인코더와 디코더 두 부분으로 구성됩니다. 인코더는 입력 시퀀스를 연속적인 고차원 표현으로 변환하며, 디코더는 이를 통해 출력 시퀀스를 생성합니다. 인코더와 디코더는 여러 개의 층으로 구성될 수 있습니다.
트랜스포머 아키텍처는 다음과 같다.
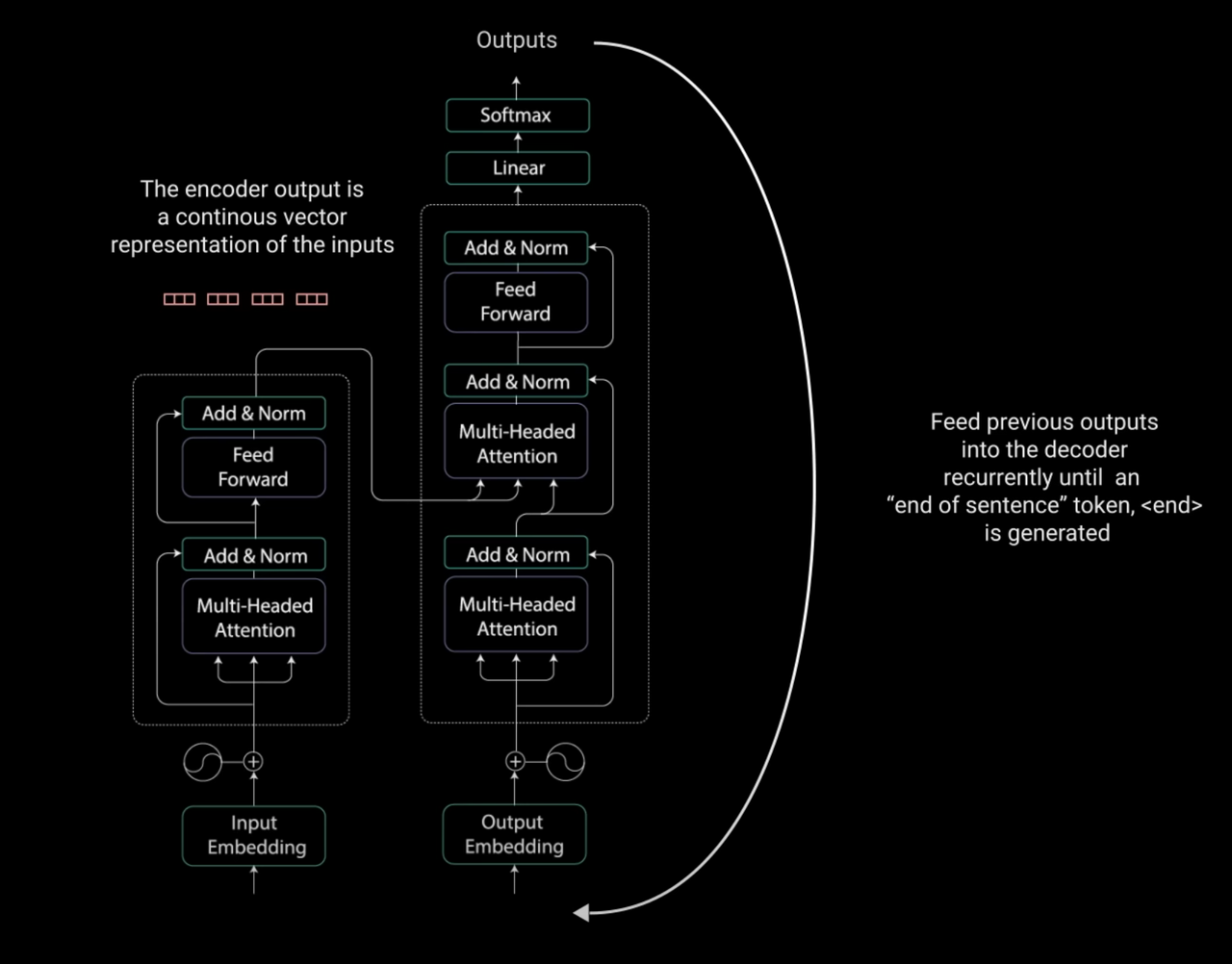
인코더는 입력값의 벡터 값을 출력하고 이는 이전에 나왔던 아웃풋과 함께 디코더에 들어간다.
이미지 출처 (유튜브) : Illustrated Guide to Transformers Neural Network: A step by step explanation
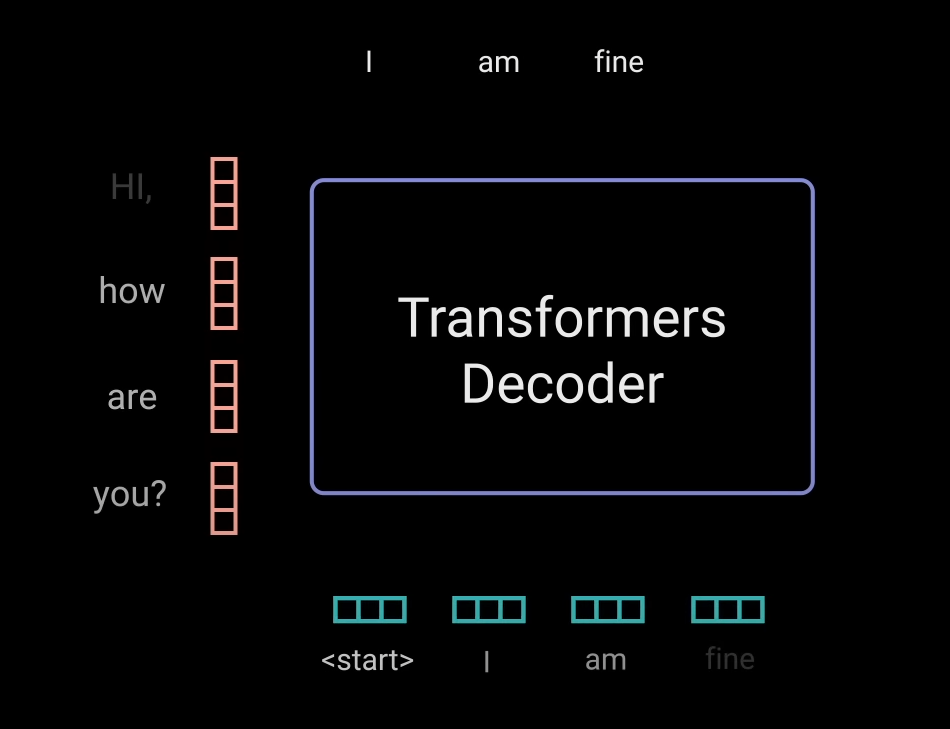
디코더에서도 어텐션을 포함한 여러 과정을 거쳐 아웃풋의 다음 토큰을 내놓게 된다.
위의 내용은 내가 그냥 트랜스포머를 이해하고 싶어서 정리해 본 내용이고 자세한 내용을 알고 싶다면 위의 유튜브를 참고하자.
이런 트랜스포머 기술을 통해 기존 RNN의 순차적 처리나 이전 맥락의 기억 한계를 극복하고 입력 시퀀스 전체에서 정보를 추출할 수 있어 예측 능력을 향상시켰다. 이를 통해 NLP(natural language processing) 분야는 눈부신 성과를 달성하고 있다.